12.1 The Persistence of Memory
Modern operating systems cache files. You may hear it referred to as RAM cache or disk cache, but we'll just call it cache. Once a file is read from the filesystem (e.g., hard disk), the file is kept in memory even after it is no longer used, assuming there's enough free RAM to do so. Why cache files? It's frequently the case that the same file is requested repeatedly. Retrieving from memory is much faster than from a disk, so keeping it in memory can save a lot of time. Caching can be very important in sequential BLAST searches if the database is located on a slow disk or across a network. While the first search may be limited by the speed that the database can be read, subsequent searches can be much faster.
The advantage of caching is most appreciable for insensitive BLAST searches, such as BLASTN with a large word size. In more sensitive searches, retrieving sequences from the database becomes a smaller fraction of the total elapsed time. In Table 12-1, note how the speed increase from caching is a function of sensitivity (here, word size).
|
Program |
Word size |
Search 1 |
Search 2 |
Speed increase |
|---|---|---|---|---|
|
BLASTN |
W=12 |
12 sec |
7 sec |
1.71 x |
|
BLASTN |
W=10 |
33 sec |
28 sec |
1.18 x |
|
BLASTN |
W=8 |
57 sec |
52 sec |
1.10 x |
|
BLASTN |
W=6 |
243 sec |
238 sec |
1.02 x |
BLAST itself doesn't take much memory, but having a lot of memory assists caching. Look at the amount of RAM in your current systems and the size of your BLAST databases. As a rule, your RAM should be at least 20 percent greater than the size of your largest database. If it isn't and you do a lot of insensitive searches, a simple memory upgrade may boost your throughput by 50 percent or more. However, if most of your searches are sensitive searches or involve small databases, adding RAM to all your machines may be less cost-effective than purchasing a few more servers.
12.1.1 BLAST Pipelines and Caching
If you're running BLAST as part of a sequence analysis pipeline involving several BLAST searches and multiple databases, you may want to consider how caching will affect the execution of the pipeline. For example, look at the typical BLAST-based sequence analysis pipeline for ESTs depicted in Figure 12-1. The most obvious approach is to take each EST and pass it through each step. But is this the most efficient way?
Figure 12-1. EST annotation pipeline
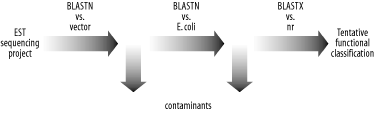
It's common to design sequence analysis pipelines with the following structure:
for each sequence to analyze {
for each BLAST search in the pipeline {
execute BLAST search
}
}
However, you can switch the inner and outer loops to achieve this structure:
for each BLAST search in the pipeline {
for each sequence to analyze {
execute BLAST search
}
}
The problem with the first pipeline is that if the BLAST databases are large, they may not all be cached. Each BLAST database can bump out the previously cached file if you don't have enough RAM, and then you get no benefit from caching. The second structure keeps the same BLAST database in memory for all the sequences. Before you tear apart your current pipeline, however, remember that caching isn't going to help much with sensitive searches. If most of your searches are sensitive, it is a waste of effort to optimize the already fast parts of your pipeline. As in any tuning procedure, optimize the major bottlenecks first.








