15.2 Advanced Querying
In Chapter 5, we covered most of the querying techniques you'll need to develop web database applications. In this section, we show you selected advanced techniques including shortcuts for joins, other join types, how to use aliases, using MySQL's new nested query support, working with user variables, and obtaining subtotals using WITH ROLLUP. This section concludes with a list of what we've omitted, and what MySQL doesn't yet include.
15.2.1 Advanced Join Types
This section introduces you to the INNER JOIN, LEFT JOIN, RIGHT JOIN, and UNION statements. The INNER JOIN statement is a shortcut that can save you some typing (and we use it throughout many examples in this chapter), LEFT JOIN and RIGHT JOIN add new functionality to find rows that don't have a match in another table, and UNION brings together the results from two separate queries.
15.2.1.1 Natural and inner joins
In the Chapter 5, we showed you how to perform a join between two or more tables. For example, to join the customer and orders tables, with the goal of displaying customers who've placed orders, you would type:
SELECT DISTINCT surname, firstname, customer.cust_id FROM customer, orders WHERE customer.cust_id = orders.cust_id;
The join condition in the WHERE clause limits the output to only those rows where there's a matching customer and order (and the DISTINCT clause presents each customer's details once).
We've referred to our example query as a natural join, but this isn't strictly correct. A natural join (which is also introduced in the Chapter 5) produces the same results, but doesn't actually require you to specify what the join condition is. Consider an example:
SELECT DISTINCT surname, firstname, customer.cust_id FROM customer NATURAL JOIN orders;
The MySQL server determines what attributes have the same name in the tables orders and customer, and creates the WHERE clause behind the scenes to join those attributes. For readable queries, we recommend you make your joins explicit by adding the WHERE clause and listing the attributes.
Just to make querying more confusing, the previous examples are also an example of an inner join. You can express the same query using the INNER JOIN syntax and the USING clause:
SELECT DISTINCT surname, firstname, customer.cust_id FROM customer INNER JOIN orders USING (cust_id);
This query matches rows between the customer and orders tables using the cust_id attribute that's common to both tables. It's required that the attribute (or comma-separated) attributes listed in the USING clause are enclosed in brackets. If you leave out the USING clause, you'll get a Cartesian product and that's not what you want.
The join in the previous example is an inner join because only the rows that match between the two tables are output. Customers that haven't placed orders aren't output, and nor are orders that don't have a matching customer. The INNER JOIN with a USING clause can be used interchangeably with the comma-based syntax of the first example in this section (and, for that matter, all joins of two or more tables in Chapter 5). We use the INNER JOIN syntax frequently throughout this chapter.
The USING clause is a handy shortcut when two tables share a join attribute with the same name. When they don't, you can use the ON clause to achieve the same result. Consider an example that joins the wine and wine_type tables to discover the type of wine #100:
SELECT wine_type.wine_type FROM wine INNER JOIN wine_type ON wine.wine_type=wine_type.wine_type_id WHERE wine.wine_id=100;
In general, you should use the ON clause only to specify a join condition. You should use a WHERE clause to specify which rows should be output.
You can have several conditions in an ON clause. For example, to find all of the wines in customer #20's first order, use:
SELECT wine_id FROM orders INNER JOIN items ON orders.order_id=items.order_id AND orders.cust_id=items.cust_id WHERE orders.cust_id=20 AND orders.order_id=1;
In this case, since the attributes have the same name in the two tables, the shortcut with USING works too:
SELECT wine_id FROM orders INNER JOIN items USING (cust_id,order_id) WHERE orders.cust_id=20 AND orders.order_id=1;
15.2.1.2 Left and right joins
The queries in the previous section output rows that match between tables. But what if you want to output data from a table, even if it doesn't have a matching row in the other table? For example, suppose you want to output a list of all countries and the customers who live in that country, and you want to see a country listed even if it has no customers. You can do this with a LEFT JOIN query:
SELECT country, surname, firstname, cust_id FROM countries LEFT JOIN customer USING (country_id);
In part, this outputs the results:
| Australia | Stribling | Michelle | 646 | | Australia | Skerry | Samantha | 647 | | Australia | Cassisi | Betty | 648 | | Australia | Krennan | Jim | 649 | | Australia | Woodburne | Lynette | 650 | | Austria | NULL | NULL | NULL | | Azerbaijan | NULL | NULL | NULL | | Bahamas | NULL | NULL | NULL | | Bahrain | NULL | NULL | NULL | | Bangladesh | NULL | NULL | NULL |
The LEFT JOIN clause outputs all rows from the table listed to the left of the clause. In this example, all countries are listed because the countries is on the left in the clause countries LEFT JOIN customer. When there are no matching rows in the customer table then NULL values are output for the customer attributes. So, for example, none of our customers live in Austria. The syntax of the LEFT JOIN is the same as the INNER JOIN clause, except that a USING or ON clause is required.
The RIGHT JOIN clause is identical, except that it outputs all rows from the table listed to the right of the clause, and NULL values are shown for the table on the left of the clause when there's no matching data. It's included in MySQL for convenience, so that you can write joins with the tables in the order you want in a query. However, we use only LEFT JOIN in our queries to keep things simple.
There's also a variation of NATURAL JOIN that does the same thing as LEFT JOIN:
SELECT country, surname, firstname, cust_id FROM countries NATURAL LEFT JOIN customer;
This just allows you to omit the USING and ON clauses, and to rely on the MySQL server figuring it out instead. Of course, there's NATURAL RIGHT JOIN too. Again, we recommend not using either and instead including an ON or USING clause to make the join condition explicit.
As we've seen, the LEFT JOIN clause outputs NULL values when there's no matching row in the table listed to the right of the clause. You can use this to limit your output to only those rows in the left table that don't have matching rows in the right table. For example, suppose you want to find all customers who've never placed an order. You can do this with the query:
SELECT surname, firstname, orders.cust_id FROM customer LEFT JOIN orders USING (cust_id) WHERE orders.cust_id IS NULL;
The query performs a left join, and then only outputs those rows where the cust_id in the orders table has been set to NULL in the join process. In part, the output is:
+------------+-----------+---------+ | surname | firstname | cust_id | +------------+-----------+---------+ | Sorrenti | Caitlyn | NULL | | Mockridge | Megan | NULL | | Krennan | Samantha | NULL | | Dimitria | Melissa | NULL | | Oaton | Mark | NULL | | Cassisi | Joshua | NULL |
15.2.1.3 Unions
The UNION clause allows you to combine the results of two or more queries. Most of the time you won't need it because a WHERE clause, GROUP BY, or HAVING clause provides the features you need to extract rows. However, there are occasions where it's not possible to write one query that'll do a task, and UNION sometimes saves you merging results manually after two queries have been executed.
To use UNION, you need to have attributes of the same type listed in the same order in the SELECT statement. Consider a simple example where we want to list the three oldest and three newest customers from the customer table:
(SELECT cust_id, surname, firstname FROM customer ORDER BY cust_id LIMIT 3) UNION (SELECT cust_id, surname, firstname FROM customer ORDER BY cust_id DESC LIMIT 3);
The query produces the following results:
+---------+-----------+-----------+ | cust_id | surname | firstname | +---------+-----------+-----------+ | 1 | Rosenthal | Joshua | | 2 | Serrong | Martin | | 3 | Leramonth | Jacob | | 650 | Woodburne | Lynette | | 649 | Krennan | Jim | | 648 | Cassisi | Betty | +---------+-----------+-----------+ 6 rows in set (0.01 sec)
You can also combine queries from different tables, with different attributes of the same type. When you do this, the output is labeled with the attribute names from the first query. As an example, suppose you want to produce a list of regions and wineries. You could do this with:
(SELECT winery_name FROM winery) UNION (SELECT region_name FROM region);
The first and last four rows from the output are wineries and regions respectively:
+---------------------------------+ | winery_name | +---------------------------------+ | Anderson and Sons Premium Wines | | Anderson and Sons Wines | | Anderson Brothers Group | | Anderson Creek Group | ... | Riverland | | Rutherglen | | Swan Valley | | Upper Hunter Valley | +---------------------------------+ 310 rows in set (0.01 sec)
15.2.2 Aliases
To save typing, add additional functionality, or just improve the labeling of columns, aliases are sometimes used for attribute and table names in querying. Attribute aliases are particularly useful in PHP as they can help you rename duplicate attribute names as discussed in Chapter 6. Table aliases add functionality when you want to join a table with itself and they're essential in some aspects of nested queries as discussed later in Section 15.2.3.
Consider an example query that uses table aliases:
SELECT * FROM inventory i, wine w WHERE i.wine_id = 183 AND i.wine_id = w.wine_id;
In this query, the FROM clause specifies aliases for the table names. The alias inventory i means than the inventory table can be referred to as i elsewhere in the query. For example, i.wine_id is the same as inventory.wine_id. This just saves typing in this example.
Aliases are very useful for complex queries that need to use the same table twice but in different ways. For example, to find any two customers with the same surname, you can use:
SELECT c1.cust_id, c2.cust_id FROM customer c1, customer c2 WHERE c1.surname = c2.surname AND c1.cust_id != c2.cust_id;
Here we used the customer table twice but gave it two aliases (c1 and c2) so we can compare two customers. The final clause, c1.cust_id != c2.cust_id, is essential because, without it, all customers are reported as answers; this would occur because all customers are rows in tables c1 and c2, and each customer row would match itself.
Attribute aliases are similar to table aliases. Consider an example:
SELECT surname AS s, firstname AS f FROM customer WHERE surname = "Krennan" ORDER BY s, f;
In part, this outputs:
+---------+----------+ | s | f | +---------+----------+ | Krennan | Andrew | | Krennan | Betty | | Krennan | Caitlyn | | Krennan | Caitlyn | | Krennan | Dimitria |
An attribute alias can be used in the ORDER BY, GROUP BY, and HAVING clauses, but not in the WHERE clause; it can't be used in a WHERE clause (or USING or ON) because an attribute may not be known when the WHERE clause is executed. The alias is also used for the column headings in the output (and, as discussed in Chapter 6, you'll find this useful when you're working with PHP's mysql_fetch_array( ) function or PEAR DB's DB::fetchRow( )).
Attribute aliases can also be used with functions. In the next example, we're finding out how many customers are resident in each city (but only for cities that have more the five customers):
SELECT count(*) AS residents, city FROM customer GROUP BY city HAVING residents>5 ORDER by residents DESC;
Here, residents is an alias that refers to the count function. In part, the query outputs:
+-----------+---------------+ | residents | city | +-----------+---------------+ | 16 | Portsea | | 14 | Alexandra | | 13 | Kidman | | 13 | Montague | | 13 | Doveton | | 13 | Mohogany |
15.2.3 Nested Queries
MySQL 4.1 supports nested queries, solving MySQL's most frequently discussed weakness. Nested queries are those that contain another query?they are both elegant and powerful but, unfortunately, can be difficult to learn to use. This section presents an overview of nested queries, but you'll find much longer discussions in the relational database texts listed in Appendix G.
15.2.3.1 Introduction
Consider an example nested query that finds the names of the wineries that are in the Margaret River region:
SELECT winery_name FROM winery WHERE region_id = (SELECT region_id FROM region WHERE region_name = "Margaret River");
The inner query (the one in brackets) returns the region_id value of the Margaret River region. The outer query (the one listed first) finds the winery_name values from the winery table where the region_id matches the result of the inner query.
You can nest to any level, as long as you get the brackets right. Here's another example that finds the name of the region that makes wine #17:
SELECT region_name FROM region WHERE region_id =
(SELECT region_id FROM winery WHERE winery_id =
(SELECT winery_id FROM wine WHERE wine_id = 17));Both of our previous examples can be easily rewritten as a single query with a WHERE clause and an AND operator. Indeed, you should always try to write join queries where possible and avoid nesting unless you need it; MySQL isn't good at optimizing nested queries and they are therefore usually slower to run. However, sometimes, you need a nested query.
Here's an example where a nested query is the only practical solution. Suppose you want to find which customers have made the largest single purchase of a wine. You can find which wine was sold for the highest total price using:
SELECT MAX(price) FROM items;
This reports the maximum price:
+------------+ | MAX(price) | +------------+ | 329.12 | +------------+ 1 row in set (0.01 sec)
You could then write a second query to find the customers who bought the wine:
SELECT customer.cust_id FROM customer INNER JOIN items USING (cust_id) WHERE price = 329.12;
However, with nesting you can put the queries together into a single step:
SELECT DISTINCT customer.cust_id FROM customer INNER JOIN items USING (cust_id) WHERE price = (SELECT MAX(price) FROM items);
It's not possible to write this query in one step without nesting. As we discussed in Chapter 8, using the output of a SELECT query as the input to an UPDATE, INSERT, or DELETE can cause concurrency problems and, therefore, nested queries allow you to avoid locking for many (but not all) queries.
Nesting can also be used in the HAVING clause. We don't discuss this in detail here.
In the examples so far, we've used the equals = operator. You can also use other comparison operators, including <, >, <=, >=, and !=. These operators are discussed in more detail later in "Functions." Also, all of our examples return single values from the inner query, and only one attribute or aggregate. If the inner query returns more than one value or attribute, MySQL reports an error; this can be solved using the IN clause we discuss next.
15.2.3.2 The IN clause
Suppose you want to find the wines that have been purchased by customers who've placed at least six orders. You can't use the techniques we've discussed in the previous section because the inner query (which finds the customers who've made more than six purchases) is likely to return more than one cust_id value. However, you can still use a nested query for the task by using the IN clause.
Let's consider how you'd find customers who've placed six or more orders. You'd use a query such as this:
SELECT customer.cust_id FROM customer INNER JOIN orders USING (cust_id) GROUP BY cust_id HAVING count(order_id) >= 6;
When you test this query on the winestore database, you'll find there are 107 customers returned as answers. However, to make things easy, let's look only for the three customers returned with cust_id values of 7, 14, and 107.
You could find all of the wines purchased by those three customers using the following query:
SELECT DISTINCT wine_id FROM items WHERE cust_id = 7 OR cust_id = 14 OR cust_id = 107;
Of course, you could extend this to find all wines for all 107 customers, but that requires a lot of typing!
Here's how you can do it with a nested query and the IN clause:
SELECT DISTINCT wine_id FROM items WHERE cust_id IN (SELECT customer.cust_id FROM customer INNER JOIN orders USING (cust_id) GROUP BY cust_id HAVING count(order_id) >= 6);
The outer query finds all wine_id values from the items table where the cust_id is in the set of values returned from the inner query. The inner query finds all customers who've made at least six orders. If you run this query on your MySQL installation, you'll find it's very slow to execute because MySQL isn't yet that good at optimizing nested queries. However, the result is exactly what you want.
You can compare several attributes in the nesting condition by listing more than one attribute before an IN clause, as long as the attributes are of the same type and order as those listed in the nested query. This isn't a common requirement, because most of the time you can do this with a WHERE clause and a join query. But to illustrate the syntax, suppose we had a table that contained a list of contacts, and we wanted to find out which of our contacts had the same name as a customer. A possible query would be:
SELECT * FROM contacts WHERE (surname, firstname) IN (SELECT surname, firstname FROM customer);
The query would return the set of people whose surnames and firstnames are the same in the contacts and customer tables. Of course, this query could be rewritten as:
SELECT * FROM contacts INNER JOIN customer USING (surname, firstname);
With MySQL, the join query runs much faster, and should be used in preference.
Nested queries can also use the NOT IN clause. This has the opposite effect to IN, and is analogous to the != operator but is applied to more than one row. Here's an example, where we want to find those customers who've not made at least five orders:
SELECT customer.cust_id, surname, firstname FROM customer
WHERE customer.cust_id NOT IN
(SELECT customer.cust_id FROM customer
INNER JOIN orders USING (cust_id)
GROUP BY cust_id HAVING count(*) >= 5);15.2.3.3 The EXISTS clause
Perhaps the least intuitive (and most complicated) of the nested querying tools is the EXISTS clause. However, it's very useful. The EXISTS clause is used to return output from the outer query if the inner query returns any results. Consider an example:
SELECT region_name FROM region WHERE EXISTS (SELECT region_id FROM winery GROUP BY region_id HAVING count(*) > 35);
MySQL first runs the inner query which, if you run it yourself, returns the following regions that contain at least 35 wineries:
+-----------+ | region_id | +-----------+ | 4 | | 5 | | 9 | +-----------+ 3 rows in set (0.00 sec)
Because the inner query returns a result, the outer query is executed, and so the overall output of the nested query is:
+---------------------+ | region_name | +---------------------+ | All | | Barossa Valley | | Coonawarra | | Goulburn Valley | | Lower Hunter Valley | | Margaret River | | Riverland | | Rutherglen | | Swan Valley | | Upper Hunter Valley | +---------------------+ 10 rows in set (0.01 sec)
This perhaps isn't what you expected: it's a list of all regions, and it has nothing to do with those regions that have at least 35 wineries!
You're probably wondering now whether EXISTS is actually useful. It is, but only when the inner query contains an outer reference. An outer reference creates a relationship between the inner query and the outer query, in the same way as IN or a comparison operator such as = does in the previous sections. Consider an example that corrects our previous one:
SELECT region_name FROM region WHERE EXISTS (SELECT * FROM winery WHERE region.region_id = winery.region_id GROUP BY region_id HAVING count(*) > 35);
The query returns the following results:
+---------------------+ | region_name | +---------------------+ | Coonawarra | | Upper Hunter Valley | | Margaret River | +---------------------+ 3 rows in set (0.00 sec)
The query is now returning the results we expected: a list of regions that contain more than 35 wineries. You'll notice that the region table's region_id attribute is referenced in the inner query but the region table isn't listed in its FROM clause. This is the outer reference, and it causes MySQL to run the inner query for every value returned from the outer query and output is only produced when the inner query returns a result. The region table's region_id is used in the inner query in the WHERE and GROUP BY clauses, and the count(*) in the HAVING clause therefore refers to the number of wineries in a region.
Figure 15-1 shows how MySQL evaluates the previous query using the EXISTS clause. For each region_name that's in the region table, MySQL runs an inner query. If the inner query produces results, the region_name from the outer query is added to the results; if it doesn't produce results, the outer result isn't shown. As the figure illustrates, MySQL evaluates an inner query for every outer result, and this can be slow.
Figure 15-1. Evaluating a nested query that uses EXISTS
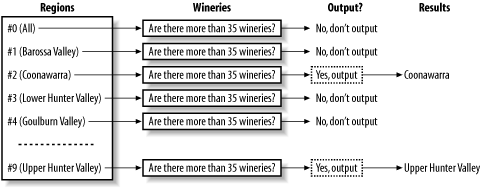
Whether you use the IN clause or the EXISTS clause is almost always a personal preference. You'll recall this query from the previous section:
SELECT DISTINCT wine_id FROM items WHERE cust_id IN (SELECT customer.cust_id FROM customer INNER JOIN orders USING (cust_id) GROUP BY cust_id HAVING count(order_id) >= 6);
This query revolves around the use of cust_id in both the inner and outer queries. The inner query joins tables using cust_id and groups results by cust_id. Therefore, the outer query finds the cust_id associated with six or more orders.
It can be rewritten using the EXISTS clause as follows:
SELECT DISTINCT wine_id FROM items WHERE EXISTS (SELECT * FROM orders WHERE orders.cust_id = items.cust_id GROUP BY cust_id HAVING count(order_id) >= 6);
This query revolves around orders in the inner query and items in the outer query. We group all orders by cust_id to find the count of six or greater. The items are irrelevant to this inner SELECT, but we refer to the items attribute so that we can search for items in the outer query (items is the outer reference).
Interestingly, while the EXISTS version is much slower than a typical join, the IN version is more than fives times slower again in our test environment. This again illustrates how poor MySQL is at optimizing nested queries, and this is hopefully something that will change soon. However, when you can, you should always write a join query in preference to a nested query.
One final note: there's also a NOT EXISTS clause that has the opposite function to EXISTS. Using NOT EXISTS, the outer query is executed if the inner query doesn't return any results.
15.2.3.4 Nested queries in the FROM clause
Nested queries can also be used in the FROM clause of a query to create an artificial table. Consider a (contrived) example where you want to find the alphabetically last customer. The following query outputs consolidated customer names:
SELECT concat(surname, " ", firstname) AS name FROM customer;
The concat( ) function joins together strings, and is discussed later in Section 15.4. The first few lines of output from the query are:
+----------------------+ | name | +----------------------+ | Rosenthal Joshua | | Serrong Martin | | Leramonth Jacob | | Keisling Perry |
Adding the nesting to the query allows you to find the maximum (alphabetically last) customer:
SELECT max(cust.name) FROM (SELECT concat(surname, " ", firstname) AS name FROM customer) AS cust;
This outputs:
+-------------------+ | max(cust.name) | +-------------------+ | Woodestock Sandra | +-------------------+ 1 row in set (0.01 sec)
You'll notice that we've aliased concat(surname, " ", firstname) as name so that it's easily referenced in the outer query. Also, you'll notice we've aliased the inner query using a table alias as cust. It's mandatory to alias the results returned from the inner query using a table alias, otherwise MySQL doesn't know how to reference the results in the outer query.
Of course, more simply, the previous query could have been accomplished using an unnested query and MySQL's proprietary LIMIT clause:
SELECT surname, firstname FROM customer ORDER BY surname DESC, firstname DESC LIMIT 1;
15.2.4 User Variables
User variables are used to store intermediate results and use them in later statements. We explain how to use them and discuss their advantages and limitations in this section.
Consider an example. In Chapter 8, we showed you the following sequence of statements as an example of when to use locking:
mysql> LOCK TABLES items READ, temp_report WRITE;
mysql> SELECT sum(price) FROM items WHERE cust_id=1;
+------------+
| sum(price) |
+------------+
| 438.65 |
+------------+
1 row in set (0.04 sec)
mysql> UPDATE temp_report SET purchases=438.65
WHERE cust_id=1;
mysql> UNLOCK TABLES;The example is a little clumsy. It requires that you write down or copy the value 438.65, and then use type it in or paste it into the UPDATE statement. In contrast, if you were executing the statements using PHP, you would retrieve the row produced by the SELECT statement using mysql_fetch_array( ), save the value in a PHP variable, and then execute the UPDATE statement and include the value of the PHP variable in its WHERE clause.
A better approach than recording the value or using PHP variables is to save the value in a MySQL user variable. MySQL user variables allow you to save results for a connection without using PHP and, therefore, without transferring results to the web server. Here's the previous example rewritten to use this approach:
mysql> LOCK TABLES items READ, temp_report WRITE;
mysql> SELECT @total:=sum(price) FROM items WHERE cust_id=1;
+--------------------+
| @total:=sum(price) |
+--------------------+
| 438.65 |
+--------------------+
1 row in set (0.14 sec)
mysql> UPDATE temp_report SET purchases=@total
WHERE cust_id=1;
mysql> UNLOCK TABLES;User variables are prefixed with an @ character and the assignment operator is :=. In this example, the result of the SELECT statement is saved in the MySQL variable @total. In the UPDATE statement, the value of the variable @total is assigned to the attribute purchases. The benefit is that you don't have to remember (or cut and paste) the result of the SELECT statement.
Consider another example. Suppose you want to find which customers bought the most expensive wine (or wines). First, you run a query that finds the price of the most expensive wine and save the result in a MySQL variable @max_cost:
mysql> SELECT @max_cost:=max(cost) FROM inventory; +----------------------+ | @max_cost:=max(cost) | +----------------------+ | 29.92 | +----------------------+ 1 row in set (0.01 sec)
Now that the maximum cost is saved, you can use it in the WHERE clause of a query to find the names of the customers who've bought the most expensive wine. To do this, you join together the customer, items, and inventory tables in the following query:
mysql> SELECT customer.cust_id, surname, firstname FROM
-> customer INNER JOIN items USING (cust_id)
-> INNER JOIN inventory USING (wine_id)
-> WHERE cost = @max_cost;
+---------+------------+-----------+
| cust_id | surname | firstname |
+---------+------------+-----------+
| 32 | Archibald | Joshua |
| 33 | Galti | Lynette |
| 44 | Mellili | Michelle |
| 54 | Woodestock | George |
| 71 | Mellaseca | Lynette |
| 144 | Nancarral | Joshua |
| 156 | Cassisi | Joshua |
| 236 | Mockridge | Megan |
| 274 | Eggelston | Melissa |
| 320 | Mellaseca | Craig |
| 334 | Serrong | Caitlyn |
| 408 | Patton | Joshua |
| 510 | Sorrenti | Joel |
| 531 | Nancarral | Michelle |
| 551 | Skerry | Joel |
| 622 | Serrong | Peter |
+---------+------------+-----------+
16 rows in set (0.08 sec)The WHERE clause uses the MySQL user variable saved from the previous SELECT query.
There are three issues you need to remember with MySQL user variables:
They only work for a connection. You can't see or use them from other connections, and they're lost when the connection closes.
They can only contain alphanumeric characters, the underscore character, the dollar sign, or a period.
They usually only work when you assign the variable in one statement and use its value in another. To avoid unexpected behavior, do not assign and use the variable in the same statement.
In general, we recommend using MySQL variables where possible in preference to saving intermediate values in your PHP scripts.
15.2.5 ROLLUP with GROUP BY
MySQL 4.1.1 and later versions support the WITH ROLLUP modifier that provides subtotaling of grouped columns in output. To show you how it works, first consider a simple example without WITH ROLLUP, where we want to find the sales of wines made in each year:
SELECT year, sum(price) FROM wine INNER JOIN items USING (wine_id) GROUP BY year;
In part, this reports:
+------+------------+ | year | sum(price) | +------+------------+ | 1970 | 20562.89 | | 1971 | 16273.73 | ... | 1997 | 18009.39 | | 1998 | 20739.53 | | 1999 | 18890.10 | +------+------------+ 30 rows in set (0.13 sec)
Now, consider what happens if you add WITH ROLLUP to the query:
SELECT year, sum(price) FROM wine INNER JOIN items USING (wine_id) GROUP BY year WITH ROLLUP;
You get one extra row in the results:
| 1997 | 18009.39 | | 1998 | 20739.53 | | 1999 | 18890.10 | | NULL |..577975.66 | +------+------------+ 31 rows in set (0.13 sec)
The extra row has a NULL value for the year, and the sum(price) column is the sum of all sales in all years. It's a shortcut that saves you running the following extra query:
SELECT sum(price) FROM items INNER JOIN wine USING (wine_id);
Now, consider a more sophisticated example that finds the total sales of each wine. In the example, we've included the region and winery tables so that we can use WITH ROLLUP to get a subtotal of wines sold by each winery and region. The key to obtaining the subtotal is to use unique values from the region and winery tables (in addition to the wine_id) in the GROUP BY clause. Here's the query:
SELECT region_name, winery_name, wine.wine_id, sum(price) FROM region INNER JOIN winery USING (region_id) INNER JOIN wine USING (winery_id) INNER JOIN items USING (wine_id) GROUP BY region_name, winery_name, wine.wine_id WITH ROLLUP;
The output reports, in part, the following:
+----------------+---------------------+---------+------------+ | region_name | winery_name | wine_id | sum(price) | +----------------+---------------------+---------+------------+ | Barossa Valley | Anderson Daze Wines | 214 | 978.25 | | Barossa Valley | Anderson Daze Wines | 215 | 31.62 | | Barossa Valley | Anderson Daze Wines | 216 | 576.25 | | Barossa Valley | Anderson Daze Wines | 217 | 225.39 | | Barossa Valley | Anderson Daze Wines | 218 | 190.26 | | Barossa Valley | Anderson Daze Wines | NULL | 2001.77 | ... | Barossa Valley | NULL | NULL | 68403.90 | ... | NULL | NULL | NULL | 577975.66 | +----------------+---------------------+---------+------------+
The sixth row shows that the total sales of the Anderson Daze Wines winery (which equals the sum of rows one to five) is $2001.77. Similarly, a total for each winery is listed immediately after that winery. After all wines for all wineries in the Barossa Valley are listed, the total for the Barossa Valley region of $68403.90 is shown using NULL values for winery_name and wine_id. Again, a region subtotal is shown immediately after each region. The last row in the table has NULL values for all attributes, and is the total sales of $577,975.66 for all regions, wineries, and wines.
The WITH ROLLUP modifier has a few peculiarities. First, the ORDER BY clause cannot be used with WITH ROLLUP. Second, the LIMIT clause is applied after the output is produced, and so it includes the subtotal rows that have NULL values. Other limitations are discussed in the MySQL manual.
15.2.6 Other MySQL Topics
We've gone as far as we're going with querying, and further than you'll need for most web database applications that you'll develop. There are topics that we've left out, including optimizing queries, using procedures, and full-text searching. Some of these topics are discussed in books dedicated solely to MySQL that are listed in Appendix E.
You'll find more about optimizing queries by diagnosis with the EXPLAIN statement in Section 5.2.1 of the MySQL manual, and we briefly discuss it in the section Tuning MySQL. Section 5 of the MySQL also includes an explanation of how MySQL optimizes most join queries, but it doesn't yet discuss nested queries. Forcing MySQL to use or ignore an index is discussed in Section 6.4.1 of the MySQL manual. Other general ideas about improving the performance of MySQL are also discussed in Section 15.9.
MySQL procedures are C++ code that can be called within a SELECT statement to post-process data. Writing procedures is discussed in Section 12 of the MySQL manual. If you're familiar with other database servers, you might also be familiar with stored procedures, which aren't the same thing. Stored procedures are SQL statements that are precompiled and stored in the server so that the client application can call the procedure instead of re-running the query, with the result that performance is substantially improved. Stored procedure support is planned for MySQL 5. Triggers are another common database server component; they are similar to stored procedures but triggers are invoked by the server when a condition is met. Triggers support is also planned for MySQL 5.
Views aren't supported in MySQL, but support is planned in MySQL 5.1. Views consolidate read-only access to several tables based on a join condition. For example, a view might allow a user to browse the sales made up to April without the need to create a temporary table. Other limitations that we don't discuss here include the lack of support for foreign keys in some table types and the lack of cursor support. Both are planned for MySQL 5.







