Modeling Star Schemas
In dimensional modeling, there are generally only two kinds of tables:
Dimensions? Relatively small, denormalized lookup tables containing business descriptive columns that end-users reference to define their restriction criteria for ad-hoc business intelligence queries.
Facts? Extremely large tables whose primary keys are formed from the concatenation of all the columns that are foreign keys referencing related dimension tables. Facts also possess numerically additive, non-key columns utilized to satisfy calculations required by end-user ad-hoc business intelligence queries.
A simple example of a dimensional data model is shown in Figure 4-1.
Figure 4-1. Example Dimensional Entity Relationship Model
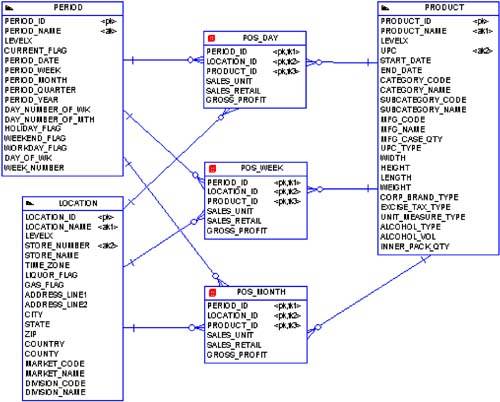
Figure 4-1 represents the basic retail store concept for POS information. POS data is gathered directly and automatically at each store's cash registers, which are in fact really just special-purpose computers. At some regular interval, that data is then fed into the corporate information systems?and ultimately the data warehouse.
Figure 4-1 has three dimension tables: PERIOD, LOCATION, and PRODUCT. PERIOD is the time dimension, which almost all star schema designs possess. Keep in mind that most OLTP systems do not have a table for time, but instead have date and timestamp columns where appropriate. But almost all ad-hoc user queries against a star schema will relate or be restricted by some time information. LOCATION is simply the various retail store locations, and PRODUCT represents the items sold by those stores. Remember, the primary mission of dimensions is to provide end-users lots of fields on which to place query restrictions.
Figure 4-1 also has three fact tables: POS_DAY, POS_WEEK, and POS_MONTH. POS_DAY simply represents the sales data for a given store on a given day. POS_WEEK and POS_MONTH are aggregates, or summarizations, of their underlying fact tables. So, POS_WEEK is the daily sales rolled up by week, and POS_MONTH is sales rolled up by month. Obviously, a user query possessing the right granularity such that it can utilize the POS_MONTH table will run faster than the same query against the POS_DAY table. Not convinced of that? Well, POS_MONTH is about 30 times smaller than POS_DAY. Of course, smaller in data warehousing terms?POS_MONTH is still nearly a billion rows.
Look again at the fact tables. These tables can be huge, with row counts easily on the order of 109 to 1012, or larger. That's hundreds of millions to hundreds of billions of rows! Of course, with any object of that size, the DBA is going to most likely use partitioning. Yet notice how we did not try to relate the actual physical implementation in the data model. This is critical as the DBA has an ever-increasing number of implementation options for both facts and their aggregates with the newer versions of Oracle.
One question that very often arises at my data warehousing presentations is: Which data modeling tool is best for data warehousing? The answer is simple: your brain. While all the various data modeling tools have their pros and cons, none of them is so intrinsically better than the rest for data warehousing as to rate a recommendation. For example, none of the current data modeling tools cleanly diagrams or records any meta-data regarding how facts and aggregates might use partitioning and/or materialized views. Don't get me wrong; I'm a huge advocate of data modeling. But for data warehousing, I find that the physical data model is useful merely as a roadmap for the ETL programmers. The real physical object implementation is far too complex for modeling tools to handle.
Another question I often get is: ow do I transform my OLTP database design into a dimensional model? The short, cop-out answer is to let the business analysts familiar with the data and business intelligence tool model your star schemas. That leaves you, as the DBA, to concentrate on the more physical implementation issues. That's exactly what I did at 7-Eleven and it worked like a charm. But for those DBAs who must also perform dimensional modeling, here are some basic steps for transforming an OLTP model into a star schema design:
Denormalize lookup relationships.
Denormalize parent/child relationships.
Create and populate a time dimension.
Create hierarchies of data within dimensions.
Consider using surrogate or meaningless keys.







