Clustering and Distributed Architectures
The basic idea behind redundant systems and services is to provide at least a second resource that can either take over the duty in a hot-standby fashion or, even better, is a member of a server/service farm that constantly contributes via load-balancing schemes. One step further would distribute such architecture geographically, and that would pretty much define the boundaries (not limits) of such an architecture.
One big advantage of a loosely coupled load-sharing cluster approach is that it is independent of the failure of one component. This approach affects overall cluster performance only to a certain extent, depending on the capacity planning of the cluster architect. One major reason for such deployments is the possibility to schedule maintenance for a cluster constituent without affecting normal operation in high-availability networks.
Historically, clustering is a domain of the (Open)VMS world. OpenVMS is a product of HP after HP bought Compaq and Compaq bought Digital. If you are interested in OpenVMS, look at http://www.openvms.org and Hewlett Packard's web page.
The apex of clustering is a tight integration (virtual supercomputer) of an almost arbitrary number of multiprocessor systems to form a modern cluster under the control of redundant cluster controllers with distributed storage, memory, sockets, and I/O. Examples of such an approach are high-performance clusters (HPC). In contrast, GRID architectures (computing grids) for scientific number crunching such as the well-known SET@Home project (http://setiathome.ssl.berkeley.edu) have evolved, where every home or office workstation contributes to a calculation when idle. A thorough discussion of cluster concepts, such as MOSIX and Beowulf, goes beyond the scope of this book. Nevertheless, the following sections cover three prominent examples of Linux HA approaches.
Linux Virtual Server Project (LVSP)
The LVSP is a scalable and transparent load-balancing architecture based on the Linux operating system. It requires a kernel patch and a user-space administration tool, ipvsadm. The constituent servers of a load-balancing group can be dispersed geographically and still can be Layer 4 controlled by the LVS architecture.
Detection of node or daemon failures and the appropriate reconfiguring of the system lead to high availability. IP-level load balancing offers performance and transparency advantages over application-level solutions such as caches and proxies. The virtual server uses three different load-balancing techniques and a repertoire of scheduling algorithms. The load-balancing techniques are as follows:
Virtual server via NAT? Based on Port Address Translation and port forwarding.
Virtual server via IP tunneling? The virtual server sends requests to physical servers via IP-IP tunnels.
Virtual server via direct routing? The return packets to client requests are routed directly from the real servers without involving the load balancer.
The scheduling algorithms are as follows
Least connection
Weighted least-connection
Round-robin (allocates connections evenly to all real servers)
Weighted round-robin
Locality-based least connection
Locality-based least connection with replication
Destination hashing
Source hashing
For further configuration details and ancillary tools, consult http://www.linuxvirtualserver.org/.
Connection Integrity Issues
Modern director approaches such as LVS support connection-integrity maintenance. Connection integrity refers to the capability of the director to maintain a connection in a way that it never changes the real server after the first scheduling decision has been made based on the initial packets. This is necessary for certain protocols such as Secure Sockets Layer (SSL) and File Transfer Protocol (FTP). This is sometimes referred to as stateful load balancing. Optionally, the connection behavior of a service can be marked persistent. Persistency can be accomplished via manual configuration, whereas connection-integrity tracking works on a per-connection basis with finer granularity.
LVS?Virtual Services
You can configure Linux Director virtual service definition in these ways:
IP address? The virtual IP address of a global service.
TCP/UDP port? The port of a service.
Protocol? For example, HTTPS of FTP.
Linux netfilter/iptables firewall marks? A firewall mark can be matched to virtual services. This adds another level of flexibility and granularity (for example, for persistency setups).
Linux Ultra Monkey
Ultra Monkey is a project to create load-balanced and highly available services on a LAN using open-source components on the Linux operating system. Figure 12-3 describes the entire architecture.
Figure 12-3. Linux Ultra Monkey (LVS) Architecture
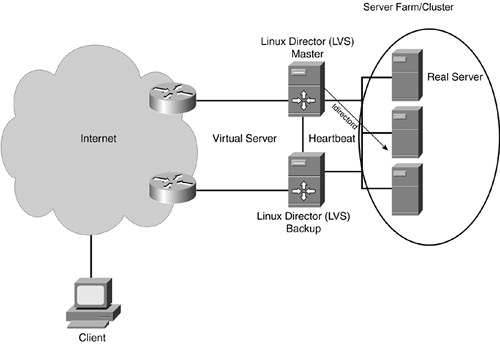
Ultra Monkey includes the following key features/components:
Layer 4 switching using the Linux Virtual Server (LVS)
High availability provided by Heartbeat protocol
Service-level monitoring using ldirectord
Supports highly available or load-balanced topologies
Integrates with Super Sparrow
Supports monitoring of HTTP, HTTPS, FTP, IMAP, POP, SMTP, LDAP, and NNTP
IP Address Takeover with Heartbeat
The takeover approach chosen largely depends on topology and effective switchover timer requirements. As a rule of thumb, MAC address takeover works fastest, IP address takeover is a little bit slower, and dynamic DNS reconfiguration takes its time. Heartbeat is an integral part of the Ultra Monkey architecture, based on ARP spoofing/gratuitous ARP for takeover with the help of an additional physical interface or an IP alias.
All Heartbeat protocols are based on the assumption that keepalive messages (hence the name heartbeat) are exchanged between systems. If a message is not received in due time, a failure is assumed and takeover or master node re-election activities are triggered. The useful thing about the heartbeat protocol is that it works over serial links, PPP links, and Ethernet and incorporates aspects of VRRP such as virtual addresses. It is much more cost-effective to use RS232 interfaces instead of committing dedicated, although almost idle, Ethernet NIC resources.







