UPDATE: Modifying Table Data
UPDATE: Modifying Table Data
The UPDATE statement serves the purpose of modifying existing database information. We can emphasize two general situations when we need to change data.
Somevimes when you insert rows into a table, you don't know all information yet (that's where NULL values come in handy); later on, when the information becomes available, you can update the appropriate row(s). For example, you may want to create a new customer before you know who the customer's salesperson is going to be, or generate a new order line entry with an unknown shipped quantity. (There is no way to know what this quantity is before the order is actually shipped.)
Another case when you may need to change database information is when you have to reflect some changes in the "real world." For example, a customer could cancel an order, so you would have to change the order status from COMPLETE to CANCELLED; a customer might accumulate "bad debt," so you would want to put his credit on hold. (In the ACME database that would mean to change CUST_CREDHOLD_S field to Y.)
The UPDATE statement is used to modify table data; again, as with the INSERT statement discussed earlier, either directly or through an updateable view. Here is the generic syntax for our "big three" databases:
UPDATE <table_or_view_name>
SET {<column_name> = <literal> |
<expression> |
(<single_row_select_statement>) |
NULL |
DEFAULT,...}
[WHERE <predicate>]
The UPDATE statement allows you to update one table at a time. Other than that, it provides great flexibility on what set of values you are updating. You could update single or multiple columns of a single row or multiple rows, or (though it is rarely employed) you could update each and every column of all table rows. The granularity is determined by different clauses of the UPDATE statement.
| Note |
The situation when no rows were updated because there were no rows in the table that satisfied the WHERE clause condition is not considered an error by RDBMS. The same stands for the DELETE statement (discussed in the next section). When no rows satisfy the WHERE clause, no rows are updated and no error is generated. |
We are now going to discuss the most common clauses of the generic UPDATE.
Common UPDATE statement clauses
The name of the table (or an updateable view) to be updated is provided in the table_or_view_name clause.
In the SET clause, you specify the name of the column to update and the new value to be assigned to it. You can specify multiple corresponding column/value pairs separated by commas. The assignment values could themselves be the same as in the VALUES clause of the INSERT statement (i.e., literals, expressions, nulls, defaults, etc.).
The WHERE clause sets your "horizontal" limits — if in the SET clause you specified what columns to update, now you have to define a condition upon which some rows need to be updated.
The WHERE clause is very important and has to be handled with care. If you accidentally skipped it or based it on an incorrect assumption, it could update all rows in your table with the same value, and that's usually not what you want. For example, you might want to change the price from $33.28 to $34.76 for product 1880 (STEEL NAILS 6"). You start thinking — well, may be something like the following will do:
UPDATE product SET prod_price_n = 34.76
But if you forgot about the WHERE clause, the result would be rather disastrous — all products in the ACME database now cost $34.76! The correct syntax to use would be:
UPDATE product SET prod_price_n = 34.76 WHERE prod_num_s = '1880'
Note that even if you remembered about the WHERE clause but just made a typo, e.g., > instead of =, the result is not much better — all products with product numbers greater than '1880' will be erroneously updated.
Updating a single column of a single row
One of the most common update situations is when you need to modify just one column of a single row. Assigning a salesperson to a recently created customer, canceling an order, changing a product price — these are all examples of such a procedure. The following example assigns a price to product 990 that we previously created when we discussed INSERT in this chapter:
UPDATE product SET prod_price_n = 18.24 WHERE prod_id_n = 990
| Tip |
Using primary key or column(s) with UNIQUE constraint in the UPDATE statement's WHERE clause ensures you are only updating one row uniquely identified by the value in the column. |
Updating multiple columns
Sometimes you might want to update more than one column within one UPDATE statement. For example, imagine the manufacturer has changed the packaging for its product 990, so the dimensions are now 5 ×7 instead of 4 ×6. This update statement synchronizes the database information with the real-world change:
UPDATE product
SET prod_pltwid_n = 5,
prod_pltlen_n = 7
WHERE prod_id_n = 990
Updating a column in all rows
Even though updating all table rows is not very typical (and often undesirable), sometimes you might want to perform such an operation. Giving all employees a 5 percent raise, inactivating all customers, setting all column values to NULL — these are a few common examples. As you could have noticed, the keyword here is "all." In other words, we would only want to omit the WHERE clause intentionally if we wanted to update each and every single row in the target table.
The UPDATE statement below increases all product prices by 10 percent (ACME, Inc. struggles with the increased operation costs):
UPDATE product SET prod_price_n = prod_price_n * 1.1
| Cross-References |
Using operators in SQL queries is explained in Chapter 11. |
Updating column using a single-row subquery
You can use the result of a SELECT statement (subquery) as an assignment value in an UPDATE statement. The main thing to remember is that your subquery must return no more than one row. (If no rows are returned, the NULL value will be assigned to the target column.) Also, according to SQL99 standards, only one expression can be specified in the select list.
| Note |
Oracle and DB2 allow you to specify multiple values in the select list of a single row subquery; the details are given later in this chapter. |
You can concatenate two or more columns or perform math operations on them, but you can not list multiple columns separated with commas. Thus, SET my_col = (SELECT col1 + col2 ...) is valid, but SET my_col = (SELECT col1, col2 ...) is not.
Deriving the assignment value from another value
There are many situations when using a subquery as an assignment value is beneficial. For example, you want to change the payment terms for order 30670 to be N21531 in the ACME database. The problem is, in our relational database we do not store the actual value N21531 in an ORDER_HEADER table column; instead, we use the foreign key, which is a meaningless integer, from the PAYMENT_TERMS table. Using a subquery helps us to accomplish the task:
UPDATE order_header
SET ordhdr_payterms_fn =
(SELECT payterms_id_n
FROM payment_terms
WHERE payterms_code_s = 'N21531')
WHERE ordhdr_id_n = 30670
Figure 6-1 illustrates the above example.
 Figure 6-1: Using data from other table as an assignment value
Figure 6-1: Using data from other table as an assignment value
The statement above has two WHERE clauses, but don't be confused: the first one belongs to the SELECT statement — as indicated by the surrounding parentheses, limiting the resulting set to one value — the primary key for the row where the value of payterms_code_s column is equal to N21531; the second WHERE clause belongs to the UPDATE statement and ensures that only one row of ORDER_HEADER with ordhdr_id_n equal to 30670 is updated.
Update with correlated subquery
The previous example was relatively straightforward — you derived the value you needed for the update from another given value. But sometimes conditions are more complicated. For example, imagine that ACME's business rules have changed and no longer allow orders to have payment terms different from the default payment terms of a customer who placed the order. You can relate (join) a table from the UPDATE clause with tables specified in the assignment subquery — that pretty much overrides the "single-row" rule because the assignment will be done on a row-by-row basis:
UPDATE order_header
SET ordhdr_payterms_fn =
(SELECT payterms_id_n
FROM payment_terms,
customer
WHERE payterms_id_n = cust_paytermsid_fn
AND ordhdr_custid_fn = cust_id_n)
The very last line of this syntax joins the ORDHDR_CUSTID_FN field of the ORDER_HEADER table (UPDATE statement) with the CUST_ID_N table of the CUSTOMER table (nested subquery); in other words, the customer id field is the link between the UPDATE statement and the subquery that correlates them.
| Note |
You don't have to use table aliasing here because of the special notation rules you used when the ACME database was created. Each column is already prefixed with its table name abbreviation, so there are no ambiguous column names. |
| Cross-References |
More discussion about table aliasing can be found in Chapters 8 and 9. |
For each row in ORDER_HEADER you must find the corresponding value in the resulting set of the subquery and use it as an assignment value. The concept is illustrated in Figure 6-2.
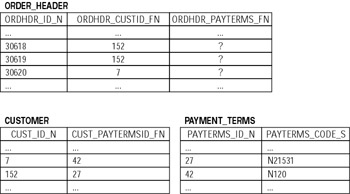
Figure 6-2: Updating multiple rows using correlated subquery
| Note |
This syntax uses "old" join notation, which is recognized by all our "big three" databases. We used it here because in our opinion it better illustrates the correlated query concept. The SQL99-compliant equivalent syntax would be: |
UPDATE order_header
SET ordhdr_payterms_fn =
(SELECT payterms_id_n
FROM payment_terms
JOIN customer
ON payterms_id_n = cust_paytermsid_fn
JOIN order_header
ON ordhdr_custid_fn = cust_id_n)
The main differences between the "old" and the "new" join syntaxes are discussed in Chapter 9.
| Note |
Subqueries can also be used in the WHERE clause of the UPDATE statement in a similar way to the WHERE clause of the SELECT statement. We are going to discuss subqueries in general and correlated subqueries in particular in Chapter 8. |
UPDATE statement and integrity constraints
Updating table rows obeys rules and restrictions similar to ones with INSERT statement. All column values have to be of the same or compatible data types and sizes with corresponding column definitions and no integrity constraints should be violated. There is a slight difference in behavior with the referential integrity constraints — when constraint is specified with ON UPDATE CASCADE or ON UPDATE SET NULL, RDBMS successfully performs an update of the target table; child tables' columns are also updated with the corresponding values.
| Cross-References |
Constraints are discussed in Chapter 4. |
Vendor-specific UPDATE statement details
Like the INSERT statement, UPDATE also has some vendor-specific features. This section briefly discusses the most important ones.
Oracle 9i and DB2 8.1
The main thing that differs between Oracle and DB2's UPDATE syntax and that of our generic one is the option to specify values enclosed into the brackets and separated with commas in the SET clause and specify multiple corresponding assignment values for them. The syntax is
SET (col1, col2,... colN) = (value1, value2,... valueN)
The advantage of this syntax is in ability to use a multicolumn subquery instead of the list of values:
SET (col1, col2,... colN) =
(SELECT value1, value2,... valueN
FROM...)
The subquery still has to return no more than one row.
| Cross-References |
Subqueries are explained in Chapter 8. |
MS SQL Server 2000
The UPDATE statement has an optional FROM clause in MS SQL Server. It specifies the table(s) to be used to provide the criteria for the update operation and can be used in a very similar way to the previously discussed correlated query. The following example performs virtually the same task as the correlated query from the previous section; the only difference is that when you use the former syntax, each and every row of ORDER_HEADER is updated unconditionally, whereas MS SQL Server syntax excludes columns with nulls unless the OUTER JOIN was used (more about joins in Chapter 9):
UPDATE order_header SET ordhdr_payterms_fn = payterms_id_n FROM payment_terms JOIN customer ON payterms_id_n = cust_paytermsid_fn JOIN order_header ON ordhdr_custid_fn = cust_id_n







