3.2 Narrative Documents
Now let's look at an important category of XML. A narrative document contains text meant to be read by people rather than machines. Web pages, books, journals, articles, and essays are all narrative documents. These documents have some common traits. First, order of elements is inviolate. Try reading a book backward and you'll agree it's much less interesting that way (and it gives away the ending). The text runs in a single path called a flow, which the reader follows from beginning to end.
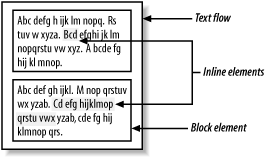
Another key feature of narrative documents is specialized element groups, including sections, blocks, and inlines. Sections are what you would imagine: elements that break up the document into parts like chapters, subsections, and so on. Blocks are rectangular regions such as titles and paragraphs. Inlines are strings inside those blocks specially marked for formatting. Figure 3-2 shows how a typical formatted document would render these elements.
Figure 3-2. Flows, blocks, inlines
3.2.1 Flows and Sections
A narrative document contains at least one flow, a stream of text to be read continuously from start to finish. If there are multiple flows, one will be dominant, branching occasionally into short tangential flows like sidebars, notes, tips, warnings, footnotes, and so on. The main flow is typically formatted as a column, while other flows are often in boxes interrupting the main flow, or moved to the side or the very end, with some kind of link (e.g., a footnote symbol).
Markup for flows are varied. Some XML applications like XHTML do not support more than one flow. Others, like DocBook, have rich support for flows, encapsulating them as elements inside the main flow. The best representations allow flows to be moved around, floated within the confines of the formatted page.
The main flow is broken up into sections, which are hierarchical divisions that organize the document by topics, usually with titles or heads. For example, a book is divided into chapters, which are subdivided into sections and subsections and subsubsections. It is often convenient to treat these divisions as separate entities which can be stored in their own files and imported using the external entity mechanism. This is useful if different people are working on sections in parallel, such as with articles of a journal.
Sections are coded in two common ways. In the first (and less flexible) scheme, the section head is tagged, but no element is used to denote the boundary of the section, like this:
<bighead>A major section</bighead> <head>A cute little section</head> <paragraph>Some text...</paragraph> <head>Another cute little section</head> <paragraph>Some text...</paragraph>
In the other (better) scheme, the section has definite boundaries created by a container element:
<section>
<head>A major section</head>
<subsection>
<head>A cute little section</head>
<paragraph>Some text...</paragraph>
</subsection>
<subsection>
<head>Another cute little section</head>
<paragraph>Some text...</paragraph>
</subsection>
</section>
The first is called a flat structure. It is less desirable because it relies on presentational details to divine where parts of the document begin and end. In this case, a bigger head means a larger section is beginning, and a small head indicates a subsection is starting. It's harder to write software to recognize the details of flat structures than of hierarchical structures. XHTML, for example, is typically flat. In contrast, the markup language DocBook is hierarchical. We'll see examples of these shortly.
3.2.2 Blocks and Inlines
A block is a type of element that contains a segment of a flow and is typically formatted as a rectangular region, separated from other blocks by space above and below. Unlike sections, blocks hold mixed content, both character data and elements. Examples of blocks are paragraphs, section heads, and list items.
Elements inside blocks are called inline elements because they follow the line of text. They begin and end within the lines scanning from left to right (or right to left, if we're reading Arabic). Inlines are used to mark words or phrases for special formatting from the surrounding text in the block. Examples include emphasis, glossary terms, and important names.
Here is an example of a block with inlines:
<para><person>R. Buckminster Fuller</person> once said, <quote>When people learned to do <emphasis>more</emphasis> with <emphasis>less</emphasis>, it was their lever to industrial success.</quote></para>
The element para is a block, containing a whole paragraph of text. Inside it are three inline element types: person, quote, and emphasis. The quote element contains elements itself (the two emphasis elements), but is still considered an inline, since it begins and ends within the text line of the block.
There are different reasons to use inlines. One is to control how the text formats. In this case, a formatter will probably replace the quote start and end tags with quotation marks. For emphasis elements, it might render the contents in italic, underline, or bold.
Another role for inlines is to mark text for special processing. The person element may have no special treatment by the formatter, but could be useful in other ways. Marking items as "person," "place," "definition," or whatever, makes it possible to mine data from the document to generate indexes, glossaries, search tables, and much more.
3.2.3 Complex Structures
Not all structures found in narrative documents can be so readily classified as blocks or inlines. A table is not really a block, but an array of blocks. An illustration has no character data so it can't be considered a block. Lists also have their own rules, with indentation, autonumbering or bullets, and nesting. Objects like these are necessary complications for the narrative model.
Handling these structures properly is a tricky subject, but you can make some assumptions. For one thing, these structures usually remain inside the flow, interrupting the surrounding text briefly. It's as if the XML is an ocean of narrative-style markup broken up with little islands of complex markup.
Structures like figures and tables may float within the flow, meaning that the formatter has some leeway in placing the objects to produce the best page layout. If a figure would cross a pagebreak in one place, the formatter may be able to reposition it elsewhere. For this reason, such objects usually have captions with references in the text that sound like "the data is summarized in Table 3-5." A simple attribute like float="yes" may be sufficient to represent this capability in the markup.
Complex objects behave a little like blocks in that they are usually separated vertically from each other and the surrounding text. They may have some of the spacing and padding properties as well. These details are usually settled in a stylesheet; XML doesn't (or shouldn't) tangle with presentational aspects any more than it has to.
3.2.4 Metadata
Metadata is information about the document that is not part of the flow. It's useful to keep with the rest of the document, but it's not formatted, or else it's formatted in a special way, such as on a title page. Examples include author name, copyright date, publisher, revision history, ISBN, and catalog number.
In XHTML, for example, a whole part of the document, the head element, is reserved to hold metadata like the title, descriptive terms for search engines, links to stylesheets, and so on. In DocBook, metadata can be associated with individual sections, which is useful to associate authors with individual articles, for example.
3.2.5 Linked Objects
The last bunch of oddball elements often found in narrative documents can be classified as linked objects. These are elements that act as bookmarks in a document. The way you might stick a paperclip on a page or bend over the corner to mark the page is how they work.
First, there is the cross reference, an element that refers to a section or object somewhere else in the document. When formatted, it may be replaced with generated text, such as the section number or title of the referred object. It may be turned into a hyperlink, which when clicked transports the user directly to the object.
Another kind of linked object is an invisible marker. It has no overt function in the flow other than to mark a location so that later, when generating an index, you can calculate a page number or create a hyperlink. Index items often span a range of pages, so you might want to capture the range with two markers, one at the beginning and one at the end.
3.2.6 XHTML
Good old HTML is the markup language we are all familiar with. Simple, pretty, easy to learn, it has turned the Internet from an obscure plaything of a few academics to a must-have utility for everyone. Its success can be attributed to the "good enough" principle of web design. It's good enough to model almost any simple document as long as you don't mind its limitations: single-column format, flat structure, and lack of page-oriented features.
The simplicity that made HTML so popular with novice publishers is frustrating to professionals. Graphic designers crave better page layout capability and stylesheet granularity. Web developers want better structure and navigation. Librarians and researchers want more detailed metadata and search capability. Users with special needs want more localization and customization. Poor HTML has been pushed to do far more than it was ever designed to do.
None of this makes HTML a bad markup language. It will not go away anytime soon, because it does its job well. It is a basic markup language for electronic display and cross-document linking. However, it is now just one star in a constellation of XML languages. If you need to do more, you can select other kinds of narrative markup languages such as DocBook, which we will discuss later in the chapter.
First, let me clear up something that might be confusing to you. I use the terms HTML and XHTML interchangeably. HTML is older than XML, so its earlier incarnations do not follow all the rules of well-formed XML documents. However, XML was designed to make it as easy as possible to get HTML documents into good XML form. HTML that is well-formed XML is simply called XHTML. From now on, when I use the term HTML, I mean XHTML.
The best feature of HTMLso great it's responsible for half of the acronymis hypertext: text that spans documents. Where the Web is concerned, the boundaries of documents are quite blurred. As a result, documents are typically small and with many nonlinear flows. It's easy to get lost, so navigation aids such as links at the top, bottom, or margin are required. But the basics, blocks and inlines, are the same as in XML.
Example 3-4 is a short XHTML document. I've taken the content of a manual page for the Unix command cat and reformatted it as HTML. In this example, pay attention to the blocks, inlines, and complex objects like lists.
Example 3-4. An XHTML document
<?xml version="1.0"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<head>
<title>CAT(1) System General Commands Manual</title>
</head>
<body>
<h1>CAT(1) System General Commands Manual</h1>
<h2>NAME</h2>
<p>cat - concatenate and print files</p>
<h2>SYNOPSIS</h2>
<p>cat [-benstuv] [-] [<em>file</em>...]</p>
<h2>DESCRIPTION</h2>
<p>
The <i>cat</i> utility reads files sequentially, writing them to the
standard output. The file operands are processed in command line
order. A single dash represents the standard input.
</p>
<p>
The options are as follows:
</p>
<dl>
<dt>-b</dt>
<dd>
Implies the <tt>-n</tt> option but doesn't number blank lines.
</dd>
<dt>-e</dt>
<dd>
Implies the <tt>-v</tt> option, and displays a dollar sign ($) at
the end of each line as well.
</dd>
<dt>-n</dt>
<dd>Numbers the output lines, starting at 1.</dd>
<dt>-s</dt>
<dd>
Squeezes multiple adjacent empty lines, causing the output to be single
spaced.
</dd>
<dt>-t</dt>
<dd>
Implies the <tt>-v</tt> option, and displays tab characters as
<tt>^I</tt> as well.
</dd>
<dt>-u</dt>
<dd>
The <tt>-u</tt> option guarantees that the output is unbuffered.
</dd>
<dt>-v</dt>
<dd>
Displays non-printing characters so they are visible. Control
characters print as <tt>^X</tt> for control-X; the delete character
(octal 0177) prints as <tt>^?</tt> Non-ascii characters (with the high
bit set) are printed as <tt>M-</tt> (for meta) followed by the
character for the low 7 bits.
</dd>
</dl>
<p>
The <i>cat</i> utility exits 0 on success, and >0 if an error occurs.
</p>
<h2>BUGS</h2>
<p>
Because of the shell language mechanism used to perform output
redirection, the command <tt>cat file1 file2 > file1</tt> will cause
the original data in file1 to be destroyed!
</p>
<h2>SEE ALSO</h2>
<ul>
<li><a href="head.html">head(1)</a></li>
<li><a href="more.html">more(1)</a></li>
<li><a href="pr.html">pr(1)</a></li>
<li><a href="tail.html">tail(1)</a></li>
<li><a href="vis.html">vis(1)</a></li>
</ul>
<p>
Rob Pike, <i>UNIX Style, or cat -v Considered Harmful</i>, USENIX Summer
Conference Proceedings, 1983.
</p>
<h3>HISTORY</h3>
<p>
A <i>cat</i> utility appeared in Version 6 AT&T UNIX.
</p>
<p>3rd Berkeley Distribution, May 2, 1995</p>
</body>
</html>
This is a flat document structure. No elements were used to contain and divide sections. HTML does have an element called div that can be used as a section container; however, it is not specifically designed as such, nor is it used often in HTML documents.[1] div is more often used to divide regions for special formatting. So I stand by my assertion that HTML is essentially a flat-structured language.
[1] XHTML 2.0 is introducing new elements section and h, which will fill this gap.
Now direct your attention to the inlines in the example, tt and i. The names are abbreviations for presentational terms, "teletype" and "italic." Right there, you know something's wrong. HTML has few element types, but is meant to be used for many different types of document. So the inventors picked elements that are generic and style-oriented. As a result we're forced to mark up terms the way we want them to look rather than by what they are.
HTML does supply an inline element called span, which can be supplemented with attributes to fit all kinds of roles. For example, I could have used <span class="command"> for the cat command and <span class="citation"> for the reference to "UNIX Style...". This would allow some flexibility in designing a stylesheet, but it's really not using the full power of XML. It's just one element being stretched into many different roles.
Even some of the blocks have been forced into generic roles. The paragraph under the head "SYNOPSIS" isn't really a paragraph, is it? It's really something different, and I would prefer to use an element strictly for synopses or code listings. But HTML provides very few types of block elements and I am obligated to use whatever is available.
Using HTML for this example has good and bad points. The good side is that HTML is easy to use, so I was able to mark up the manual page in only a few minutes. With only a few element types to remember, I don't have to look in a book to know which one to use and how it will look when formatted. The downside is that now I have a document fit for only one purpose: displaying in a web browser. A printout is likely to look primitive. And for other purposes, like searching and indexing, the lack of granularity is likely to prevent me from doing anything truly useful.
Until I need the extra functionality, I'm happy with HTML. But if I ever plan to use a document in more than one way, I'll need to explore other options. Something more specific to my brand of data will fit better and give me more options. What I will show you next is a markup language specifically designed for the kind of information shown in the last example.
3.2.7 DocBook
DocBook is a markup language designed specifically for technical documentation, modelling everything from one-page user manuals to thousand-page tomes. Like HTML, it predates XML and was first an SGML application. Also like HTML, it has migrated to XML and works very well in that framework.
Unlike HTML, DocBook is very large and comes with a steep learning curve. Its elements are very specialized. It has blocks for different kinds of code listings, scores of inlines for technical terms, and many kinds of sections. Some users of DocBook think that it may be too big. Others feel it's too loose, allowing for so many kinds of documents (within the technical documentation realm) that it suffers from the ambiguity that hinders HTML. Despite these complaints, DocBook is and always has been the best markup language for technical documentation.
It's not hard to find tools and support for DocBook. Many XML editors (XMetaL and Adept, for example) come with DocBook packages already configured. Lots of stylesheets, schema, DTDs, and other aids are also available. This support is likely to continue as various groups, from publishers to the Linux Documentation Project, adopt DocBook as their default standard.
The first incarnation (Example 3-5) is a reformulation of the previous example. You'll see that the markup is a better fit for this type of data, and the element types are much more specific. Also note the introduction of section elements.
Example 3-5. A DocBook reference page
<?xml version="1.0"?>
<!DOCTYPE refentry PUBLIC "-//OASIS//DTD DocBook XML V4.1//EN"
"/usr/local/dtds/docbook41/docbookx.dtd">
<refentry>
<refnamediv>
<refname>cat</refname>
<manvolnum>1</manvolnum>
<refmeta role="edition">
3rd Berkeley Distribution, May 2, 1995
</refmeta>
<refpurpose>concatenate and print files</refpurpose>
</refnamediv>
<refsynopsisdiv>
<synopsis>cat [-benstuv] [-]
[<replaceable>file</replaceable>...]</synopsis>
</refsynopsisdiv>
<refsect1><title>Description</title>
<para>The <command>cat</command> utility reads files sequentially, writing
them to the standard output. The file operands are processed in
command line order. A single dash represents the standard input.</para>
<para>The options are as follows:</para>
<variablelist>
<varlistentry><term><option>-b</option></term>
<listitem><para>Implies the <option>-n</option> option but doesn't number blank
lines.</para></listitem>
</varlistentry>
<varlistentry><term><option>-e</option></term>
<listitem><para>Implies the <option>-v</option> option, and displays a dollar sign
($) at the end of each line as well.</para></listitem>
</varlistentry>
<varlistentry><term><option>-n</option></term>
<listitem><para>Numbers the output lines, starting at 1.</para></listitem>
</varlistentry>
<varlistentry><term><option>-s</option></term>
<listitem><para>Squeezes multiple adjacent empty lines, causing the output to be
single spaced.</para></listitem>
</varlistentry>
<varlistentry><term><option>-t</option></term>
<listitem><para>Implies the <option>-v</option> option, and displays tab
characters as <keysym>^I</keysym> as well.</para></listitem>
</varlistentry>
<varlistentry><term><option>-u</option></term>
<listitem><para>The <option>-u</option> option guarantees that the output is
unbuffered.</para></listitem>
</varlistentry>
<varlistentry><term><option>-v</option></term>
<listitem><para>Displays non-printing characters so they are visible. Control
characters print as <keysym>^X</keysym> for control-X; the delete
character (octal 0177) prints as <keysym>^?</keysym> Non-ascii
characters (with the high bit set) are printed as
<literal>M-</literal> (for meta) followed by the character for the low
7 bits.</para></listitem>
</varlistentry>
</variablelist>
<para>The <command>cat</command> utility exits 0 on success, and >0 if an
error occurs.</para>
</refsect1>
<refsect1><title>Bugs</title>
<para>Because of the shell language mechanism used to perform output
redirection, the command <command>cat file1 file2 > file1</command>
will cause the original data in file1 to be destroyed!</para>
</refsect1>
<refsect1><title>See also</title>
<simplelist>
<member><link href="head.xml">head(1)</link></member>
<member><link href="more.xml">more(1)</link></member>
<member><link href="pr.xml">pr(1)</link></member>
<member><link href="tail.xml">tail(1)</link></member>
<member><link href="vis.xml">vis(1)</link></member>
</simplelist>
<para>Rob Pike, <citetitle>UNIX Style, or cat -v Considered
Harmful</citetitle>, USENIX Summer Conference Proceedings, 1983.</para>
</refsect1>
<refsect1><title>History</title>
<para>A <command>cat</command> utility appeared in Version 6 AT&T UNIX.</para>
</refsect1>
</refentry>
The first thing you'll notice is that DocBook is a lot more verbose than HTML. The variablelist cousin to HTML's definition list is a chore to type out. But there certainly is no doubt about what an element stands for, which is necessary in a markup language with so many elements. If every tag name was an abbreviation of two letters, there'd be no hope of ever memorizing a fraction of the langauge.
The structure of the document element, refentry is highly specialized. Whereas HTML adopts a strategy where every document has the same overall structure, DocBook is very closely bound to the type of document you're authoring. If this document were a book, for example, it would look completely different. The metadata is specific to reference pages, and even the sections are called refsect1, meaning that they are specific to a reference entry.
The types of inlines are much more numerous than in HTML, with highly specific names like option, command, and citetitle. The blocks, too, are more differentiated. Notice that we now have a synopsis element to address a complaint I made about the HTML example.
The tradeoffs of HTML are reversed here. DocBook is much more complex and intricate than HTML, making it harder to learn and use. But the more specific vocabulary of this markup language makes it much more flexible in terms of formatting and processing. With flexibility may come more work, however, since someone will have to set up a big stylesheet to handle all the elements. If you purchase a package solution, as is possible with many high-end XML editors, much of this work may be done for you.
This example only shows a small part of DocBook. I'd like to give you another taste, so that you can see the breadth of its capabilities. Example 3-6 shows a more traditional narrative document, a book. Here you will see a wide variety of section elements (chapters, sections) and complex structures (table, figure, list). After the example, I've made notes to explain some of the elements.
Example 3-6. A DocBook book
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE book SYSTEM "/xmlstuff/dtds/barebonesdb.dtd"
[
<!ENTITY companyname "Cybertronix"> <!-- SEE NOTE 1 -->
<!ENTITY productname "Sonic Screwdriver 9000">
]>
<book>
<title>&productname; User Manual</title> <!-- SEE NOTE 2 -->
<author>Indigo Riceway</author>
<preface id="preface">
<title>Preface</title>
<sect1 id="about">
<title>Availability</title>
<para>The information in this manual is available in the following forms:</para>
<orderedlist> <!-- SEE NOTE 3 -->
<listitem><para>Instant telepathic injection</para></listitem><listitem><para>
Lumino-goggle display</para></listitem><listitem><para>Ink on compressed, dead, arboreal
matter</para></listitem><listitem><para>Cuneiform etched in clay tablets</para></listitem>
</orderedlist>
<para>The &productname; is sold in galactic pamphlet boutiques or wherever
&companyname; equipment can be purchased. For more information, or
to order a copy by hyperspacial courier, please visit our universe-wide
Web page at <systemitem
role="url">http://www.cybertronix.com/sonic_screwdrivers.html</systemitem>.</para>
</sect1> <!-- SEE NOTE 4 -->
</preface>
<chapter id="intro"> <!-- SEE NOTE 5 -->
<title>Introduction</title>
<para>Congratulations on your purchase of one of the most valuable tools in
the universe! The &companyname; &productname; is
equipment no hyperspace traveler should be without. Some of the
myriad tasks you can achieve with this device are:</para>
<itemizedlist>
<listitem><para>Pick locks in seconds. Never be locked out of your tardis
again. Good for all makes and models including Yale, Dalek, and
Xngfzz.</para></listitem>
<listitem><para>Spot-weld metal, alloys, plastic, skin lesions, and virtually any
other material.</para></listitem>
<listitem><para>Rid your dwelling of vermin. Banish insects, rodents, and computer
viruses from your time machine or spaceship.</para></listitem>
<listitem><para>Slice and process foodstuffs from tomatoes to brine-worms. Unlike a
knife, there is no blade to go dull.</para></listitem>
</itemizedlist>
<para>Here is what satisfied customers are saying about their &companyname;
&productname;:</para>
<comment> <!-- SEE NOTE 6 -->
Should we name the people who spoke these quotes? --Ed.
</comment>
<blockquote>
<para>"It helped me escape from the prison planet Garboplactor VI. I
wouldn't be alive today if it weren't for my Cybertronix 9000."</para>
</blockquote>
<blockquote>
<para>"As a bartender, I have to mix martinis <emphasis>just
</emphasis>
<emphasis>right</emphasis>. Some of my customers get pretty cranky if I slip
up. Luckily, my new sonic screwdriver from Cybertronix is so accurate,
it gets the mixture right every time. No more looking down the barrel
of a kill-o-zap gun for this bartender!"</para>
</blockquote>
</chapter>
<chapter id="controls">
<title>Mastering the Controls</title>
<sect1>
<title>Overview</title>
<para><xref linkend="controls-diagram"/> is a diagram of the parts of your
&productname;.</para>
<figure id="controls-diagram"> <!-- SEE NOTE 7 -->
<title>Exploded Parts Diagram</title>
<graphic fileref="parts.png"/>
</figure>
<para><xref linkend="controls-table"/> <!-- SEE NOTE 8 -->
lists the function of the parts labeled in the diagram.</para>
<table id="controls-table"> <!-- SEE NOTE 9 -->
<title>Control Descriptions</title>
<tgroup cols="2">
<thead>
<row>
<entry>Control</entry>
<entry>Purpose</entry>
</row>
</thead>
<tbody>
<row>
<entry>Decoy Power Switch</entry>
<entry><para>Looks just like an on-off toggle button, but only turns on a
small flashlight when pressed. Very handy when your &productname; is misplaced
and discovered by primitive aliens who might otherwise accidentally
injure themselves.</para></entry>
</row>
<row>
<entry><emphasis>Real</emphasis> Power Switch</entry>
<entry><para>An invisible fingerprint-scanning capacitance-sensitive on/off
switch.</para></entry>
</row>
⋮
<row>
<entry>The "Z" Twiddle Switch</entry>
<entry><para>We're not entirely sure what this does. Our lab testers have
had various results from teleportation to spontaneous
liquification. <emphasis role="bold">Use at your own risk!</emphasis></para></entry>
</row>
</tbody>
</tgroup>
</table>
<note> <!-- SEE NOTE 10 -->
<para>A note to arthropods: Stop forcing your inflexible appendages to adopt
un-ergonomic positions. Our new claw-friendly control template is
available.</para>
</note>
</sect1>
<sect1>
<title>The View Screen</title>
<para>The view screen displays error messages and warnings, such as a
<errorcode>LOW-BATT</errorcode> (low battery) message.
<footnote> <!-- SEE NOTE 11 -->
<para>The advanced model now uses a direct psychic link to the user's
visual cortex, but it should appear approximately the same as the more
primitive liquid crystal display.</para>
</footnote>
When your &productname; starts up, it should
show a status display like this:</para>
<screen>STATUS DISPLAY <!-- SEE NOTE 12 -->
BATT: 1.782E8 V
TEMP: 284 K
FREQ: 9.32E3 Hz
WARRANTY: ACTIVE</screen>
</sect1>
<sect1>
<title>The Battery</title>
<para>Your &productname; is capable of generating tremendous amounts of
energy. For that reason, any old battery won't do. The power source is
a tiny nuclear reactor containing a piece of ultra-condensed plutonium
that provides up to 10 megawatts of power to your device. With a
half-life of over 20 years, it will be a long time before a
replacement is necessary.</para>
</sect1>
</chapter>
</book>
3.2.7.1 Notes
I'm taking the opportunity to declare some entities in the internal subset. This will save me some typing later.
Notice that all the major components (preface, chapter, sections) start with a title element. This is an example of how an element can be used in different contexts. In a formatted copy of this document, titles in different levels will be rendered differently. A stylesheet will use the hierarchical information (i.e., what is the ancestor of this title) to determine how to format it.
orderedlist is one of many types of lists available in DocBook. It produces the equivalent of HTML's ol element which formats with numbers. The formatter will generate numbers automatically, so you don't need to know how to count.
The systemitem inline element is rather generic, allowing for several types of "system" item, including computer domain names, URLs, FTP sites, and more.
It's a good idea to give sections ID attributes. Later, you may want to make a cross-reference to one of them. Remember that each ID attribute must have a unique value.
A comment element allows you to insert a message that is not part of the narrative, and will be removed before the final revision of the document is formatted. It's better than an actual XML comment object because it can be included in formatting for a draft printout.
This element constructs a figure, consisting of a title and an empty element that imports a graphic file.
The xref element is a cross-reference to another element in the document. The formatter will decide, based on the type of element referenced, what to put in its place. In this case, the object is a table, so we might expect to see something like "Table 3-1."
Here is another complex object, a table. DocBook's DTD doesn't define this element directly, but instead imports the definition from another DTD, an XML application called CALS (Continuous Acquisition and Life-Cycle Support). CALS was a Department of Defense project that made early use of SGML to improve its documentation. The CALS table model is very flexible and robust, so the DocBook framers felt it easier to borrow it than to reinvent the wheel.
A note is a new flow, similar to a sidebar. A formatter may or may not move it from this location, with no damage to the narrative, but it should stay relatively close to its origin.
This is how to code a footnote, another new flow. Footnotes are usually placed at the bottom of the page, but that notion is not clear when talking about web pages.
This element contains significant extra whitespace that needs to be preserved. The DTD has specified this for us, so we don't need to insert an xml:space attribute.
There are a lot of tools available for working with DocBook. For more information, see http://docbook.org.







