General Structure of Client Applications
This is a good time to discuss, in general terms, how a client application interacts with a PostgreSQL database. All the client APIs have a common structure, but the details vary greatly from language to language.
Figure 5.1 illustrates the basic flow of a client's interaction with a server.
Figure 5.1. Client/server interaction.
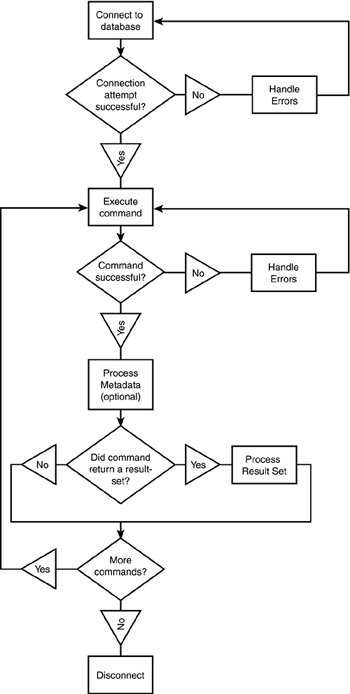
An application begins interacting with a PostgreSQL database by establishing a connection.
Because PostgreSQL is a client/server database, some sort of connection must exist between a client application and a database server. In the case of PostgreSQL, client/server communication takes the form of a network link. If the client and server are on different systems, the network link is a TCP/IP socket. If the client and server are on the same system, the network link is either a Unix-domain socket or a TCP/IP connection. A Unix-domain socket is a link that exists entirely within a single host?the network is a logical network (rather than a physical network) within the OS kernel.
Regardless of whether you are connecting to a local server or a remote server, the API uses a set of properties to establish the connection. Connection properties are used to identify the server (a network port number and host address), the specific database that you want to connect to, your user ID (and password if required), and various debugging and logging options. Each API allows you to explicitly specify connection properties, but you can also use default values for some (or all) of the properties. I'll cover the defaulting mechanisms used by each API in later chapters.
After a server connection has been established, the API gives you a handle. A handle is nothing more than a chunk of data that you get from the API and that you give back to the API when you want to send or receive data over the connection. The exact form of a handle varies depending on the language that you are using (or more precisely, the data type of a handle varies with the API that you use). For example, in libpq (the C API), a handle is a void pointer?you can't do anything with a void pointer except to give it back to the API. In the case of libpq++ and JDBC, a handle is embedded within a class.
After you obtain a connection handle from the API, you can use that handle to interact with the database. Typically, a client will want to execute SQL queries and process results. Each API provides a set of functions that will send a SQL command to the database. In the simplest case, you use a single function; more complex applications (and APIs) can separate command execution into two phases. The first phase sends the command to the server (for error checking and query planning) and the second phase actually carries out the command; you can repeat the execution phase as many times as you like. The advantage to a two-phase execution method is performance. You can parse and plan a command once and execute it many times, rather than parsing and planning every time you execute the command. Two-phase execution can also simplify your code by factoring the work required to generate a command into a separate function: One function can generate a command and a separate function can execute the command.
Two-Phase ExecutionEven though some APIs support a two-phase execution model, the underlying PostgreSQL server does not. You will not gain any performance improvements using two-phase execution with PostgreSQL, but you will if your application uses a PostgreSQL-compatible API to communicate with other databases. If your client application uses a portable API (meaning an API that can communicate with database servers other than PostgreSQL), you might want to use a two-phase strategy so that you can realize a performance gain when your client application is connected to some other database. |
After you use an API to send a command to the server, you get back three types of results. The first result that comes back from the server is an indication of success or failure?every command that you send to the server will either fail or succeed. If your command fails, you can use the API to retrieve an error code and a translation of that code into some form of textual message.
If the server tells you that the command executed successfully, you can retrieve the next type of result: metadata. Metadata is data about data. Specifically, metadata is information about the results of the command that you just executed. If you already know the format of the result set, you can ignore the metadata.
When you execute a command such as INSERT, UPDATE, or DELETE, the metadata returned by the server is simply a count of the number of rows affected by the command. Some commands return no metadata. For example, when you execute a CREATE TABLE command, the only results that you get from the server are success or failure (and an error code if the command fails). When you execute a SELECT command, the metadata is more complex. Remember that a SELECT statement can return a set of zero or more rows, each containing one or more columns. This is called the result set. The metadata for a SELECT statement describes each of the columns in the result set.
Field Versus Column in Result SetsWhen discussing a result set, the PostgreSQL documentation makes a distinction between a field and a column. A column comes directly from a table (or a view). A field is the result of a computation in the SELECT statement. For example, if you execute the command SELECT customer_name, customer_balance * 1.05 FROM customers, customer_name is a column in the result set and customer_balance * 1.05 is a field in the result set. The difference between a field and a column is mostly irrelevant and can be ignored; just be aware that the documentation uses two different words for the same meaning. |
When the server sends result set metadata, it returns the number of rows in the result set and the number of fields. For each field in the result set, the metadata includes the field name, data type information, and the size of the field (on the server).
I should mention here that most client applications don't really need to deal with all the metadata returned by the server. In general, when you write an application you already know the structure of your data. You'll often need to know how many rows were returned by a given query, but the other metadata is most useful when you are processing ad-hoc commands?commands that are not known to you at the time you are writing your application.
After you process the metadata (if you need to), your application will usually process all the rows in the result set. If you execute a SELECT statement, the result set will include all the rows that meet the constraints of the WHERE clause (if any). In some circumstances, you will find it more convenient to DECLARE a cursor for the SELECT statement and then execute multiple FETCH statements. When you execute the DECLARE statement, you won't get metadata. However, as you execute FETCH commands, you are constructing a new result set for each FETCH and the server has to send metadata describing the resulting fields?that can be expensive.
After you have finished processing the result set, you can execute more commands, or you can disconnect from the server.







