2.2 Documents
An XML document is a special construct designed to archive data in a way that is most convenient for parsers. It has nothing to do with our traditional concept of documents, like the Magna Carta or Time magazine, although those texts could be stored as XML documents. It simply is a way of describing a piece of XML as being whole and intact for parsing.
It's important to think of the document as a logical entity rather than a physical one. In other words, don't assume that a document will be contained within a single file on a computer. Quite often, a document may be spread out across many files, and some of these may live on different systems. All that is required is that the XML parser reading the document has the ability to assemble the pieces into a coherent whole. Later, we will talk about mechanisms used in XML for linking discrete physical entities into a complete logical unit.
As Figure 2-2 shows, an XML document has two parts. First is the document prolog, a special section containing metadata. The second is an element called the document element, also called the root element for reasons you will understand when we talk about trees. The root element contains all the other elements and content in the document.
Figure 2-2. Parts of an XML document
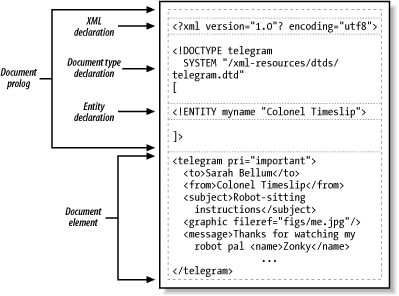
The prolog is optional. If you leave it out, the parser will fall back on its default settings. For example, it automatically selects the character encoding UTF-8 (or UTF-16, if detected) unless something else is specified. The root element is required, because a document without data is just not a document.[1]
[1] Interestingly, there is no rule that says the root element has to contain anything. This leads to the amusing fact that the following smiley of a perplexed, bearded dunce is a well-formed document: <:-/>. It's an empty element whose name is ":-".







