1.2 Three-Tier Architectures
This book shows you how to develop web database applications that are built around the three-tier architecture model shown in Figure 1-3. At the base of an application is the database tier, consisting of the database management system that manages the data users create, delete, modify, and query. Built on top of the database tier is the middle tier , which contains most of the application logic that you develop. It also communicates data between the other tiers. On top is the client tier , usually web browser software that interacts with the application.
Figure 1-3. The three-tier architecture model of a web database application
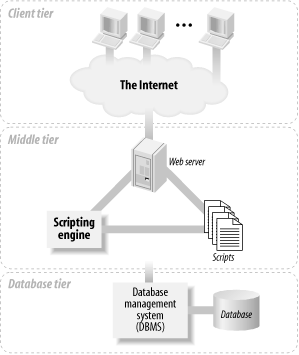
The three-tier architecture is conceptual. In practice, there are different implementations of web database applications that fit this architecture. The most common implementation has the web server (which includes the scripting engine that processes the scripts and carries out the actions they specify) and the database management system installed on one machine: it's the simplest to manage and secure, and it's our focus in this book. With this implementation on modern hardware, your applications can probably handle tens of thousands of requests every hour.
For popular web sites, a common implementation is to install the web server and the database server on different machines, so that resources are dedicated to permit a more scalable and faster application. For very high-end applications, a cluster of computers can be used, where the database and web servers are replicated and the load distributed across many machines. Our focus is on simple implementations; replication and load distribution are beyond the scope of this book.
Describing web database applications as three-tier architectures makes them sound formally structured and organized. However, it hides the reality that the applications must bring together different protocols and software, and that the software needs to be installed, configured, and secured. The majority of the material in this book discusses the middle tier and the application logic that allows web browsers to work with databases.
1.2.1 HTTP: the Hypertext Transfer Protocol
The three-tier architecture provides a conceptual framework for web database applications. The Web itself provides the protocols and network that connect the client and middle tiers of the application: it provides the connection between the web browser and the web server. HTTP is one component that binds together the three-tier architecture.
HTTP allows resources to be communicated and shared over the Web. Most web servers and web browsers communicate using the current version, HTTP/1.1. A detailed knowledge of HTTP isn't necessary to understand the material in this book, but it's important to understand the problems HTTP presents for web database applications. (A longer introduction to the underlying web protocols can be found in Appendix D.)
1.2.1.1 HTTP example
HTTP is conceptually simple: a web browser sends a request for a resource to a web server, and the web server sends back a response. For every request, there's always one response. The HTTP response carries the resource?the HTML document, image, or output of a program?back to the web browser.
An HTTP request is a textual description of a resource, and additional information or headers that describe how the resource should be returned. Consider the following example request:
GET /~hugh/index.html HTTP/1.1 Host: goanna.cs.rmit.edu.au From: hugh@hughwilliams.com (Hugh Williams) User-agent: Hugh-fake-browser/version-1.0 Accept: text/plain, text/html
This example uses a GET method to request an HTML page /~hugh/index.html from the server goanna.cs.rmit.edu.au with HTTP/1.1. In this example, four additional header lines specify the host, identify the user and the web browser, and define what data types can be accepted by the browser. A request is normally made by a web browser and may include other headers.
An HTTP response has a response code and message, additional headers, and usually the resource that has been requested. Part of the response to the request for /~hugh/index.html is as follows:
HTTP/1.1 200 OK
Date: Thu, 04 Dec 2003 04:30:02 GMT
Server: Apache/1.3.27 (Unix)
Last-Modified: Fri, 21 Nov 2003 22:26:07 GMT
ETag: "a87da0-2128-3fbe90ff"
Accept-Ranges: bytes
Content-Length: 8488
Content-Type: text/html
<!DOCTYPE HTML PUBLIC
"-//W3C//DTD HTML 4.0 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
...The first line of the response tells the browser that the response is HTTP/1.1 and confirms that the request succeeded by reporting the response code 200 and the message OK. In this example, seven lines of additional headers identify the current date and time, the web server software, the last date and time the page was changed, an entity tag (ETag) that is used for caching, an instruction to the browser on how to request part of the document, the length of the response, and the content type. After a blank line, the resource itself follows, and we've shown only the first few lines. In this example the resource is the requested HTML document, /~hugh/index.html.
1.2.2 State
Traditional database applications are stateful. Users log in, run related transactions, and then log out when they are finished. For example, in a bank application, a bank teller might log in, use the application through a series of menus as he serves customer requests, and log out when he's finished for the day. The bank application has state: after the teller is logged in, he can interact with the application in a structured way using menus. When the teller has logged out, he can no longer use the application.
HTTP is stateless. Any interaction between a web browser and a web server is independent of any other interaction. Each HTTP request from a web browser includes the same header information, such as the security credentials of the user, the types of pages the browser can accept, and instructions on how to format the response. The server processes the headers, formulates a response that explains how the request was served, and returns the headers and a resource to the browser. Once the response is complete, the server forgets the request and there's no way to go back and retrieve the request or response.
Statelessness has benefits: the most significant are the resource savings from not having to maintain information at the web server to track a user or requests, and the flexibility to allow users to move between unrelated pages or resources. However, because HTTP is stateless, it is difficult to develop stateful web database applications: for example, it's hard to force a user to follow menus or a series of steps to complete a task.
To add state to HTTP, you need a method to impose information flows and structure. A common solution is to exchange a token or key between a web browser and a web server that uniquely identifies the user and her session . Each time a browser requests a resource, it presents the token, and each time the web server responds, it returns the token to the web browser. The token is used by the middle-tier software to restore information about a user from her previous request, such as which menu in the application she last accessed.
Exchanging tokens allows stateful structure such as menus, steps, and workflow processes to be added to the application. They can also be used to prevent actions from happening more than once, time out logins after a period of inactivity, and control access to an application.
1.2.3 Thickening the Client in the Three-Tier Model
Given that a web database application built with a three-tier architecture doesn't fit naturally with HTTP, why use that model at all? The answer mostly lies in the popularity and standardization of web browsers: any user who has a web browser can use the web database application, and usually without any restrictions. This means an application can be delivered to any number of diverse, dispersed users who use any platform, operating system, or browser software. This advantage is so significant that our focus in this book is entirely on three-tier solutions that use a web browser as the client tier.
Web browsers are thin clients . This means almost no application logic is included in the client tier. The browser simply sends HTTP requests for resources and then displays the responses, most of which are HTML pages. This thin client model means you don't have to build, install, or configure the client tier, but that you do need to build almost all of your application to run in the middle tier.
You can thicken the client tier to put more work on the browser. Using popular technologies such as Java, JavaScript, and Macromedia Flash, you can develop application components that process data independently of the web server or preprocess data before sending it to the server.
JavaScript is particularly good for many tasks because it's easy to use, open source, and built into all popular browsers (although users can turn it off). It's often used to validate data that's typed into forms before it's sent to the server, highlight parts of a page when the mouse passes over, display menus, and perform other simple tasks. However, it's limited in the information it can store and it can't communicate with a database server. Therefore, although you shouldn't depend on JavaScript to do critical tasks, it's useful for preprocessing and it's another important technology we discuss in Chapter 7.
1.2.4 The Middle Tier
The middle tier has many roles in a web database application. It brings together the other tiers, drives the structure and content of the data displayed to the user, provides security and authentication, and adds state to the application. It's the tier that integrates the Web with the database server.
1.2.4.1 Web servers
There are essentially two types of request made to a web server: the first asks for a file?often a static HTML web page or an image?to be returned, and the second asks for a program or script to be run and its output to be returned. We've shown you a simple example previously in this chapter, and simple requests for files are further discussed in Appendix D. HTTP requests for PHP scripts require a server to run PHP's Zend scripting engine, process the instructions in the script (which may access a database), and return the script output to the browser to output as plain HTML.
Apache is an open source, fast, and scalable web server. It can handle simultaneous requests from browsers and is designed to run under multitasking operating systems such as Linux, Mac OS X, and Microsoft Windows. It has low resource requirements, can effectively handle changes in request loads, and can run fast on even modest hardware. It is widely used and tested. The current release at the time of writing is 2.0.48.
Conceptually, Apache isn't complicated. On a Unix platform, the web server is actually several running programs, where one coordinates the others and doesn't serve requests itself. The other server programs notify their availability to handle requests to the coordinating server. If too few servers are available to handle incoming requests, the coordinating server may start new servers; if too many are free, it may kill spare servers to save resources.
Apache's configuration file controls how it listens on the network and serves requests. The server administrator controls the behavior of Apache through more than 150 directives that affect resource requirements, response time, flexibility in dealing with request load variability, security, how HTTP requests are handled and logged, how scripting engines are used to run scripts, and most other aspects of its operation.
The configuration of Apache for most web database applications is straightforward. We discuss how to install Apache in Appendix A through Appendix C, how to hide files that you don't want to serve in Chapter 6, and the features of a secure web server in Chapter 11. We discuss the HTTP protocol and how it's implemented in Appendix D. More details on Apache configuration can be found in the resources listed in Appendix G.
1.2.5 Web Scripting with PHP
PHP is the most widely supported and used web scripting language and an excellent tool for building web database applications. This isn't to say that other scripting languages don't have excellent features. However, there are many reasons that make PHP a good choice, including that it's:
- Open source
-
Community efforts to maintain and improve it are unconstrained by commercial imperatives.
- Flexible for integration with HTML
-
One or more PHP scripts can be embedded into static HTML files and this makes client tier integration easy. On the downside, this can blend the scripts with the presentation; however the template techniques described in Chapter 7 can solve most of these problems.
- Suited to complex projects
-
It is a fully featured object-oriented programming language, with more than 110 libraries of programming functions for tasks as diverse as math, sorting, creating PDF documents, and sending email. There are over 15 libraries for native, fast access to the database tier.
- Fast at running scripts
-
Using its built-in Zend scripting engine, PHP script execution is fast and all components run within the main memory space of PHP (in contrast to other scripting frameworks, in which components are in distinct modules). Our experiments suggest that for tasks of at least moderate complexity, PHP is faster than other popular scripting tools.
- Platform- and operating-system portable
-
Apache and PHP run on many different platforms and operating systems. PHP can also be integrated with other web servers.
- A community effort
-
PHP contains PEAR, a repository that is home to over 100 freely available source code packages for common PHP programming tasks.
At the time of writing, PHP4 (Version 4.3.3) was the current version and PHP5 was available for beta testing (Version 5.0.0b2). The scripts in this book have been developed and tested using PHP4, and testing on PHP5 has identified a few limitations. This book describes both versions of PHP: in particular, you'll find a discussion of new object-oriented PHP5 features in Chapter 14. When a feature is only available in PHP5, we tell you in the text. When a PHP4 script or feature doesn't work on PHP5, we explain why and predict how it'll be fixed in the future; it's likely that almost all scripts that run under PHP4 will run under PHP5 in the future.
PHP is a major topic of this book. It's introduced in Chapter 3 through Chapter 5, where we discuss most of the features of the core language. PHP libraries that are important to web database application development are the subject of Chapter 6 and Chapter 8 through Chapter 13. PHP's PEAR package repository is the subject of Chapter 7. An example PHP application is the subject of Chapter 16 to Chapter 20. Appendix A through Appendix C show how to install PHP. Other pointers to web resources, books, and commercial products for PHP development are listed in Appendix G.
A technical explanation of the new features of PHP5 is presented in the next section. If you aren't familiar with PHP4, skip ahead to the next section.
1.2.5.1 Introducing PHP5
PHP4 included the first release of the Zend engine version 1.0, PHP's scripting engine that implements the syntax of the language and provides all of the tools needed to run library functions. PHP5 includes a new Zend engine version 2.0, that's enhanced to address the limitations of version 1.0 and to include new features that have been requested by developers. However, unlike the changes that occurred when PHP3 became PHP4, the changes from PHP4 to PHP5 only affect part of the language. Most code that's written for PHP4 will run without modification under PHP5.
In brief, the following are the major new features in PHP5. Many of these features are explained in detail elsewhere in this book:
- New Object Model
-
Object-oriented programming (OOP) and the OOP features of PHP5 are discussed in detail in Chapter 14. PHP4 has a simple object model that doesn't include many of the features that object-oriented programmers expect in an OOP language such as destructors, private and protected member functions and variables, static member functions and variables, interfaces, and class type hints. All of these features are available in PHP5.
The PHP5 OOP model also better manages how objects are passed around between functions and classes. Handles to objects are now passed, rather than the objects themselves. This has substantially improved the performance of PHP.
- Internationalization
-
Support for non-Western character sets and Unicode. This is discussed in Chapter 3.
- Exception Handling
-
New try...catch, and throw statements are available that are aimed at improving the robustness of applications when errors occur. These are discussed in Chapter 4. There's also a backtrace feature that you can use to develop a custom error handler that shows how the code that caused an error was called. This feature has been back-ported into PHP4 and is discussed in Chapter 12.
- Improved memory handling and speed
-
PHP4 was fast, but PHP5 is faster and makes even better use of memory. We don't discuss this in detail.
- New XML support
-
There were several different tools for working with the eXtensible Markup Language (XML) in PHP4. These tools have been replaced with a single new, robust framework in PHP5. We don't discuss XML support in this book.
- The Improved MySQL library (mysqli)
-
A new MySQL function library is available in PHP5 that supports MySQL 4. The library has the significant feature that it allows an SQL query to be prepared once, and executed many times, and this substantially improves speed if a query is often used. This library is briefly described in Chapter 6, and is the source of many of the PHP4 and PHP5 compatibility problems described throughout in this book.
You can find out more about what's new in PHP5 from http://www.zend.com/zend/future.php.
1.2.6 The Database Tier
The database tier stores and retrieves data. It's also responsible for managing updates, allowing simultaneous ( concurrent) access from web servers, providing security, ensuring the integrity of data, and providing support services such as data backup. Importantly, a good database tier must allow quick and flexible access to millions upon millions of facts.
Managing data in the database tier requires complex software. Fortunately, most database management systems (DBMSs) or servers are designed so that the software complexities are hidden. To effectively use a database server, skills are required to design a database and formulate queries using the SQL language; SQL is discussed in Chapter 5. An understanding of the underlying architecture of the database server is unimportant to most users.
In this book, we use the MySQL server to manage data. It has a well-deserved reputation for speed: it can manage many millions of facts, it's very scalable, and particularly suited to the characteristics of web database applications. Also, like PHP and Apache, MySQL is open source software. However, there are downsides to MySQL that we discuss later in this section.
The first step in successful web database application development is understanding system requirements and designing databases. We discuss techniques for modeling system requirements, converting a model into a database, and the principles of database technology in Appendix E. In this section, we focus on the database tier and introduce database software by contrasting it with other techniques for storing data. Chapter 5 and Chapter 15 cover the standards and software we use in more detail.
There are other server choices for storing data in the database tier. These include search engines, document management systems, and gateway services such as email software. Our discussions in this book focus on the MySQL server in the database tier.
1.2.7 Database Management Systems
A database server or DBMS searches and manages data that's stored in databases. A database is a collection of related data, and an application can have more than one database. A database might contain a few entries that make up a simple address book of names, addresses, and phone numbers. At the other extreme, a database can contain tens or hundreds of millions of records that describe the catalog, purchases, orders, and payroll of a large company. Most web database applications have small- to medium-size databases that store thousands, or tens of thousands, of records.
Database servers are complex software. However, the important component for web database application development is the applications interface that's used to access the database server. For all but the largest applications, understanding and configuring the internals of a database server is usually unnecessary.
1.2.7.1 SQL
The database server applications interface is accessed using SQL. It's a standard query language that's used to define and manipulate databases and data, and it's supported by all popular database servers.
SQL has had a complicated life. It began at the IBM San Jose Research Laboratory in the early 1970s, where it was known as Sequel ; some users still call it Sequel, though it's more correctly referred to by the three-letter acronym, SQL. After almost 16 years of development and differing implementations, the standards organizations ANSI and ISO published an SQL standard in 1986. IBM published a different standard one year later!
Since the mid-1980s, three subsequent standards have been published by ANSI and ISO. The first, SQL-89, is the most widely, completely implemented SQL in popular database servers. Many servers implement only some features of the next release, SQL-2 or SQL-92, and almost no servers have implemented the features of the most recently approved standard, SQL-99 or SQL-3. MySQL supports the entry-level SQL-92 standard and has some proprietary extensions.
Consider an SQL example. Suppose you want to store information about books in a library. You can create a table?an object that's stored in your database?using the following statement:
CREATE TABLE books ( title char(50), author char(50), ISBN char(50) NOT NULL, PRIMARY KEY (ISBN) );
Then, you can add books to the database using statements such as:
INSERT INTO books ("Web Database Apps", "Hugh and Dave", "123-456-N");Once you've added data, you can retrieve facts about the books using queries such as the following that finds the author and title of a book with a specific ISBN:
SELECT author, title FROM books WHERE ISBN = "456-789-Q";
These are only some of the features of SQL, and even these features can be used in complex ways. SQL also allows you to update and delete data and databases, and it includes many other features such as security and access management, multiuser transactions that allow many users to access the same database without corrupting the data, tools to import and export data, and powerful undo and redo features.
SQL is discussed in detail in Chapter 5 and Chapter 15.
1.2.7.2 Why use a database server?
Why use a complex database server to manage data? There are several reasons that can be explained by contrasting a database with a spreadsheet, a simple text file, or a custom-built method of storing data. A few example situations where a database server should and should not be used are discussed later in this section.
Take spreadsheets as an example. Spreadsheet worksheets are typically designed for a specific application. If two users store names and addresses, they are likely to organize data in a different way and develop custom methods to move around and summarize the data. The program and the data aren't independent: moving a column might mean rewriting a macro or formula, while exchanging data between the two users' applications might be complex. In contrast, a database server and SQL provide data-program independence, where the method for storing the data is independent of the language that accesses it.
Managing complex relationships is difficult in a spreadsheet or text file. For example, consider what happens if we want to store information about customers: we might allocate a few spreadsheet columns to store each customer's residential address. If we were to add business addresses and postal addresses, we'd need more columns and complex processing to, for example, process a mail-out to customers. If we want to store information about the purchases by our customers, the spreadsheet becomes wider still, and problems start to emerge. For example, it is difficult to determine the maximum number of columns needed to store orders and to design a method to process these for reporting. In contrast, databases are designed to manage complex relational data.
A database server usually permits multiple users to access a database at the same time in a methodical way. In contrast, a spreadsheet should be opened and written only by one user; if another user opens the spreadsheet, she won't see any updates being made at the same time by the first user. At best, a shared spreadsheet or text file permits very limited concurrent access.
An additional benefit of a database server is its speed and scalability. It isn't totally true to say that a database provides faster searching of data than a spreadsheet or a custom filesystem. In many cases, searching a spreadsheet or a special-purpose file might be perfectly acceptable, or even faster if it is designed carefully and the volume of data is small. However, for managing large amounts of related information, the underlying search structures allow fast searching, and if information needs are complex, a database server should optimize the method of retrieving the data.
There are also other advantages of database servers, including data-oriented and user-oriented security, administration software, portability, and data recovery support. A practical benefit of this is reduced application development time: the system is already built, it needs only data and queries to access the data.
1.2.7.3 Examples of when to use a database server
In any of these situations, a database server should be used to manage data:
There is more than one user who needs to access the data at the same time.
There is at least a moderate amount of data. For example, you might need to maintain information about a few hundred customers.
There are relationships between the stored data items. For example, customers may have any number of related invoices.
There is more than one kind of data object. For example, there might be information about customers, orders, inventory, and other data in an online store.
There are constraints that must be rigidly enforced on the data, such as field lengths, field types, uniqueness of customer numbers, and so on.
New or consolidated information must be produced from basic, related information; that is, the data must be queried to produce reports or results.
There is a large amount of data that must be searched quickly.
Security is important. There is a need to enforce rules as to who can access the data.
Adding, deleting, or modifying data is a complex process.
Adding, deleting, and updating data is a frequent or complex process.
1.2.7.4 Examples of when not to use a DBMS
There are some situations where a relational DBMS is probably unnecessary or unsuitable. Here are some examples:
There is one type of data item, and the data isn't searched. For example, if a log entry is written when a user logs in and logs out, appending the entry to the end of a simple text file may be sufficient.
The data management task is trivial and accessing a database server adds unnecessary overhead. In this case, the data might be coded into a web script in the middle tier.
1.2.7.5 The MySQL server
MySQL has most of the features of high-end commercial database servers, including the ability to manage very large quantities of data. Its design is ideally suited to managing databases that are typical of most web database applications. The current version at the time of writing is MySQL 4.1.
The difference between MySQL and high-end commercial servers is that MySQL's components aren't as mature. For example, MySQL's query evaluator doesn't always develop a fast plan to evaluate complex queries. It also doesn't support all of the features you might find in other servers: for example, views, triggers, and stored procedures are planned for future versions. There are other, more minor limitations that don't typically affect web development. However, even users who need these features often choose MySQL because it's free. (Contrary to popular belief, since 2002, MySQL has supported nested queries, transactions, and row (or record) locking.)
MySQL is another major topic of this book. It's introduced in Chapter 5, and used extensively in examples in Chapter 6 through Chapter 8 and Chapter 11 and Chapter 12. Advanced MySQL features are a subject of Chapter 15. An example application that uses PHP and MySQL is the subject of Chapter 16 through Chapter 20. Appendix A through Appendix C shows how to install MySQL and selected MySQL resources are listed in Appendix G.
A technical explanation of the features of MySQL 4 is presented in the next section. If you aren't familiar with MySQL, skip ahead to the next section.
1.2.7.6 Introducing MySQL 4
MySQL 4 is a major new release that includes important features that have been added since MySQL 3.23. The current version, MySQL 4.1, supports a wide range of SQL queries, including joins, multi-table updates and deletes, and nested queries. At present it supports most features of the SQL 92 standard, and its aim is to fully support SQL 99.
The MySQL server supports several table types that allow a wide range of choice in your applications of locking techniques, transaction environments, and performance choices. It also has good tools for backup and recovery. MySQL is a powerful, fully-featured DBMS that's commercially supported by the company MySQL AB.
In detail, the following are the major features of MySQL 4. Many of these features are explained in detail elsewhere in this book:
- Nested query and derived table support
-
Sub-queries are new in MySQL 4.1. This allows you to use the SQL statements EXISTS, IN, NOT EXISTS, and NOT IN, and it also allows you to include a nested query in the FROM clause that creates a derived table. UNION was introduced in MySQL 4.0. All of these are discussed in detail in Chapter 15.
- Internationalization
-
MySQL 4.1 now supports Unicode, allowing you to develop applications that don't use Western languages. We don't discuss MySQL's use of Unicode in this book, but we do discuss PHP's Unicode support in Chapter 3.
- Query caching
-
MySQL 4.0 introduced a query cache that stores the most-recent results of queries, and intelligently delivers these as answers to identical future queries. We show you how to use this feature in Chapter 15. We explain other speed improvements in the same chapter.
- Transaction-safe InnoDB tables
-
The InnoDB table type was included as a built-in module in MySQL 4.0. InnoDB supports transactions, and allows you to decide whether to commit or rollback a set of writes to the database. It also supports checkpointing, which is used by MySQL to get the database into a known state after a crash or serious error. We explain the advantages and disadvantages of InnoDB in Chapter 15.
- Full text searching
-
MySQL 4 introduced new methods for fast searching of text and a form of search engine-like ranking. We don't discuss this in the book.
MySQL 4 resources are listed in Appendix G.







