Foundation Topics
Building Scalable Networks
Because this book has not yet discussed large data networks, this chapter uses the phone system as an easily understandable example of network design.
Originally, folks needed to run wires to every home they might want to call. Phone companies provided a more efficient way to form connections by using one line from a home to a central point to switch traffic to arbitrary locations. Another type of consolidation came when the T1 carrier was introduced. Before T1 a business needing 20 phone lines would have needed 20 pairs of copper run out from the telephone central office (CO). A T1 uses 2 pairs and supports 24 concurrent conversations.
Although this example might seem far afield, it points out two techniques that are used to simplify networks: scalability and multiplexing.
Scalability
This book is about building scalable Cisco internetworks, but what does "scalable" mean? The definition of scalability affects every subject in this book. Therefore, it is important to begin with an idea of what a "scalable" network looks like.
Imagine that to use the phone, folks in a town would need to run a telephone line from every home to every other house. This is called a full-mesh design. If there are n homes in the town, the total number of lines required is
lines = n(n - 1)/2
Table 1-2 relates town size to the number of lines required to support the town.
| Homes | Lines Required |
|---|---|
| 10 | 45 |
| 100 | 4,950 |
| 1000 | 499,500 |
Figure 1-1 illustrates this same point with a town of five homes. Notice that for five homes, 10 lines are required: 5(4)/2 = 10.
Figure 1-1. Full-Mesh Phone Network
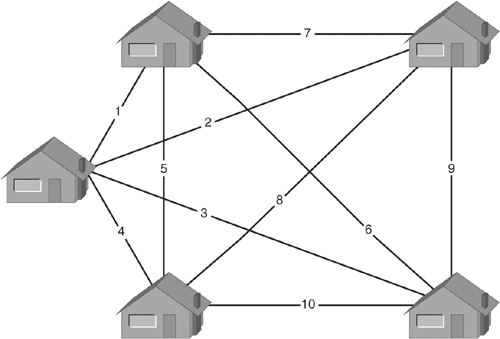
Adding one more home to the diagram would require five new lines, taking the town from 10 lines to 15. This type of growth is called exponential growth because the number of lines is growing proportional to an n2 pace. In this system, the 100th house must have 99 lines (one to each of the preceding homes), while the 101st house will need 100 lines. It therefore becomes progressively more expensive to expand the network. It is easy to see that the town could not expand too much using this type of wiring.
On the other hand, the town might run one phone line from each house back to a central switching station. This type of topology is called a hub and spoke. With this topology, any line could arbitrarily be connected to any other line. In this system, the total number of lines required is calculated simply (where n is the number of endpoints, that is, every home plus the CO):
lines = n - 1
Table 1-3 relates town size to the number of lines required to support the town. Remember that the CO counts as an endpoint, so for 10 homes n = 11 (10 + CO).
| Homes | Lines Required |
|---|---|
| 10 | 10 |
| 100 | 100 |
| 1000 | 1000 |
Figure 1-2 illustrates this same point with a town of five homes. Notice that for five homes, five lines are required.
Figure 1-2. Hub and Spoke Phone Network
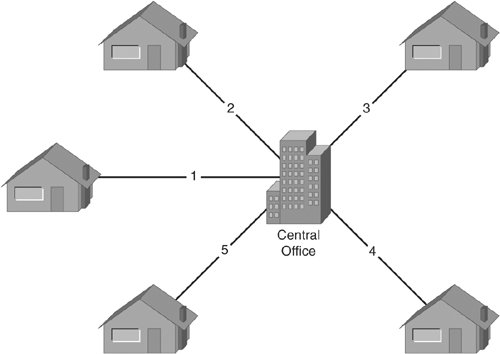
Each new home added now requires only one new line. This type of growth is called linear growth because the number of lines increases at the same pace as the number of homes. As the town grows, the price of installing the 101st house will be the same as the cost of the installation of the 100th house.
Scalability is a term that indicates that a network can support arbitrary growth and that the cost per endpoint will remain constant. One of the primary goals for any network designer is to support scalable growth.
Multiplexing
Historically, voice traffic has used one set of circuits and data traffic has used another. In the 1980s, data traffic was even segregated into separate networks for mainframe traffic (SNA) and LAN traffic (such as IPX or IP).
A T1 places 24 phone conversations onto two copper pairs by time division multiplexing (using short slices of time for each channel). The T1 saves the phone company a lot of expense in building out subscriber lines. However, T1s cannot dynamically adjust as usage requirements change.
It was very common to find a T1 where 12 of the 24 channels were dedicated to voice, 6 to IPX, and 6 to SNA. This works, but what happens when IPX runs out of capacity and no one is talking on the phone? Nothing, because this segregated system lacks a mechanism to dynamically adjust.
Modern networks are designed to carry voice, enterprise applications, normal LAN traffic, and management traffic all on a single secure infrastructure. This practice is called convergence. The traffic is forced, or statistically multiplexed, to share access to the network.
Recognizing the types of traffic modern converged networks have to bear will be important in just a bit, so hold this thought. The next topic discussed is design; after this, the chapter will again focus on traffic flow and how it impacts design.
Enterprise Architecture
With new networks, it is important to take the time to consider how addressing will take place and how routing protocols will run. Many modern networks have grown organically to meet business conditions; this lack of deliberation creates problems. Therefore, it is important to consider good design principles and to prune those organic networks back to something that is manageable.
A firm idea of what good design looks like is an important tool in building and maintaining networks. The Cisco description of a well-designed network has evolved over time, and this section presents the older hierarchical model and the newer enterprise composite model.
Hierarchical Design Model
Cisco has used the three-level hierarchical design model for years. This older model provided a high-level idea of how a reliable network could be conceived but was largely conceptual, because it did not provide specific guidance.
Figure 1-3 shows a prototypical picture of the hierarchical design model. This is a simple drawing of how the three-layer model might have been built out. A distribution Layer 3 switch is used for each building on campus, tying together the access switches on the floors. The core switches link the various buildings together.
Figure 1-3. Hierarchical Design
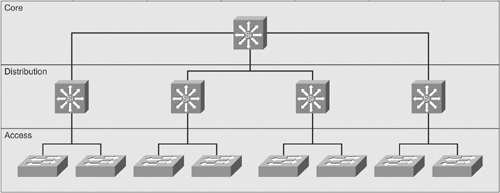
Access devices are Layer 2 switches based on price per port and are chosen to get the needed number of ports. Access switches are responsible for attaching end systems to the network and assigning them to virtual LANs (VLANs).
Distribution devices are Layer 3 switches and act as intermediate devices that route between VLANs and apply traffic policies such as firewalling and quality of service (QoS) decisions.
Core devices, also known as the backbone, provide high-speed paths between distribution devices.
Note that the distribution layer is the "sweet spot" for managing the network. Implementing policy on access devices would drive up the complexity and costs of those devices and slow them down, plus it would mandate complex management of a large number of devices. Implementing policy at the core would slow down devices that are primarily tasked with moving traffic quickly.
This early model was a good starting point, but it failed to address key issues, such as
Implementing redundancy
Adding Internet access and security
Accounting for remote access
Locating workgroup and enterprise services
Cisco developed the enterprise composite network model to addresses these issues.
Enterprise Composite Network Model
Later versions of the hierarchical model showed redundant distribution and core devices and connections to make the model more fault tolerant. A set of distribution devices and their accompanying access layer switches were called a switch block. Figure 1-4 shows a switch block design.
Figure 1-4. Campus Design with Switch Blocks
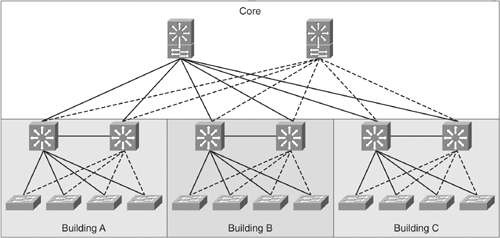
Switch block design helped explain how redundancy fit in networks, but still did not adequately specify other parts of network design. Cisco therefore developed a newer design model—the enterprise composite model—that is significantly more complex. This model attempts to address the major shortcomings of the hierarchical model by expanding the older version and making specific recommendations about how and where certain network functions should be implemented. This model is based on the principles described in Cisco's description of converged networks.
The enterprise composite model is broken up into three large pieces:
Enterprise campus
Enterprise edge
Service provider edge
Figure 1-5 shows the complete enterprise composite model.
Figure 1-5. Enterprise Composite Model
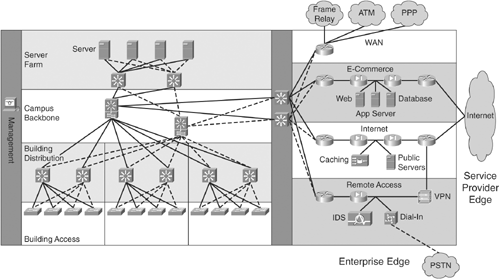
The following sections describe each piece of the enterprise composite model.
Enterprise Campus
The enterprise campus looks like the switch block design with some added details. It features five sections:
Campus backbone (like the core layer of the hierarchical model)
Building distribution
Building access
Management
Server farm (for enterprise services)
Figure 1-6 shows the enterprise campus.
Figure 1-6. Enterprise Campus
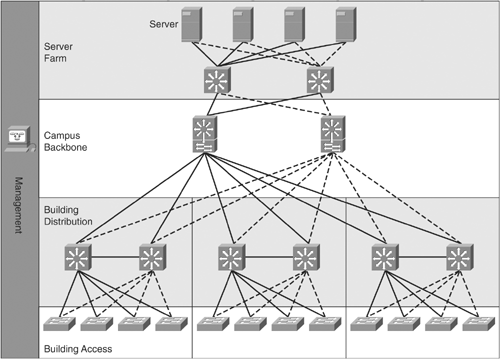
As you can see, the enterprise campus builds on the switch block idea but gives specific guidance about where to place servers and management equipment. Notice that the server farm looks like a switch block, but here all the servers are directly and redundantly attached (also called dual-homed) to the switches.
Enterprise Edge
The enterprise edge details the connections from the campus to the wider area and includes
E-Commerce
Internet connectivity
Remote access (dial-up and VPN)
WAN (internal links)
Note that the enterprise edge is basically just another switch block with redundant distribution elements and resources within, only with some extra definition. Figure 1-7 shows the enterprise edge.
Figure 1-7. Enterprise Edge
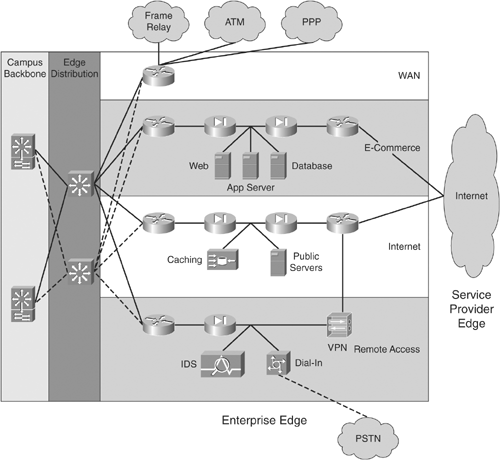
Service Provider Edge
The service provider edge includes the public networks that facilitate wide-area connectivity:
Internet service provider (ISP)
Public Switched Telephone Network (PSTN) for dialup
Frame Relay, ATM, and PPP for private connectivity
SONA and IIN
The "Multiplexing" section of this chapter described the idea of a converged network as a system that integrates what were previously disparate systems (such as voice, video, and data). The contents of a converged network include the following traffic types:
Voice signaling and bearer traffic
Core application traffic, such as enterprise resource planning or customer relationship management
Transactional traffic related to database interaction
Network management traffic for monitoring and maintaining the network structure (including routing protocol traffic)
Multicast multimedia
"Other" traffic, such as web pages, e-mail, and file transfer
Each of these traffic types has unique requirements and expectations that govern its execution. These requirements include security, QoS, transmission capacity, and delay.
Security, in particular, is a constant requirement. Data can be stolen, erased, or corrupted through malicious attack. Safeguarding the secure operation of the network is the first goal, which should be accomplished before looking at speed or efficiency.
The other parameters vary—for example, interactive traffic tends to use little capacity but needs quick response, whereas "default" applications such as file transfer really only care about capacity.
To support this mixture of multiplexed traffic, Cisco routers are able to implement filtering, compression, prioritization, and policing (dedicating network capacity). Except for filtering, these capabilities are referred to collectively as QoS.
Note
The absolute best way to meet capacity requirements is to have twice as much bandwidth as needed. QoS is needed only when there is not enough bandwidth. In most cases this strategy is a bit of a dream, however.
As an alternative to QoS, Cisco espouses an ideal called the Intelligent Information Network (IIN).
IIN describes a vision of a network that integrates network and application functionality cooperatively and allows the network to be smart about how it handles traffic to minimize the footprint of applications. For instance, security can be handled at the switch port instead of at a central server, or XML contents can be used to make routing decisions. IIN is built on top of the enterprise composite model and describes additional functionality overlaid on the composite template.
IIN is an evolutionary approach, where functionality is added as required. The IIN evolution is described in three phases:
Phase 1: Integrated Transport
Phase 2: Integrated Services
Phase 3: Integrated Applications
The following sections describe each phase in more detail.
Phase 1: Integrated Transport
Phase 1, Integrated Transport, describes a converged network, built along the lines of the enterprise composite model and based on open standards. The industry has been transitioning to this phase over the past few years and Cisco Integrated Services Routers are a tangible example of this trend.
Phase 2: Integrated Services
Phase 2, Integrated Services, attempts to virtualize resources such as servers, storage, and network access, and move to an "on-demand" model.
Virtualization of resources is a phrase that at first hearing sounds like marketing-speak; however, by this, Cisco means that services are not associated with a particular device or location. Instead, many services may reside in one device to ease management, or many devices may provide one service to provide more reliable service.
An example of providing many services on one device is the Integrated Services Router, which brings together routing, switching, voice, network management, security, and wireless. Another example is load balancers, which make many servers look like one in order to grow out the capacity.
The opposite of this is taking one resource and making it look like many. The new generation of IOS is capable of having a router present itself as many "virtual router" instances, allowing your company to deliver different logical topologies on the same physical infrastructure. Server virtualization is another example. Virtual servers allow one physical machine to support many installations.
Of course, the classic example of taking one resource and making it appear to be many resources is VLANs. VLANs allow one physical infrastructure to support multiple network implementations.
However you slice it, virtualization provides flexibility in configuration and management.
Phase 3: Integrated Applications
Phase 3, Integrated Applications, uses application-oriented networking (AON) to make the network "application aware" and allow the network to actively participate in service delivery.
An example of this phase three IIN holistic approach to service delivery is Network Admission Control (NAC). Before NAC, authentication, VLAN assignment, and anti-virus updates were separately managed. With NAC in place, the network is able to check the policy stance of a client and admit, deny, or remediate based on policies.
IIN allows the network to deconstruct packets, parse fields, and take actions based on the values it finds. An Integrated Services Router equipped with an AON blade might be set up to route traffic from a business partner. The AON blade could examine traffic, recognize the application, and rebuild XML files in memory. Corrupted XML fields might represent an attack (called schema poisoning), so the AON blade could react by blocking that source from further communication. In this example, routing, an awareness of the application data flow, and security are combined to allow the network to contribute to the success of the application.
Services-Oriented Network Architecture
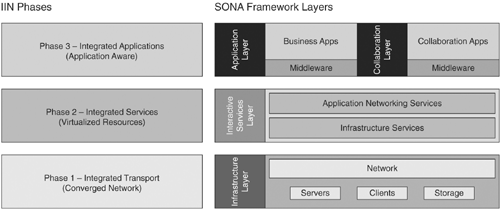
Services-Oriented Network Architecture (SONA) is the application of the IIN ideas to enterprise networks. SONA breaks down the IIN functions into three layers. The SONA Network Infrastructure is comparable to IIN Phase 1. IIN Phase 2 is analogous to the SONA Interactive Services layer, while the Application layer has the same concepts as IIN Phase 3. More specifically, the three SONA layers are
Network Infrastructure, which describes a hierarchical converged network and the attached end-systems.
Interactive Services, which allocates resources to applications.
Application, which includes business policy and logic integration
Figure 1-8 shows the mapping between IIN and SONA.
Figure 1-8. IIN and SONA
Comparing Routing Protocols
The majority of this book is devoted to understanding how routing protocols work and how they are optimized. Before delving into the details, though, it's worth thinking about the characteristics of routing protocols, how the protocols differ, and how those differences impact design. This section discusses RIP (versions 1 and 2), OSPF, EIGRP, IS-IS, and BGP.
Note
This book assumes that you have completed CCNA or have equivalent experience. Basic knowledge and techniques used with RIP, EIGRP, and OSPF will be found with the CCNA material.
Distance Vector and Link State Routing Protocols
Routing protocols are built to employ one of two basic strategies to communicate routing information. Distance vector routing protocols work by passing copies of their routing table to their neighbors (this is also known as "routing by rumor" because neighbors talk to neighbors and not the source of the route). Link state routing protocols work by advertising a list of their neighbors and the networks attached to their neighbors until all routers have a copy of all lists. The routers then run the Shortest Path First algorithm to analyze all paths and determine best paths.
Distance vector routing is less processor- and memory-intensive than link state routing, but can have loops because decisions are made on incomplete information (solely the portion of the routing table sent by a neighbor). Link state routing is loop-proof because routers know all possible routes, but link state routing requires more CPU time and memory.
Table 1-4 shows the various routing protocols and the technique they employ.
| Protocol | Technique |
|---|---|
| RIP | Distance Vector |
| RIPv2 | Distance Vector |
| EIGRP | Distance Vector |
| OSPF | Link State |
| IS-IS | Link State |
| BGP | Path Vector |
Classless and Classful Routing
Another characteristic of routing protocols is the manner in which they advertise routes. Older routing protocols pass just the prefix, such as "192.168.1.0." Given that example, there is no way for a router to understand if the network advertised uses a 24-bit mask or a 27-bit mask.
Older routing protocols, such as RIP and IGRP, assume the subnet mask is the same as the one on the receiving interface or that it is the default mask. The default mask for Class A networks is /8, for Class B it is /16, and for Class C it is /24. This behavior is called classful, because the assumption is based on the class of the IP address.
Example 1-1 shows an advertisement from a Routing Information Protocol (RIP) router. Notice that no subnet mask is advertised. For instance, the first route is 10.0.0.0 with no indication of the appropriate subnet mask. This shows that RIP is a classful routing protocol.
Example 1-1. Classful RIP Advertisements
Router1#debug ip rip
RIP protocol debugging is on
00:03:40: RIP: received v1 update from 172.16.2.200 on Serial1/0
00:03:40: 10.0.0.0 in 1 hops
00:03:40: 172.16.4.0 in 1 hops
00:03:40: 172.16.6.0 in 1 hops
00:03:40: 172.16.44.0 in 2 hops
00:03:40: 172.16.66.0 in 2 hops |
Modern routing protocols (OSPF, IS-IS, and EIGRP) explicitly advertise the mask. There is no assumption involved, the mask is clearly indicated. This behavior is referred to as classless.
Variable Length Subnet Masks (VLSM) refers to the property of a network that allows different subnet masks to be mixed throughout the network. For instance, office networks might each use /24 while point-to-point lines use /30. Classless Interdomain Routing (CIDR) is a property of a network that allows classful networks to be aggregated—for example, combining 192.168.0.0/24 and 192.168.1.0/24 into a "supernet" that includes 512 addresses. Classless routing protocols support VLSM and CIDR. In fact, the three terms are so closely linked that they are sometimes used synonymously.
Example 1-2 shows RIP version 2 (RIPv2) enabled on Router1. Notice that the subnet mask is now advertised. RIPv2 is a classless routing protocol.
Example 1-2. Classless RIPv2 Advertisements
|
Code View: Router1#configure terminal Enter configuration commands, one per line. End with CNTL/Z. Router1(config)#router rip Router1(config-router)#version 2 Router1(config-router)#end Router1#debug ip rip RIP protocol debugging is on 00:11:07: RIP: sending v2 update to 224.0.0.9 via FastEthernet0/0 (172.16.22.1) 00:11:07: RIP: build update entries 00:11:07: 10.0.0.0/8 via 0.0.0.0, metric 2, tag 0 00:11:07: 172.16.2.0/24 via 0.0.0.0, metric 1, tag 0 00:11:07: 172.16.4.0/24 via 0.0.0.0, metric 2, tag 0 00:11:07: 172.16.6.0/24 via 0.0.0.0, metric 2, tag 0 00:11:07: 172.16.44.0/24 via 0.0.0.0, metric 3, tag 0 00:11:07: 172.16.66.0/24 via 0.0.0.0, metric 3, tag 0 |
The Internet has been classless for years and the vast majority of enterprise networks are classless. In fact, classful routing protocols should be considered outdated. Classless routing protocols are necessary in today's network. Table 1-5 shows the protocols and whether each is classful or classless.
| Protocol | Classless or Classful |
|---|---|
| RIP | Classful |
| RIPv2 | Classless |
| EIGRP | Classless |
| OSPF | Classless |
| IS-IS | Classless |
| BGP | Classless |
Interior and Exterior Gateway Protocols
Most protocols are interior gateway protocols, meaning that they are designed to run inside your network. Inside a network, routers can trust each other and—because all links are owned by the organization—can choose paths without regard to who owns a link.
BGP is an exterior gateway protocol (EGP), meaning that BGP is the routing protocol used between autonomous systems in the public Internet. Because it is the only EGP, you will have to consider using it if you connect your network to the Internet.
Table 1-6 shows the routing protocols and whether each is intended for interior or exterior use.
| Protocol | Interior or Exterior Gateway Protocol |
|---|---|
| RIP | IGP |
| RIPv2 | IGP |
| EIGRP | IGP |
| OSPF | IGP |
| IS-IS | IGP |
| BGP | EGP |
Convergence Times
Another distinguishing characteristic of routing protocols is speed. Convergence times are generally grouped as slow or fast. Fast convergence means that the routing protocol is able to recognize a problem and fix it faster than a user can call to report the problem. Slow protocols, such as RIP and IGRP, can take minutes to converge. Fast protocols, such as OSPF, IS-IS, and EIGRP, generally converge in less than ten seconds.
Table 1-7 shows the convergence speeds of the routing protocols to help in your selection.
| Protocol | Convergence Speed |
|---|---|
| RIP | Slow |
| RIPv2 | Slow |
| EIGRP | Fast |
| OSPF | Fast |
| IS-IS | Fast |
| BGP | Slow |
Proprietary and Open Protocols
The important aspects of routing protocols are that they are fast and that they are classless. Three routing protocols fit that description: OSPF, IS-IS, and EIGRP. All three protocols are wholly acceptable; however, there are some small differences between them from a support perspective.
OSPF and IS-IS are public standards, and are therefore supported on a wider variety of equipment than proprietary protocols. This protects against incompatibilities with legacy equipment or "vendor lock-in." On the other hand, these protocols can be complicated to build and maintain.
EIGRP is the easiest to configure of the three, as it does many smart things automatically. EIGRP, however, is a Cisco proprietary protocol and using it locks you in to Cisco equipment.
Obviously, different organizations will weigh factors such as ease of use and public standards. The "best" protocol is the one that is most appropriate for a given situation.
Table 1-8 shows the routing protocols and points out which are proprietary.
| Protocol | Proprietary |
|---|---|
| RIP | No |
| RIPv2 | No |
| EIGRP | Yes |
| OSPF | No |
| IS-IS | No |
| BGP | No |
Summarizing Routing Protocol Characteristics
Older routing protocols (RIP versions 1 and 2 and IGRP) are slow and modern routing protocols (OSPF, IS-IS, EIGRP, and BGP) are fast. Older routing protocols are slow because they send a full copy of all their information periodically. These older protocols, like RIP and IGRP, have to use that periodic transmission as both a routing advertisement and a keepalive message (to let the receiver know that they are still alive). Because they are sending a lot of information, they talk less often (every 30 seconds for RIP). In addition to being slow, they also consume a lot of bandwidth relative to their function.
Modern routing protocols are fast because they separate the keepalive and update functions. Updates are only sent when connections change and new networks need to be advertised or old networks need to be withdrawn. Otherwise, routers simply have to verify that their neighbors are still alive. Because they send small keepalives, routers can afford to check on each other more often (every 5 seconds for EIGRP).
This distinction is at the heart of what makes modern routing protocols so much faster than their predecessors.
RIP and IGRP are older distance vector routing protocols that are slow and classful. There is no reason to run either of these today. Some legacy systems—such as some UNIX systems—expect to learn their default gateway by eavesdropping on RIP advertisements. If you have to deploy RIP, RIPv2 at least has the advantage of being classless.
EIGRP is a modern distance vector routing protocol. It is classless and fast, easy to set up and maintain, but is proprietary to Cisco. Some organizations refuse to consider proprietary standards. The counter argument to this, however, is that EIGRP provides equivalent performance to OSPF but requires less expertise and less time to maintain. By far the most expensive part of your network is the people it takes to maintain it, so this is a powerful argument.
OSPF is a modern classless and fast link-state routing protocol. The "O" stands for "open," meaning public standard. OSPF, however, has a steep learning curve and uses more processor time and memory than EIGRP. If your organization supports a heterogeneous mixture of routers, or has chosen to abstain from proprietary protocols for philosophical reasons, OSPF is a good fit.
IS-IS was developed to compete with OSPF and the two protocols are similar in more ways than they are dissimilar. Today it is moderately difficult to find anyone who has experience working with IS-IS, which makes IS-IS a difficult choice. In every other regard—it is open, fast, and classless—it is a great routing protocol. There is still some interest in IS-IS because it can be adapted to support MPLS and to support IPv6, and, probably because of that, IS-IS is included on this test.
There are only two good reasons to choose one interior routing protocol over another: because it is fast and because it is classless. EIGRP and OSPF each meet these criteria. The other reasons to prefer one over another are largely based on situational requirements or company philosophy. It is not that those values are not important, just that they are not quantifiable. For instance, EIGRP and OSPF are both fine choices, but if your organization does not use proprietary standards then you must go with OSPF. In this case, you are not choosing OSPF because EIGRP does not work equally well, but rather because it is not as good a fit for the policies and management objectives of your company.
BGP is the routing protocol used between autonomous systems in the public Internet and you will have to use it if you connect your network to the Internet.
This book analyzes the modern routing protocols—EIGRP, OSPF, IS-IS, and BGP—and then talks about how to use them cooperatively. There are situations where you must run more than one—for instance, you might run RIP to support an old UNIX host, OSPF for internal routes, and BGP to connect to the Internet.







