Brief History of SQL and SQL Standards
Brief History of SQL and SQL Standards
As we already know, prerelational databases did not have a set of commands to work with data. Every database either had its own proprietary language or used programs written in COBOL, C, and so on to manipulate records. Also, the databases were virtually inflexible and did not allow any internal structure changes without bringing them offline and rewriting tons of code. That worked more or less effectively until the end of the 1960s, when most computer applications were based strictly on batch processing (running from beginning to end without user interaction).
Humble beginnings: RDBMS and SQL evolution
In the early 1970s, the growth of online applications (programs that require user's interaction) triggered the demand for something more flexible. The situations when an extra field was required for a particular record or a number of subfields exceeded the maximum number in the file layout became more and more common.
For example, imagine that CUSTOMER record set has two fixed-length fields, ADDRESS1 (for billing address) and ADDRESS2 (for shipping address), and it works for all customers for some period of time. But what if a customer, who owns a hardware store, has bought another store, and now this record must have more than one shipping address? And what if you have a new customer, WILE ELECTRONICS INC., who owns ten stores? Now, you have two choices. You can take the whole dataset offline, modify the layout, and change/recompile all programs that work with it. But then, all other customers that just have one store each will have nine unnecessary fields in their records (Figure 1-4). Also, nobody can guarantee that tomorrow some other customer is not going to buy, say, 25 stores, and then you'll have to start over again. Another choice would be to add ten identical records for Wile Electronics Inc., completely redundant except for the shipping address. The programs would still have to be changed, because otherwise they may return incorrect results (Figure 1-5).
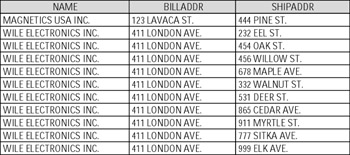
Figure 1-5: Multiple records to resolve multiple addresses for CUSTOMER
So, as you can see, most problems are actually rooted in the structure of the database, which usually consisted of just one file with records of a fixed length. The solution is to spread data across several files and reassemble the required data when needed. We already mentioned hierarchical and network database models that definitely were attempts to move in this direction, but they still had had too many shortcomings, so the relational model became the most popular technique. The problem we just discussed would not be a problem at all in a relational database, where CUSTOMER and ADDRESS are separate entities (tables), tied by primary/foreign key relationship (Figure 1-6). All we have to do is to add as many ADDRESS records as we want with a foreign key that refers to its parent (Figure 1-7).
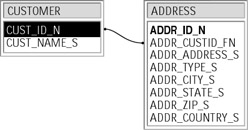
Figure 1-6: Primary/Foreign Key relationship between tables
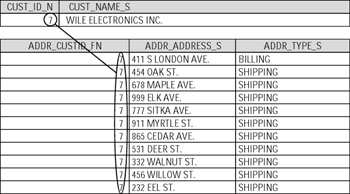
Figure 1-7: Resolving the multiple customer addresses problem within relational model
| Note |
Our example might not look very convincing — it almost looks like that instead of adding new shipping addresses to CUSTOMER, we just added the same records to a separate ADDRESS table. In fact, the difference is huge. In a real-life legacy database, CUSTOMER file would not have just NAME and ADDRESS fields, but rather it would contain tons of other information: about orders, products, invoices, shipments, etc. All that would be repeated every time you accessed the database, even for something as simple as adding a new shipping address. |
Another advantage of the relational schema was a simplified logic for the applications that worked with data. For example, let's assume the nonrelational CUSTOMER dataset has fields for a maximum of five customer orders. (That easily could be a couple fields per order, by the way.) If you want to display all orders for a specific customer, a program will have to scroll through all these fields, determine which ones are not empty, and display their contents. In the relational case, all you need to do is to display all records in ORDER_HEADER table that have the required customer number. All that made ad-hoc query languages relatively easy to write and finally resulted in appearance of SQL.
The concept of a relational database and thus SQL was first introduced by Dr. Edward Frank Codd, who worked for IBM as a researcher, in his paper "A Relational Model of Data for Large Shared Data Banks" in 1970. In simple words, his idea of a relational database model was based on data independence from hardware and storage implementation and a nonprocedural high-level computer language to access the data. The problem was, IBM already had declared its own product, called IMS, as its sole strategic database product; the company management was not convinced at all that developing new commercial software based on relational schema was worth the money and the effort. A new database product could also potentially hurt the sales of IMS.
In spite of all that, a relational database prototype called System R was finally introduced by IBM in the late 1970s, but it never became a commercial product and was more of a scientific interest, unlike its language SQL (first known as SEQUEL) that finally became the standard for all relational databases (after years of evolution). Another relational product called Ingres was developed by scientists in a government-funded program at the University of California, Berkeley at about the same time, and also had its own nonprocedural language, QUEL, similar to IBM's SQL.
But the first commercial relational database was neither System R nor Ingres. Oracle Corporation released its first product in 1979, followed by IBM's SQL/DS (1980/81) and DB2 (1982/83). The commercial version of Ingres also became available in the early 1980s. Sybase Inc. released the first version of its product in 1986, and in 1988 Microsoft introduced SQL Server. Many other products by other companies were also released since then, but their share of today's market is minimal.
A brief history of SQL standards
The relational database model was slowly but surely becoming the industry standard in the late 1980s. The problem was, even though SQL became a commonly recognized database language, the differences in major vendors' implementations were growing, and some kind of standard became necessary.
Around 1978, the Committee on Data Systems and Language (CODASYL) commissioned the development of a network data model as a prototype for any future database implementations. This continued work started in the early 1970s with the Data Definition Language Committee (DDLC). By 1982, these efforts culminated in the data definition language (DDL) and data manipulation language (DML) standards proposal. They became standards four years later — endorsed by an organization with an improbably long name, the American National Standards Institute National Committee on Information Technology Standards H2 Technical Committee on Database (ANSI NCITS H2 TCD).
NCITS H2 was given a mandate to standardize relational data model in 1982. The project initially was based on IBM SQL/DS specifications, and for some time followed closely IBM DB2 developments. In 1984, the standard was redesigned to be more generic, to allow for more diversity among database products vendors. After passing through all the bureaucratic loops it was endorsed as an American National Standards Institute in 1986. The International Standard Organization (ISO) adopted the standard in 1987. The revised standard, commonly known as SQL89, was published two years later.
SQL89 (SQL1)
SQL89 (or SQL1) is a rather worthless standard that was established by encircling all RDBMS in existence in 1989. The major commercial vendors could not (and still to certain degree cannot) agree upon implementation details, so much of the SQL89 standard is intentionally left incomplete, and numerous features are marked as implementer-defined.
SQL92 (SQL2)
Because of the aforesaid, the previous standard had been revised, and in 1992 the first solid SQL standard, SQL92 or SQL2, was published. ANSI took SQL89 as a basis, but corrected several weaknesses in it, filled many gaps in the old standard, and presented conceptual SQL features, which at that time exceeded the capabilities of any existing RDBMS implementation. Also, the SQL92 standard is over five times longer than its predecessor (about 600 pages more), and has three levels of conformance.
Entry-level conformance is basically improved SQL89. The differences were insignificant — for example, circular views and correlated subqueries became prohibited in SQL92
Intermediate-level conformance was a set of major improvements, including, but not limited to, user naming of constraints; support for varying-length characters and national character sets, case and cast expressions, built-in join operators, and dynamic SQL; ability to alter tables, to set transactions, to use subqueries in updatable views, and use set operators (UNION, EXCEPT, INTERSECT) to combine multiple queries' results.
Full-level conformance included some truly advanced features, including deferrable constraints, assertions, temporary local tables, privileges on character sets and domains, and so on.
The conformance testing was performed by the U.S. Government Department of Commerce's National Institute of Standards and Technology (NIST). The vendors hurried to comply because a public law passed in the beginning of the 1990s required an RDBMS product to pass the tests in order to be considered by a federal agency.
| Note |
As of this writing, all major database vendors (Oracle, DB2, MS SQL Server, and Sybase) meet only the first level of SQL92 conformance in full. Each of the vendors has individual features that venture into higher levels of conformance. The only vendor that claims its product meets all three levels, or 100 percent SQL92 compliant, is a small company called Ocelot Computer Services, Inc., and their RDBMS implementation of the same name does not seem to be very popular. |
In 1996, NIST dismantled the conformance testing program (citing "high costs" as the reason behind the decision). Since then, the only verification of SQL standards compliance comes from the RDBMS vendors themselves; this understandably increased the number of vendor-specific features as well as nonstandard implementation of the standard ones. By 2001, the original number of RDBMS vendors belonging to the ANSI NCIT had shrunk from 18 (at the beginning of the 1990s) to just 7, though some new companies came aboard.
| Note |
The current members of the ANSI NCIT H2 Technical Committee on Database are IBM, Oracle, Microsoft, NCR, Computer Associates, Compaq, Pervasive, FileTek, and InterSystems. |
SQL99 (SQL3)
SQL3 represents the next step in SQL standards development. The efforts to define this standard began virtually at the same time when its predecessor — SQL92 (SQL2) — was adopted. The new standard was developed under guidance of both ANSI and ISO committees, and the change introduced into the database world by SQL3 was as dramatic a shift from nonrelational to relational database model; its sheer complexity is reflected in the number of pages describing the standard — over 1,500 — comparing to 120 or so pages for SQL89 and about 600 pages for SQL92. Some of the defined standards (for example, stored procedures) existed as vendor-specific extensions, some of them (like OOP) are completely new to SQL proper. SQL3 was released as an ANSI/ISO draft standard in 1999; later the same year its status was changed to a standard level.
| Note |
We can draw a parallel between SQL ANSI/ISO standards and Latin. These standards are good to know; they may help one to learn the actual SQL implementations, but it is impossible (or almost impossible) to write a real 100 percent ANSI SQL compliant production script. The knowledge of Latin can help someone to learn Spanish, Italian, or Portuguese, but people would hardly understand you if you started speaking Latin on the streets of Madrid, Rome, or Lisbon. The main difference is the general direction — Latin is an ancestor of all the above (and many more) languages, and ANSI/ISO SQL standards are rather a goal for all proprietary SQL flavors. |
SQL3 extends traditional relational data models to incorporate objects and complex data types within the relational tables, along with all supporting mechanisms. It brings into SQL all the major OOP principles, namely inheritance, encapsulation, and polymorphism, all of which are beyond the scope of this book, in addition to "standard" SQL features defined in SQL92. It provides seamless integration with the data consumer applications designed and implemented in OO languages (SmallTalk, Eiffel, etc.).
There are several commercial implementations of OODBMS on the market as well as OO extensions to existing commercial database products; not all of them adhere to the standards and a number of proprietary "features" makes them incompatible. For a time being OODBMS (OORDBMS) occupy an insignificant portion of the database market, and the judgment is still out there.
While it is impossible to predict what model will emerge as a winner in the future, it seems reasonable to assume that relational databases are here in for a long haul and have not yet reached their potential; SQL as the language of the RDBMS will keep its importance in the database world.







