Mechanics of WEP
So far we have discussed the original goals of WEP and given an overview of the design and use of keys. Now we will look in much more detail at the way in which WEP is implemented. You need to understand where the weaknesses of WEP arise.
Fragmentation
We are used to using the telephone. There was a time when all telephones looked the same. This was partly due to the monopoly of the telephone companies but probably was also due to the need for people who had not grown up with telephones to feel comfortable with the user interface they had learned. Today, telephones are part of our psyche. We can handle phones in any shape or size as naturally as catching a ball or walking on unfamiliar ground. We pick up the phone, dial the number, and talk to the other person with little effort. We don't care about the many complicated processes that occur between our lips and the ear of the receiver (that sounds a bit weird. but we're talking about electronic processes). A similar situation has evolved for application programs. There was a time when a programmer needed to know about the details of the network protocols and hardware that were used for communication. Today, the operating systems environment allows application programs to make a connection and communicate data with ease and without knowledge of the network implementation.
If a network includes a Wi-Fi LAN link, data from the operating system or a driver needs to pass to the IEEE 802.11 MAC service layer. In other words, a packet of data arrives at the Wi-Fi LAN with instructions to send it out. This packet of data is called an MSDU (MAC service data unit). If things go well, this MSDU will eventually pop out of the MAC service layer on the destination device and be passed to the operating system or driver for delivery to the target application. Before it reaches the radio for transmission, however, the MSDU may be broken up into several smaller pieces, a process called fragmentation. Each fragment is processed for WEP encryption. A MAC header is added to the front and a checkword added to the end.
You can see that the original MSDU may now be spread across several smaller messages and have had more bytes added on?quite apart from the fact that it will now be encrypted. Each one of the smaller messages is called an MPDU (MAC protocol data unit). We'll look at the last few stages, during which an MPDU encounters the encryption process.
The process treats the data as a block of unformatted bytes; the size depends on the original MSDU contents and the fragmentation settings. It is typically in the range of 10?1,500 bytes. The first step in encryption is to add some bytes called the integrity check value (ICV).
Integrity Check Value (ICV)
The idea behind the ICV is to prevent anyone from tampering with the message in transit. In both encrypted and unencrypted messages, a check is made to detect whether any bits have been corrupted during transmission. All the bytes in the message are combined in a result called the CRC (cyclic redundancy check). This 4-byte value is added on to the end of the frame immediately prior to processing for transmission. Even if a single bit in the message is corrupted, the receiving device will notice that the CRC value does not match and reject the message. While this detects accidental errors, it provides no protection from intentional errors because an attacker can simply recompute the CRC value after altering the message and ensure that it matches again.
ICV is similar to the CRC except that it is computed and added on before encryption. The conventional CRC is still added after encryption. The theory is that, because the ICV is encrypted, no attacker can recompute it when attempting to modify the message. Therefore, the message is rendered tamper-proof. Er… well, only in theory, as we'll see shortly that clever people found a loophole. For now, let's suppose it works as intended.
So the ICV is computed by combining all the data bytes to create a four-byte checkword. This is then added on the end, as shown in Figure 6.7.
Figure 6.7. Adding the ICV

Preparing the Frame for Transmission
After the ICV is appended, the frame is ready for encryption. First, the system must select an IV value and append it to the secret WEP key (as indicated by the active key selection). Next, it initializes the RC4 encryption engine. Finally it passes each byte from the combined data and ICV block into the encryption engine. For each byte going in, an encrypted byte comes out until all the bytes are processed. This is a stream cipher.
For the receiver to know how to decrypt the message, the key number and IV value must be put on the front of the message. Four bytes are added for this purpose. The first three bytes contain the 24-bit IV value and the last byte contains the KeyID number 0, 1, 2, or 3, as shown in Figure 6.8.
Figure 6.8. Adding the IV and KeyID bits
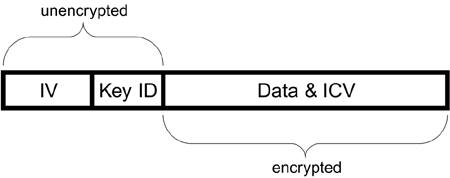
Finally, the MAC header is attached and the CRC value placed at the end to detect transmission errors. A bit in the MAC header indicates to the receiver that the frame is WEP encrypted so that it knows how to handle it.
The receive process follows logically. The receiver notes that the WEP bit is set and therefore reads and stores the IV value. It then reads the key ID bits so it can select the correct WEP key, append the IV value, and initialize the RC4 encryption engine. Notice that with RC4 there is no difference between the encryption and decryption processes. If you run the data through the encryption process twice, you get back to the original data?in other words, the second encryption cancels out the first. Therefore, you need only one engine for both encryption and decryption. After the encryption engine is initialized, the data is run through one byte at a time to reveal the original message. The final step is to compute the ICV and verify that the value matches that in the received message. If all is well, the data portion is passed up for further processing.
RC4 Encryption Algorithm
RC4 is the name of the encryption algorithm used by WEP. An encryption algorithm is just a set of operations that you apply to plaintext to generate ciphertext. Obviously it is not helpful unless there is a corresponding decryption algorithm. In the case of RC4, the same algorithm is used for encryption and decryption. The value of an encryption algorithm lies partly in how strong it is and partly in how easy it is to implement. The strength of an algorithm is measured by how hard it is to crack the ciphertext. There certainly are stronger methods than RC4. However, RC4 is remarkably simple to implement and considered to be very strong if used in the right way. This last point is important because we will see all the weakness of WEP later, and those weaknesses do not derive from faults in RC4, but in the way it is applied in the case of WEP.
RC4[2] is a proprietary stream cipher designed in 1987. While the algorithm has received a great deal of public attention, RSA Labs, Inc. regards the description of the algorithm as a trade secret. Implementers should consult RSA Labs about this issue. However, the algorithm was reverse-engineered and made public anonymously in 1994.
[2] RC4 stands for the fourth cipher designed by Ron Rivest (Rivest Cipher 4).
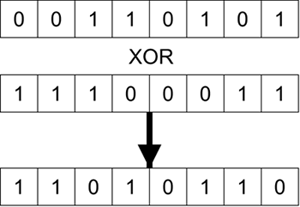
Fortunately, because RC4 is simple to implement, it is also simple to describe. The basic idea behind RC4 encryption is to generate a pseudorandom sequence of bytes called the key stream that is then combined with the data using an exclusive OR (XOR) operation. For those not familiar with the XOR operation, it combines two bytes and generates a single byte. It does this by taking and comparing corresponding bits in each byte. If they are equal, the result is 0; if they differ, the result is 1. An example is shown in Figure 6.9.
Figure 6.9. XOR Operation
XOR is often written mathematically using the symbol " " so the example shown in the figure would be written:
" so the example shown in the figure would be written:
00110101
One important characteristic of XOR is that if you apply the same value twice, the original value is returned:
00110101
In other words, if A B = C, then C B = A. You might guess that in the case of RC4, this property is exploited as follows:
Encryption: Plaintext
It is necessary that "random" looks random to an attacker but that both ends of the link can generate the same "random" value for each byte processed. It is therefore called pseudorandom and is generated by the RC4 algorithm.
The most important property of a pseudorandom key stream is that you can calculate the next byte in the sequence only if you know the key used to generate the stream. If you don't know the key, it really looks random. Note that the XOR operation completely hides the plaintext values. Even if the plaintext is just a long series of 0 values, the ciphertext still looks random to an attacker.
XOR is a trivially easy operation for a computer to implement so the only challenge is to generate a good pseudorandom number stream. You need one pseudorandom byte for each byte of the message to be encrypted. RC4 generates such a stream.
There are two phases in RC4: key setup and pseudo-random generation. The first phase, the key setup algorithm, establishes a 256-byte array with a permutation of the numbers 0?255; that is, all the numbers are present in the array but the order is mixed up. The permutation in the array, or S-box, is established by first initializing the array with the numbers 0?255 in order. The elements in the S-box are then rearranged through the following process. First, a second 256-byte array, or K-box, is filled with the key, repeating as needed to fill the array. Now each byte in the S-box is swapped with another byte in the S-box. Starting at the first byte, the following computation is made:
j = (Value in first byte of S-box ) + (Value in first byte of K-box) j is a single byte value and any overflow in the addition is ignored.
Now j is used as an index into the S-box and the value at that location is swapped with the value in the first location.
This procedure is repeated another 255 times until each byte in the S-box has been swapped. The process is described by the following pseudocode for people familiar with programming:
i = j = 0; For i = 0 to 255 do j = (j + Si + Ki) mod 256; Swap Si and Sj; End;
Once the S-box has been initialized, the next phase in RC4 is the pseudorandom generation phase. This phase involves more swapping of bytes in the S-box and generates one pseudorandom byte per iteration (R). The equations for the iterations are shown here.
i = (i + 1) mod 256 j = (j + Si) mod 256 Swap Si and Sj k = (Si + Sj) mod 256 R = Sk
To generate the ciphertext, each byte of plaintext is XORed with a value of R as produced by the RC4 algorithm. Notice how the whole process has been done using byte length additions and swaps?very easy operations for computer logic.
Theoretically, RC4 is not a completely secure encryption system because it generates a pseudorandom key stream, not truly random bytes. But it's certainly sufficiently secure for our application, if applied correctly to the protocol.
|
Using XOR in this way is similar to a Vernam cipher (Vernam, 1926). Gilvert Vernam developed this cipher during World War I while working for AT&T. However, it is only completely secure if R is a true random byte (Menenez et al., 1996). What constitutes a true random byte is a philosophical debate we won't open here. But suppose that you generated a huge table of random numbers by sampling cosmic noise or some genuinely random physical event rather than using a pseudorandom algorithm such as in RC4. You could use your random numbers by sending a secret copy to your friend for use with the Vernam cipher. This has the advantage that the numbers are truly random and known to both ends of the link. This approach is very secure, but you would be allowed to use the table only once. Then you would have to eat it or otherwise dispose of it?it is a one-time pad. Ensuring that a one-time pad system is completely secure requires never reusing the same series of random bytes twice. Because the former Soviet Union made this serious mistake following World War II, the American National Security Agency (NSA) was able to decrypt a number of enciphered messages sent by Soviet agents in a project code named VENONA (U.S. NSA, 1999). |







