Foundation Topics
Introduction to IPv6
This section introduces the features of IPv6 and its need for a larger address space.
The Need for a Larger Address Space
IPv6 has been under development for many years—since the mid 1990s—and has variously been billed as the protocol that would expand the IP address space, bring mobile IP to maturity, or finally incorporate security at Layer 3. While these statements are all true, many of the capabilities of IPv6 have been back-ported to IPv4 over the years. However, IPv4 addresses are now scarce, and the main reason that the Internet will transition to IPv6 is that more addresses will be available.
One reason that IPv4 addresses are scarce is that they are not assigned efficiently. Class A addresses (/8) are too big for most organizations (supporting 16,777,214 host addresses) while Class C addresses (/24, supporting 254 host addresses) are too small to allow even small organizations to grow. As a result, most organizations request Class B addresses (/16, supporting 65,534 host addresses), but they use only a fraction of their assigned space.
Initially, every IP device required a unique public address. To forestall the day when the pool of public IPv4 addresses would be depleted, the Internet Engineering Task Force (IETF) adopted classless interdomain routing (CIDR), variable-length subnet mask (VLSM), classless routing, and Network Address Translation (NAT). CIDR and VLSM work together to allow greater flexibility in address assignment, while NAT hides clients and minimizes the need for public addresses.
Another reason for IPv4 address scarcity is that they have not been assigned evenly across the globe. Citizens and corporations in the United States—the home to the early Internet—were the primary benefactors of early assignments, and a large portion of new addresses continue to go to North America. Europe—next in line on the Internet—has the next largest portion of addresses, while Asia has an insufficient number of addresses relative to its population. Although the perception in the United States might be that IPv4 still has "elbow room," internationally—specifically in Asia—there is already a recognition of the need to move beyond IPv4.
Continuing with this idea that the Internet needs more IP addresses, consider that the world population is about 6.6 billion, of which about 1 billion are "online" already. Given the proliferation of IP-ready devices, many users will need more than one IP address simultaneously, especially as IP moves into consumer electronics such as home entertainment centers and phones. It is certainly beyond a doubt that IP usage will continue to accelerate.
This need for IP addresses could be mitigated somewhat by using NAT and temporary address allocation via Dynamic Host Configuration Protocol (DHCP), but having intermediate devices manipulate packets complicates design and troubleshooting, and interferes with end-to-end encryption and quality of service. The Internet is designed as a peer-to-peer network with dumb intermediate systems; because NAT works against that design, it is at best a necessary evil.
IPv6 Features
Probably the most noticeable feature of IPv6 is its larger, 128-bit addresses, making 2128 (or 3.4 * 1038) unique IPv6 addresses available. While it is reasonable to note that some IPv6 addresses are reserved for multicasting and other special functions, with 6.6 billion people in the world, there are approximately 5 * 1028 IPv6 addresses for each of us—hopefully enough for the foreseeable future!
Note
The total number of IPv4 addresses is 232 (or 4 * 109); when reserved addresses are considered, approximately two billion (2 * 109) usable addresses remain.
IPv6 also includes a simplified packet header, which is described in detail in the next section. This simpler header can be processed more efficiently and provides a flexible extension mechanism for support of other features.
One of these features is mobility; mobile IP is an IETF standard that allows people with wireless devices to stay connected, transparently, as they move around. Mobile IPv6 is described in the "IPv6 Mobility" section later in this chapter.
Security—a hot topic these days—is built-in to IPv6. IP security (IPsec) is therefore available on every IPv6 device, and its use should make IPv6 networks more secure.
Because migration from the current IPv4 Internet to IPv6 will not happen overnight, clever ways are needed to manage the transition. As described in Chapter 21, "IPv6 Routing Protocols, Configuration, and Transitioning from IPv4," tunneling, dual stack, and translation are three ways this migration can be accomplished.
Taking into account all of the IPv6 features, the United States Congress has set 2008 as when the U.S. Department of Defense will have its systems IPv6-compatible, with other departments sure to follow. Meanwhile, Japan, China, and other countries—including some in the European Union—are moving to IPv6 now.
The IPv6 Packet Header
As mentioned earlier, although an expanded address space is the main reason that the Internet will transition to IPv6, IPv6 has many other features that reflect the experience gained over thirty years of using IPv4. These advanced features can be seen in the IPv6 packet header, illustrated in Figure 20-1, and by looking at what has changed from IPv4.
Figure 20-1. IPv6 Header

The fields in the IPv6 header are described as follows:
Version— A 4-bit field, set to the number six for IPv6.
Traffic Class— Also called priority. Similar to the type of service (ToS) field in IPv4, this 8-bit field describes relative priority and is used for quality of service (QoS).
Flow Label— The 20-bit flow label allows traffic to be tagged so that it can be handled faster, on a per-flow basis; this field can also be used to associate flows with traffic classes.
Payload Length— This 16-bit field is the length of the data in the packet.
Next Header— Like the protocol field in the IPv4 header, this 8-bit field indicates how the fields after the IPv6 basic header should be interpreted. It could indicate that the following field is transmission control protocol (TCP) or user datagram protocol (UDP) transport layer information, or it could indicate that an extension header is present.
Hop Limit— Similar to the time to live (TTL) field of IPv4, this 8-bit field is decremented by intermediate routers and, to prevent looping, the packet is discarded and a message is sent back to the source if this field reaches zero.
Source Address and Destination Address— These 128-bit fields are the IPv6 source and destination addresses of the communicating devices.
Extension Headers— Zero or more extension headers follow the basic IPv6 header (for example, before the transport layer data). The next header field within an extension header points to the next header in the chain. The extension headers (in their suggested order) could include:
- - Hop-by-Hop options— Options for intermediate routers along the path.
- - Destination options— Options for the end node (and intermediate routers if the routing header is also present).
- - Routing— Used to specify intermediate routers that the route must include; the effect is to force routing along an administratively defined path.
- - Fragment— Used to divide packets that are too large for the maximum transmission unit (MTU) of a link along the path. This header replaces the fragmentation fields of the IPv4 packet header.
- - Authentication and Encapsulating Security Payload (ESP)— Used by IPsec to provide packet authentication, integrity, and confidentiality. The authentication header (AH) and ESP header are identical in IPv4 and IPv6.
- - Hop-by-Hop options— Options for intermediate routers along the path.
The IPv6 header is optimized for 32- and 64-bit processors, and the extension headers allow for expandability without forcing unused fields to be constantly transmitted.
What has changed between the IPv4 and IPv6 headers? The source and destination addresses are larger, of course. Three other changes are apparent: checksum, fragmentation, and the flow label. These changes are described in the following sections.
Checksum
In IPv4, each packet includes a header checksum. Since intermediate routers decrement the TTL, they also have to recalculate the checksum each time they handle a packet, resulting in more processing resources being used throughout the network. Since upper layer protocols perform a checksum anyway, the IPv6 header does not include a checksum field; this results in more efficient forwarding.
Fragmentation
There are two changes to the way fragmentation behaves in IPv6, as follows:
Fragmentation information has been moved to an extension header.
Intermediate routers no longer fragment packets. If fragmentation is required, it is performed by the source node, reducing the processing burden on the network.
A discovery process determines the optimum MTU to use during a given session. First, the source IPv6 device attempts to send a packet. If the device receives an Internet Control Message Protocol (ICMP) "packet too big" message, which includes the proper MTU size for the path, it retransmits the MTU discovery packet with the smaller MTU. This process is repeated until the device receives a response stating the discovery packet arrived at its final destination successfully. The source sets the resulting MTU as the MTU for the session, and caches its value. The MTU is based on destination address or flow label, or if source-based routing is performed, on source address. Devices perform the MTU discovery process every five minutes to see whether it has changed. If, for some reason, upper layers do not accept MTU change notifications from the IPv6 layer, IPv6 has a mechanism to fragment large packets; however, upper layers should avoid sending messages that require fragmentation.
Flow Label
The flow label field allows flows to be tagged as they enter the network so that similar traffic may be tagged and switched quickly along a path instead of being examined at each intermediate router. The flow label may also be associated with a particular QoS treatment.
IPv6 Addressing
This section explains how IPv6 addresses are represented, describes the types of addresses, and discusses the interface identifiers used in IPv6 addresses. The details of the various IPv6 address types are presented below.
Representing IPv6 Addresses
Instead of using the IPv4 dotted decimal format, IPv6's 128-bit addresses are represented in hexadecimal format, with colons between each of the eight 16-bit fields. Since each hexadecimal digit maps to four bits, each 16-bit field is four digits long. An example of an IPv6 address is 2001:0000:0001:0002:0000:0000:0000:ABCD. Fortunately, there are ways to shorten this representation—imagine trying to ping that address!
There are two ways that an IPv6 address may be represented in a more compact, human-readable, form. First, leading zeros in each 16-bit field may be omitted. Doing so changes the previous address to 2001:0:1:2:0:0:0:ABCD. Secondly, once, and only once, in an address, sequential zeros can be replaced with a pair of colons (::). Using this shortcut changes the example address to 2001:0:1:2::ABCD. Note that only one pair of colons can be used within an IPv6 address. This is because the number of missing 0s is calculated by separating the two parts of the address and filling in 0s, until there are a total of 128 bits. If an address had two :: notations, it would be impossible to determine the size of each block of 0s.
Types of IPv6 Addresses
IPv6 supports three types of addresses:
Unicast— For sending to a single interface. The two currently defined types of unicast addresses are global-aggregatable unicast (also known as global unicast) and link-local unicast.
Multicast— For sending to all of the interfaces in a group. An IPv6 multicast address identifies a set of interfaces on different devices.
Anycast— For sending to the nearest interface in a group. An IPv6 anycast address also identifies a set of interfaces on different devices; however, a packet sent to an anycast address goes only to the nearest interface, as determined by the routing protocol in use. Therefore, all nodes with the same anycast address should provide the same service.
An interface can have several addresses, including a link-local address, any global unicast or anycast addresses assigned, a loopback address (::1/128), the all-nodes multicast addresses, solicited-nodes multicast addresses, and any other multicast addresses to which the node is assigned. In addition, routers must recognize the subnet-router anycast address and the all-routers multicast addresses. The details of these address types are provided later in this chapter.
Note
All systems support the loopback address, ::1/128, representing an imaginary interface that a system may use to send traffic to itself. The loopback address is never used as a source IP address and routers should not forward traffic to or from the loopback address.
Multicast addresses are in the range FF00::/8. All other IPv6 addresses are in the IPv6 unicast address space; anycast addresses are allocated from this same address space.
Broadcast addresses do not exist in IPv6. Broadcasts can be thought of as a special case of multicasting, where every device is the intended recipient. In IPv4, sending a broadcast causes all devices to process the packet, even those that are not concerned with the contents. Using multicasts is much more efficient because the packets can be targeted to a subset of devices, such as routers running Open Shortest Path First (OSPF).
IPv6 Interface Identifiers
Interface identifiers (IDs) in IPv6 addresses are used to identify a unique interface on a link and are sometimes referred to as the "host portion" of the IPv6 address. Interface IDs must be unique on a link. They are always 64-bits long and can be dynamically created, based on the data-link layer address.
The specific data link layer type of the interface determines how the IPv6 interface IDs are dynamically created and how address resolution works. For Ethernet, the interface ID is based on the media access control (MAC) address of the interface, in a format called the extended universal identifier 64-bit (EUI-64) format. The EUI-64 format interface ID is derived from the 48-bit MAC address by inserting the hexadecimal number FFFE between the organizationally unique identifier (OUI) field (the upper three bytes) and the vendor code (the lower three bytes) of the MAC address. The seventh bit in the first byte of the resulting interface ID, corresponding to the Universal/Local (U/L) bit, is set to binary 1. Figure 20-2 illustrates this process.
Figure 20-2. Creating an EUI-64 Format Interface ID for IPv6 Addresses
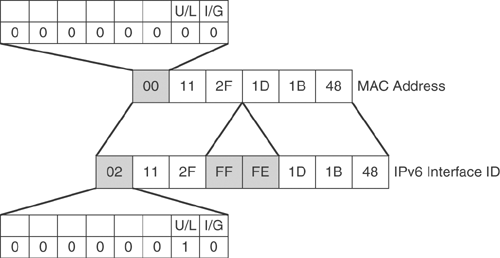
The U/L bit indicates whether the interface ID is locally unique (on the link only) or universally (globally) unique; IDs derived from universally unique MAC addresses are assumed to be globally unique.
The eighth bit in the first byte of the interface ID is the individual/group (I/G) bit for managing multicast groups; it is not changed.
Note
On Ethernet, the first bit of the MAC address transmitted is the I/G bit, used for broadcast and multicast addresses. The second bit transmitted is the U/L bit, used to identify whether the MAC is assigned by the manufacturer (and therefore globally unique) or locally created. Since Ethernet transmits the low-order bit of each byte first, the U/L bit is the seventh bit of the address and I/G is eighth bit of the address.
IPv6 Unicast Addresses
This section describes the two types of IPv6 unicast addresses: global aggregatable and link-local.
Note
Older specifications mentioned two other types of IPv6 unicast addresses which have now been deprecated, in RFC 4291, IP Version 6 Addressing Architecture. These addresses are mentioned here for your information only.
IPv4-compatible IPv6 addresses were made by concatenating 0::/96 and the IPv4 address. For instance, the IPv4 address 192.168.9.5 became 0::C0A8:0905, because 192.168.9.5 is C0A8:0905 in hexadecimal.
Site-local addresses were similar to the IPv4 private addresses and were created by concatenating the prefix FEC0::/10 with a 54-bit subnet and a 64-bit interface ID.
IPv6 Global Aggregatable Unicast Addresses
As has been repeated several times in this book, scalability is an emergent property of summarization. This is just as true for IPv6 as for IPv4. As in IPv4, the far-left bits of IPv6 addresses indicate the routing prefix and may be summarized. Theoretically, there are 264 IPv6 prefixes. If each prefix were stored in router memory using 256 bits (32 bytes), then the routing table would consume 5.9 * 1020 bytes! Therefore, addresses must be deployed hierarchically and summarized, or the number of networks could grow to be too large for routers to track.
Figure 20-3 shows the IPv6 global-aggregatable unicast address structure as described by RFC 3587, IPv6 Global Unicast Address Format. The IPv6 global unicast address is similar to the IPv4 global unicast address.
Figure 20-3. IPv6 Global Aggregatable Unicast Address Structure

The first 48 bits of the IPv6 global unicast address are used for global routing at the Internet Service Provider (ISP) level. The next 16 bits are the subnet ID, allowing an enterprise to subdivide their network. The final 64 bits are the interface ID, typically in EUI-64 format.
The Internet Assigned Numbers Authority (IANA) is currently assigning addresses that start with the binary value 001, which is 2000::/3, for IPv6 global unicast addresses. This is one-eighth of the total IPv6 address space. The IANA is currently allocating address space in the 2001::/16 ranges to the registries. Registries typically have a /23 range, and allocate /32 ranges to ISPs.
For example, an ISP might assign 2001:0:1AB::/48 to an organization. In a network assigned subnet 5, the prefix would be 2001:0:1AB:5::/64. On a device with a MAC address 00-0F-66-81-19-A3, the EUI-64 format interface ID would be 020F:66FF:FE81:19A3. The complete IPv6 global unicast address of the device would therefore be 2001:0:1AB:5:20F:66FF:FE81:19A3.
Note
In the now obsolete RFC 2374, An IPv6 Aggregatable Global Unicast Address Format, two other fields were included in the global prefix: the Top-Level Aggregator and the Next-Level Aggregator. Some early IPv6 networks may still use these fields, but they are no longer included in the latest RFC 3587, IPv6 Aggregatable Global Unicast Address Format.
IPv6 Link-Local Unicast Addresses
Link-local unicast addresses allow devices on the same local network to communicate, without requiring them to have global unicast addresses. Link-local addresses are used by routing and discovery protocols and are autoconfigured using the FE80::/10 prefix and the EUI-64 format interface ID, as shown in Figure 20-4.
Figure 20-4. IPv6 Link-Local Address Structure
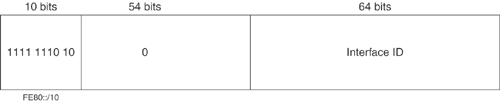
For example, on an interface with the MAC address 00-0F-66-81-19-A3, the link-local address would be FF80::020F:66FF:FE81:19A3.
Note
RFC 4291 also specifies another unicast address, the IPv4-mapped IPv6 address, formed by concatenating 0::FFFF:0:0/96 with an IPv4 address. For instance, 10.0.0.1 becomes 0::FFFF:A00:1, because 10.0.0.1 is 0A00:0001 in hexadecimal. This address can be used by dual-stack hosts (those running both IPv4 and IPv6).
IPv6 Anycast Addresses
An IPv6 anycast address is a global unicast address that is assigned to two or more devices. Other devices route to the closest active device with the anycast address; the routing protocol metric determines which is closest.
Figure 20-5 shows an example network topology from which there are two connections to an ISP. Both border routers have been configured with the same IPv6 anycast address; the internal routers simply route the client to the closest one (Router A in this case). If Router A goes down, then Router B becomes the closest, and routing reconverges toward Router B. This technique automatically load-balances traffic toward the closest exit and provides redundancy in case an exit router goes down.
Figure 20-5. Anycast Addresses Route Toward the Closest Active Device
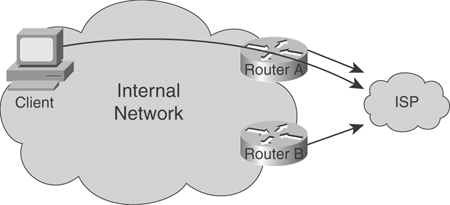
Anycast addresses are created by assigning the same unicast address to more than one device; there is no reserved address space for anycast. Nodes on which the address is assigned must be explicitly configured to use and know that the address is an anycast address.
All routers must support the subnet-router anycast address for the subnets on which they have interfaces. The subnet-router anycast address is the unicast address of the subnet with the interface ID (the host bits) set to zero. For example, a router with an IPv6 interface address 2001:0:1:5:20F:66FF:FE81:19A3 must support the anycast address 2001:0:1:5::. Packets sent to the subnet-router anycast address will be delivered to one router on the subnet.
IPv6 Multicast Addresses
A multicast address identifies a group of interfaces; traffic sent to the group goes to all of the interfaces. Interfaces can belong to many multicast groups simultaneously.
Each interface should recognize several multicast addresses, including the all-nodes multicast, the solicited-nodes multicast, and any other group addresses to which the node belongs. Routers should also recognize the all-routers multicast address. Figure 20-6 illustrates the format of an IPv6 multicast address.
Figure 20-6. IPv6 Multicast Address

As shown in Figure 20-6, all IPv6 multicast addresses start with the prefix FF00::/8. The next four bits are flags, which are described in the following list:
The first flag bit is currently undefined and always set to zero.
The second flag bit is known as the "R" bit; it is set to binary 1 if the multicast rendezvous point (RP) address is embedded in the multicast address (as defined in RFC 3956, Embedding the Rendezvous Point (RP) Address in an IPv6 Multicast Address). Chapter 19, "Configuring Multicast," describes RPs.
The third flag bit is known as the "P" bit; it is set to binary 1 if the multicast address is assigned based on the unicast prefix (as defined in RFC 3306, Unicast-Prefix-based IPv6 Multicast Addresses).
The fourth flag bit is known as the "T" bit; it is set to binary 0 if the address is permanently assigned or to binary 1 if the address is temporary (as defined in RFC 4291).
The four bits after the flags indicate the scope of the address, limiting how far the multicast may travel. IPv4 uses TTL as a crude way to accomplish this, but there are times when the distance allowed by TTL is too far in one direction and not far enough in another. The IPv6 multicast scope is flexible enough to limit the multicast to a link, to a site, or to an enterprise. The currently defined scope values, in hexadecimal, are as follows:
1: interface-local scope; used for loopback transmission
2: link-local scope; similar to unicast link-local scope
4: admin-local scope; must be administratively configured
5: site-local scope; spans a single site
8: organization-local scope; spans multiple sites belonging to an organization
E: global scope
The multicast group ID is the lower 112 bits of the address.
All devices should recognize and respond to the all-nodes multicast addresses:
FF01::1 is interface-local.
FF02::1 is link-local.
Solicited-node multicast addresses are used in neighbor solicitation messages, and are sent on a local link by a device that wants to determine the data-link layer address of another device on the same local link, similar to the Address Resolution Protocol (ARP) in IPv4. A solicited-node multicast address is formed by starting with the prefix FF02::1:FF00:/104 and appending the last 24 bits of the corresponding unicast or anycast address of the device. Nodes are required to join the associated solicited-nodes group for each unicast and anycast address they support.
Routers should also recognize and respond to the all-routers multicast addresses:
FF01::2 is an interface-local address.
FF02::2 is a link-local address.
FF05::2 is a site-local address.
Routers will also join other groups to support routing protocols; for example, OSPF version 3 (OSPFv3) uses FF02::5 and FF02::6, and Routing Information Protocol (RIP) new generation (RIPng) uses FF02::9.
IPv6 Address Assignment
IPv6 addresses may be manually assigned, or dynamically assigned through DHCP version 6 (DHCPv6) or stateless autoconfiguration. If an address is manually defined, take care to ensure it is unique.
Stateless Autoconfiguration
For stateless autoconfiguration, each router advertises network information (either periodically or upon a request from a host), including the 64-bit prefix, on each of its links. By listening for this advertisement, end-systems create a unique address by concatenating the prefix and the EUI-64 format interface ID. This process is referred to as stateless autoconfiguration because no device tracks the state of particular addresses.
End-systems request network information using a router solicitation message, and routers reply with a router advertisement message. A process called duplicate address detection (DAD) detects and avoids duplicate addresses.
This same feature can be used to renumber a network by changing the network information on only the routers. When the routers advertise the new prefix information, the end-systems autoconfigure themselves with the new network number.
DHCPv6 and Stateless DHCPv6
The abilities to control which devices get addresses and track the address assignments for auditing purposes are important issues that can be accomplished using DHCPv6. Ironically, privacy is another reason that DHCPv6 could be a good idea. Normally IPv6 addresses contain the MAC address, a unique ID that can be linked back to a specific system. DHCPv6 could be used to break the link between the MAC address and the Layer 3 address.
Stateless DHCPv6 is a method between stateless autoconfiguration and stateful DHCPv6; stateless DHCPv6 is also known as DHCP-lite and is defined in RFC 3736, Stateless Dynamic Host Configuration Protocol (DHCP) Service for IPv6.
IPv6 Mobility
The IPv6 mobility feature, defined in RFC 3775, Mobility Support in IPv6, allows users to stay connected while moving about the network.
An IPv6 mobile node has a home address on its home network and a care-of address on its current network. A node communicating with a mobile node is called a correspondent node of the mobile node. The association between the home address and the care-of address of a mobile node is known as a binding. When a mobile node roams away from its home network, it sends a binding update to its home agent, a router on its home network.
There are two ways that a mobile node and a correspondent node can communicate—via the home agent or directly.
In the first case, packets from the correspondent node are routed to the home agent and then tunneled to the mobile node. Packets to the correspondent node are tunneled from the mobile node to the home agent and then routed normally from the home network to the correspondent node.
In the second case, when the mobile node first receives a packet from the correspondent node, it sends a binding update to the correspondent node. Packets from the correspondent node can then be routed directly to the care-of address of the mobile node and all traffic flows directly between the correspondent node and the mobile node. Figure 20-7 illustrates an example of a mobile node that has moved from one network to another.
Figure 20-7. IPv6 Mobility

If the mobile node moves—and that is what being mobile is all about—it sends a binding update to its home agent and to all correspondent nodes.







