DELETE: Removing Data from Table
DELETE: Removing Data from Table
Believe it or not, there is such a thing as too much data. Since computerized databases were introduced, humankind had accumulated pentabytes of data. We are drowning in it, and DELETE provides a way to get rid of the information that is no longer needed. Deleting database rows is usually necessary when the entity these rows correspond to becomes irrelevant or completely disappears from the real world. For example, an employee quits, a customer does not make orders any more, or shipment information is no longer needed.
| Note |
Quite often the entity information is not removed from the database right away. When an employee quits, the HR department still keeps the historical information about this employee; when a customer is inactive for a long time, it is sometimes more logical to "inactivate" him rather than delete — in the relational database deleting a customer usually involves much more than just removing one CUSTOMER table record — it would normally have referential integrity constraints from other tables, the other tables in their order would be referenced by more tables, and so on. There is a way to simplify the process by using the ON DELETE CASCADE clause, but that's not always exactly what you want. Even when you don't need, say, information for a certain customer any more, you still may want to be able to access the data about orders and invoices for this customer, and so on. |
You may also want to delete rows when they were inserted by mistake — for example, an order was taken twice, or a duplicate customer record was created. Situations like those are not atypical at all, especially for large companies where dozens of clerks take orders and create new customers.
| Tip |
Good database design can help to reduce the number of human errors. For example, putting unique constraint on the customer name field could help in preventing duplicate customers (not completely foolproof, though, because RDBMS would still treat "ACME, INC." and "ACME INC." as two distinct strings). |
The DELETE statement removes rows from a single table (either directly or through an updateable view). The generalized syntax is
DELETE FROM <table_or_view_name> WHERE <predicate>
| Note |
The FROM keyword is optional in Oracle and MS SQL Server but is required for DB2 syntax and compliant with SQL99 standards. |
DELETE removes rows from one table at a time. You can delete one or many rows using a single DELETE statement; when no rows in the table satisfy the condition specified in the WHERE clause, no rows are deleted, and no error message is generated.
Common DELETE statement clauses
The DELETE statement is probably the simplest out of all DML statements. All you need to specify is the table you want to remove rows from and (optionally) upon what criteria the rows are to be deleted. The syntax simplicity should not mislead you — DELETE statements can be quite complicated and require caution. If the WHERE clause is omitted or malformed, valuable information could be deleted from the target table. Quite often the results are not exactly what you wanted, and the data restoration process could be painful and time consuming.
The statement below deletes a salesman record from the SALESMAN table:
DELETE FROM salesman WHERE salesman_code_s = '02'
This statement deletes all records from PHONE table:
DELETE FROM phone
DELETE statement and integrity constraints
The DELETE statement is not as restrictive as INSERT and UPDATE in terms of integrity constraints. PRIMARY KEY, UNIQUE, NOT NULL, or CHECK constraints would not prevent you from deleting a row. The referential integrity constraints are a different story — you would not be able to delete a row that contains a column referenced by another column unless the referential integrity constraint has the ON DELETE CASCADE option (SQL99 standard implemented by all "big three" RDBMS vendors). In that case DELETE would succeed; all rows in any tables that referenced the constrained column would also be deleted. This behavior can be extremely dangerous, especially in combination with a badly constructed WHERE clause, so it is considered to be a good practice to use ON DELETE CASCADE with care. Imagine the situation where you have a table CUSTOMER referenced by a table ORDER, which is its order referenced by a table SHIPMENT. If ON CASCADE DELETE is used in both relationships, when you delete a customer record, all related order and shipment records are also gone. Just imagine what would happen if you also skipped the WHERE clause! Figure 6-3 illustrates this example.
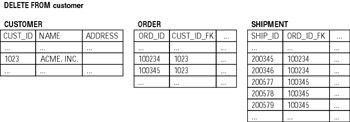 Figure 6-3: Deleting from table referenced by ON DELETE CASCADE constraints
Figure 6-3: Deleting from table referenced by ON DELETE CASCADE constraints
Another (slightly less dangerous) referential constraint option is ON DELETE SET NULL (SQL99 standard implemented by Oracle and DB2). No records from the referencing tables will be deleted, but the values for the foreign key columns will be set to nulls as illustrated in Figure 6-4.

Figure 6-4: Deleting from table referenced by ON DELETE SET NULL constraints
If a referential integrity constraint exists on a column with default (NO ACTION) options, and the column is referenced, the DELETE would fail. The error messages vary between different vendors. The example below is for Oracle:
SQL> DELETE FROM CUSTOMER; DELETE FROM CUSTOMER * ERROR at line 1: ORA-02292: integrity constraint(ACME.FK_ORDHDR_CUSTOMER) violated – child record found
Using subqueries in DELETE statement WHERE clause
Similarly to UPDATE statement, in addition to comparison operators, literals, and expressions, the WHERE clause in DELETE statements can contain a subquery to allow the selection of rows to be deleted based on data from other tables. The idea is very similar to one explained in section about the SET clause of the insert value — using a subquery you derive value(s) based on some known value(s). For example, you want to delete all orders for customer WILE SEAL CORP., but we don't know the value of its primary key (which is a foreign key in the ORDER_HEADER). You can accomplish the task using the appropriate subquery in the WHERE clause:
DELETE FROM order_header
WHERE ordhdr_custid_fn =
(SELECT cust_id_n
FROM customer
WHERE cust_name_s = 'WILE SEAL CORP.')
| Tip |
Correlated subqueries can also be used with the DELETE statement in a way similar to one discussed in the UPDATE section. |
Vendor-specific DELETE statement clauses
The vendor-specific DELETE statement variations are rather insignificant. The brief explanation follows.
Oracle 9i
The only significant difference between Oracle and generic DELETE syntax is that the FROM keyword is optional and can be skipped.
MS SQL Server 2000
MS SQL Server recognizes our generic syntax that uses a subquery in the WHERE clause; in addition, it provides its own proprietary syntax using the FROM clause with different meaning. This is the equivalent to our "standard" syntax to delete all orders for WILE SEAL CORP.:
DELETE order_header FROM order_header JOIN customer ON ordhdr_custid_fn = cust_id_n WHERE cust_name_s = 'WILE SEAL CORP.'







