Multibyte Character Sets
Most programmers are accustomed to working with single-byte character sets. In the U.S., we like to pretend that ASCII is the only meaningful mapping between numbers and characters. This is not the case. Standard organizations such as ANSI (American National Standards Institute) and the ISO (International Standards Organization) have defined many different encodings that associate a unique number with each character in a given character set. Theoretically, a single-byte character set can encode 256 different characters. In practice, however, most single-byte character sets are limited to about 96 visible characters. The range of values is cut in half by the fact that the most-significant bit is considered off-limits when representing characters. The most-significant bit is often used as a parity bit and occasionally as an end-of-string marker. Of the remaining 127 encodings, many are used to represent control characters (such as tab, new-line, carriage return, and so on). By the time you add punctuation and numeric characters, the remaining 96 values start feeling a bit cramped.
Single-byte character sets work well for languages with a relatively small number of characters. Eventually, most of us must make the jump to multibyte encodings. Adding a second byte dramatically increases the number of characters that you can represent. A single-byte character set can encode 256 values; a double-byte set can encode 65536 characters. Multibyte character sets are required for some languages, particularly languages used in East Asia. Again, standards organizations have defined many multibyte encoding standards.
The Unicode Consortium was formed with the goal of providing a single encoding for all character sets. The consortium published its first proposed standard in 1991 ("The Unicode Standard, Version 1.0"). A two-byte number can represent most of the Unicode encoding values. Some characters require more than two bytes. In practice, many Unicode characters require a single byte.
I've always found that the various forms of the Unicode encoding standard were difficult to understand. Let me try to explain the problem (and Unicode's solution) with an analogy.
Suppose you grabbed a random byte from somewhere on the hard drive in your computer. Let's say that the byte you select has a value of 48. What does that byte mean? It might mean the number of states in the contiguous United States. It might mean the character '0' in the ASCII character set. It could represent 17 more than the number of flavors you can get at Baskin-Robbins. Let's assume that this byte represents the current temperature. Is that 48° in the Centigrade, Fahrenheit, Kelvin, Réaumur, or Rankine scale? The distinction is important: 48° is a little chilly in Fahrenheit, but mighty toasty in Centigrade.
There are two levels of encoding involved here. The lowest level of encoding tells us that 48 represents a temperature value. The higher level tells us that the temperature is expressed in degrees Fahrenheit. We have to know both encodings before we can understand the meaning of the byte. If we don't know the encoding(s), 48 is just data. After we understand the encodings, 48 becomes information.
Unicode is an encoding system that assigns a unique number to each character. Which characters are included in the Unicode Standard? Version 3.0 of the Unicode Standard provides definitions for 49,194 characters. Version 3.1 added 44,946 character mappings, and Version 3.2 added an additional 1,016 for a total of 95,156 characters. I'd say that the chances are very high that any character you need is defined in the Unicode Standard.
Just like the temperature encodings I mentioned earlier, there are two levels of encoding in the Unicode Standard.
At the most fundamental level, Unicode assigns a unique number, called a code point, to each character. For example, the Latin capital 'A' is assigned the code point 65. The Cyrillic (Russian) capital de ('?') is assigned the value 0414. The Unicode Standard suggests that we write these values using the form 'U+xxxx' where 'xxxx' is the code point expressed in hexadecimal notation. So, we should write U+0041 and U+0414 to indicate the Unicode mappings for 'A' and '?'. The mapping from characters to numbers is called the Universal Character Set, or UCS.
At the next level, each code point is represented in one of several UCS transformation formats (UTF). The most commonly seen UTF is UTF-8[2]. The UTF-8 scheme is a variable-width encoding form, meaning that some code points are represented by a single byte; and others represented by two, three, or four bytes. UTF-8 divides the Unicode code point space into four ranges, with each range requiring a different number of bytes as shown in Table 20.3.
[2] Other UTF encodings are UTF-16BE (variable-width, 16 bit, big-endian), UTF-16LE (variable-width, 16 bit, little-endian), UTF-32BE, and UTF-32LE.
|
Low Value |
High Value |
Storage Size |
Sample Character |
UTF8-Encoding |
|---|---|---|---|---|
|
U+0000 |
U+007F |
1 byte |
A(U+0041) 0(U+0030) |
0x41 0x30 |
|
U+0080 |
U+07FF |
2 bytes |
©(U+00A9) æ(U+00E6) |
0xC2 0xA9 0xC3 0xA6 |
|
U+0800 |
U+FFFF |
3 bytes |
|
0xE0 0x86 0xAC 0xE2 0x82 0xAC |
|
U+10000 |
U+10FFFF |
4 bytes |
S(U+1D6F4) |
0xF0 0x8E 0xA3 0xA0 0xF0 0x9D 0x9B 0xB4 |
The Unicode mappings for the first 127 code points are identical to the mappings for the ASCII character set. The ASCII code point for 'A' is 0x41, the same code point is used to represent 'A' in Unicode. The UTF-8 encodings for values between 0 and 127 are the values 0 through 127. The net effect of these two rules is that all ASCII characters require a single byte in the UTF-8 encoding scheme and the ASCII characters map directly into the same Unicode code points. In other words, an ASCII string is identical to the UTF-8 string containing the same characters.
PostgreSQL understands how to store and manipulate characters (and strings) expressed in Unicode/UTF-8. PostgreSQL can also work with multibyte encodings other than Unicode/UTF-8. In fact, PostgreSQL understands single-byte encodings other than ASCII.
Encodings Supported by PostgreSQL
PostgreSQL does not store a list of valid encodings in a table, but you can create such a table. Listing 20.1 shows a PL/pgSQL function that creates a temporary table (encodings) that holds the names of all encoding schemes supported by our server:
Listing 20.1 get_encodings.sql
1 -- 2 -- Filename: get_encodings.sql 3 -- 4 5 CREATE OR REPLACE FUNCTION get_encodings() RETURNS INTEGER AS 6 ' 7 DECLARE 8 enc INTEGER := 0; 9 name VARCHAR; 10 BEGIN 11 CREATE TEMP TABLE encodings ( enc_code int, enc_name text ); 12 LOOP 13 SELECT INTO name pg_encoding_to_char( enc ); 14 15 IF( name = '''' ) THEN 16 EXIT; 17 ELSE 18 INSERT INTO encodings VALUES( enc, name ); 19 END IF; 20 21 enc := enc + 1; 22 END LOOP; 23 24 RETURN enc; 25 END; 26 27 ' LANGUAGE 'plpgsql';
get_encodings() assumes that encoding numbers start at zero and that there are no gaps. This may not be a valid assumption in future versions of PostgreSQL. We use the pg_encoding_to_char() built-in function to translate an encoding number into an encoding name. If the encoding number is invalid, pg_encoding_to_char() returns an empty string.
When you call get_encodings(), it will return the number of rows written to the encodings table.
movies=# select get_encodings();
get_encodings
---------------
27
(1 row)
movies=# select * from encodings;
enc_code | enc_name
----------+---------------
0 | SQL_ASCII
1 | EUC_JP
2 | EUC_CN
3 | EUC_KR
4 | EUC_TW
5 | UNICODE
6 | MULE_INTERNAL
7 | LATIN1
8 | LATIN2
9 | LATIN3
10 | LATIN4
11 | LATIN5
12 | LATIN6
13 | LATIN7
14 | LATIN8
15 | LATIN9
16 | LATIN10
17 | KOI8
18 | WIN
19 | ALT
20 | ISO_8859_5
21 | ISO_8859_6
22 | ISO_8859_7
23 | ISO_8859_8
24 | SJIS
25 | BIG5
26 | WIN1250
(27 rows)
Some of these encoding schemes use single-byte code points: SQL_ASCII, LATIN*, KOI8, WIN, ALT, ISO-8859*. Table 20.4 lists the encodings supported by PostgreSQL version 7.2.1.
|
Encoding |
Defined By |
Single or Multibyte |
Languages Supported |
|---|---|---|---|
|
SQL_ASCII |
ASCII |
S |
|
|
EUC_JP |
JIS X 0201-1997 |
M |
Japanese |
|
EUC_CN |
RFC 1922 |
M |
Chinese |
|
EUC_KR |
RFC 1557 |
M |
Korean |
|
EUC_TW |
CNS 11643-1992 |
M |
Traditional Chinese |
|
UNICODE |
Unicode Consortium |
M |
All scripts |
|
MULE_INTERNAL |
CNS 116643-1992 |
||
|
LATIN1 |
ISO-8859-1 |
S |
Western Europe |
|
LATIN2 |
ISO-8859-2 |
S |
Eastern Europe |
|
LATIN3 |
ISO-8859-3 |
S |
Southern Europe |
|
LATIN4 |
ISO-8859-4 |
S |
Northern Europe |
|
LATIN5 |
ISO-8859-9 |
S |
Turkish |
|
LATIN6 |
ISO-8859-10 |
S |
Nordic |
|
LATIN7 |
ISO-8859-13 |
S |
Baltic Rim |
|
LATIN8 |
ISO-8859-14 |
S |
Celtic |
|
LATIN9 |
ISO-8859-15 |
S |
Similar to LATIN1, replaces some characters with French and Finnish characters, adds Euro |
|
LATIN10 |
ISO-8859-16 |
S |
Romanian |
|
KOI8 |
RFC 1489 |
S |
Cyrillic |
|
WIN |
Windows 1251 |
S |
Cyrillic |
|
ALT |
IBM866 |
S |
Cyrillic |
|
ISO_8859_5 |
ISO-8859-5 |
S |
Cyrillic |
|
ISO_8859_6 |
ISO-8859-6 |
S |
Arabic |
|
ISO_8859_7 |
ISO-8859-7 |
S |
Greek |
|
ISO_8859_8 |
ISO-8859-8 |
S |
Hebrew |
|
SJIS |
JIS X 0202-1991 |
M |
Japanese |
|
BIG5 |
RF 1922 |
M |
Chinese for Taiwan |
|
WIN1250 |
Windows 1251 |
S |
Eastern Europe |
I've spent a lot of time talking about Unicode. As you can see from Table 20.4, you can use other encodings with PostgreSQL. Unicode has one important advantage over other encoding schemes. A character in any other encoding system can be translated into Unicode and translated back into the original encoding system.
You can use Unicode as a pivot to translate between other encodings. For example, if you want to translate common characters from ISO-646-DE (German) into ISO-646-DK (Danish), you can first convert all characters into Unicode (all ISO-646-DE characters will map into Unicode) and then map from Unicode back to ISO-646-DK. Some German characters will not translate into Danish. For example, the DE+0040 character ('§') will map to Unicode U+00A7. There is no '§' character in the ISO-646-DK character set, so this character would be lost in the translation (not dropped, just mapped into a value that means "no translation").
If you don't use Unicode to translate between character sets, you'll have to define translation tables for every language pair that you need.
If you need to support more than one character set at your site, I would strongly encourage you to encode your data in Unicode. However, you should be aware that there is a performance cost associated with multibyte character sets. It takes more time to deal with two or three bytes than it does a single byte. Of course, your data may consume more space if stored in a multibyte character set.
Enabling Multibyte Support
When you build PostgreSQL from source code, multibyte support is disabled by default. Unicode is a multibyte character set?if you want to use Unicode, you need to enable multibyte support. Starting with PostgreSQL release 7.3, multibyte support is enabled by default. If you are using a version earlier than 7.3, you enable multibyte support by including the --enable-multibyte option when you run configure:
./configure --enable-multibyte
If you did not compile your own copy of PostgreSQL, the easiest way to determine whether it was compiled with multibyte support is to invoke psql, as follows:
$ psql -l
List of databases
Name | Owner | Encoding
-------------+-------+-----------
movies | bruce | SQL_ASCII
secondbooks | bruce | UNICODE
The -l flag lists all databases in a cluster. If you see three columns, multibyte support is enabled. If the Encoding column is missing, you don't have multibyte support.
Selecting an Encoding
There are four ways to select the encoding that you want to use for a particular database.
When you create a database using the createdb utility or the CREATE DATABASE command, you can choose an encoding for the new database. The following four commands are equivalent:
$ createdb -E latin5 my_turkish_db $ createdb --encoding=latin5 my_turkish_db movies=# CREATE DATABASE my_turkish_db WITH ENCODING 'LATIN5'; movies=# CREATE DATABASE my_turkish_db WITH ENCODING 11;
If you don't specify an encoding with createdb (or CREATE DATABASE), the cluster's default encoding is used. You specify the default encoding for a cluster when you create the cluster using the initdb command:
$ initdb -E EUC_KR $ initdb --encoding=EUC_KR
If you do not specify an encoding when you create the database cluster, initdb uses the encoding specified when you configured the PostgreSQL source code:
./configure --enable-multibyte=unicode
Finally, if you don't include an encoding name when you configure the PostgreSQL source code, SQL_ASCII is assumed.
So, if you don't do anything special, your database will not support multibyte encodings, and all character values are assumed to be expressed in SQL_ASCII.
If you enable multibyte encodings, all encodings are available. The encoding name that you can include in the --enable-multibyte flag selects the default encoding; it does not limit the available encodings.
Client/Server Translation
We now know that the PostgreSQL server can deal with encodings other than SQL_ASCII, but what about PostgreSQL clients? That question is difficult to answer. The pgAdmin and pgAdmin II clients do not. pgAccess does not. The psql client supports multibyte encodings, but finding a font that can display all required characters is not easy.
Assuming that you are using a client application that supports encodings other than SQL_ASCII, you can select a client encoding with the SET CLIENT_ENCODING command:
movies=# SET CLIENT_ENCODING TO UNICODE; SET
You can see which coding has been selected for the client using the SHOW CLIENT_ENCODING command:
movies=# SHOW CLIENT_ENCODING; NOTICE: Current client encoding is 'UNICODE' SHOW VARIABLE
You can also view the server's encoding (but you can't change it):
movies=# SHOW SERVER_ENCODING; NOTICE: Current server encoding is 'UNICODE' SHOW VARIABLE movies=# SET SERVER_ENCODING TO BIG5; NOTICE: SET SERVER_ENCODING is not supported SET VARIABLE
If the CLIENT_ENCODING and SERVER_ENCODING are different, PostgreSQL will convert between the two encodings. In many cases, translation will fail. Let's say that you use a multibyte-enabled client to INSERT some Katakana (that is, Japanese) text, as shown in Figure 20.1.
Figure 20.1. A Unicode-enabled client application.
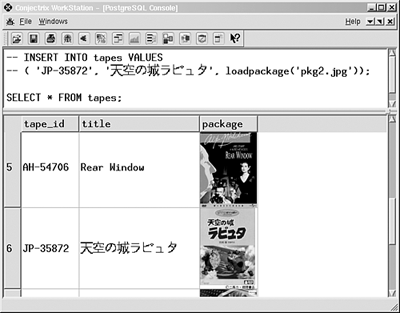
This application (the Conjectrix™ Workstation) understands how to work with Unicode data. If you try to read this data with a different client encoding, you probably won't be happy with the results:
$ psql -q -d movies news=# SELECT tape_id, title FROM tapes WHERE tape_id = 'JP-35872'; tape_id | title ----------+---------------------------------------------------------- JP-35872 | (bb)(bf)(e5)(a4)(a9)(e7)(a9)(ba)(e3)(81ae)(e5)(9f)(8e)... (1 row)
The values that you see in psql have been translated into the SQL_ASCII encoding scheme. The characters in the val column can be translated from Unicode into SQL_ASCII, but most cannot. The SQL_ASCII encoding does not include Katakana characters, so PostgreSQL has given you the hexadecimal values of the Unicode characters instead.








