2.3 The Document Prolog
Being a flexible markup language toolkit, XML lets you use different character encodings, define your own grammars, and store parts of the document in many places. An XML parser needs to know about these particulars before it can start its work. You communicate these options to the parser through a construct called the document prolog.
The document prolog (if you use one) comes at the top of the document, before the root element. There are two parts (both optional): an XML declaration and a document type declaration.[2] The first sets parameters for basic XML parsing while the second is for more advanced settings. The XML declaration, if used, has to be the first line in the document. Example 2-1 shows a document containing a full prolog.
[2] Don't confuse document type declaration with document type definition, a completely different beast. To keep the two terms distinct, I will always refer to the latter one with the acronym "DTD."
Example 2-1. A document with a full prolog
<?xml version="1.0" standalone="no"?> The XML declaration
<!DOCTYPE Beginning of the DOCTYPE declaration
reminder Root element name
SYSTEM "/home/eray/reminder.dtd" DTD identifier
[ Internal subset start delimiter
<!ENTITY smile "<graphic file="smile.eps"/>"> Entity declaration
]> Internal subset end delimiter
<reminder> Start of document element
⌣ Reference to the entity declared above
<msg>Smile! It can always get worse.</msg>
</reminder> End of document element
2.3.1 The XML Declaration
The XML declaration is a small collection of details that prepare an XML processor for working with a document. It is optional, but when used it must always appear in the first line. Figure 2-3 shows the form it takes. It starts with the delimiter <?xml (1), contains a number of parameters (2), and ends with the delimiter ?> (3).
Figure 2-3. Form of the XML declaration
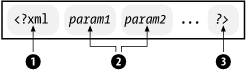
Each parameter consists of a name, an equals sign (=), and a quoted value. The version parameter must appear if the other parameters are used:
- version
-
Declares the version of XML used. At the moment, only version 1.0 is officially recognized, but version 1.1 may be available soon.
- encoding
-
Defines the character encoding used in the document. If undefined, the default encoding UTF-8 (or UTF-16, if the document begins with the xFEFF Byte Order Mark) will be used, which works fine for most documents used in English-speaking countries. Character encodings are explained in Chapter 9.
- standalone
-
Informs the parser whether there are any declarations outside of the document. As I explain in the next section, declarations are constructs that contribute information to the parser for assembling and validating a document. The default value is "no"; setting it to "yes" tells the processor there are no external declarations required for parsing the document. It does not, as the name may seem to imply, mean that no other resources need to be loaded. There could well be parts of the document in other files.
Parameter names and values are case-sensitive. The names are always lowercase. Order is important; the version must come before the encoding which must precede the standalone parameter. Either single or double quotes may be used. Here are some examples of XML declarations:
<?xml?> <?xml version="1.0"?> <?xml version='1.0' encoding='US-ASCII' standalone='yes'?> <?xml version = '1.0' encoding= 'iso-8859-1' standalone ="no"?>
2.3.2 The Document Type Declaration
There are two reasons why you would want to use a document type declaration. The first is to define entities or default attribute values. The second is to support validation, a special mode of parsing that checks grammar and vocabulary of markup. A validating parser needs to read a list of declarations for element rules before it can begin to parse. In both cases, you need to make declarations available, and the place to do that is in the document type declaration section.
Figure 2-4 shows the basic form of the document type declaration. It begins with the delimiter <!DOCTYPE (1) and ends with the delimiter > (7). Inside, the first part is an element name (2), which identifies the type of the document element. Next is an optional identifier for the document type definition (3), which may be a path to a file on the system, a URL to a file on the Internet, or some other kind of unique name meaningful to the parser. The last part, enclosed in brackets (4 and 6), is an optional list of entity declarations (5) called the internal subset. It complements the external document type definition which is called the external subset. Together, the internal and external subsets form a collection of declarations necessary for parsing and validation.
Figure 2-4. Form of the document type declaration
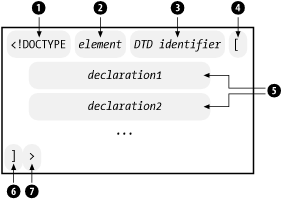
2.3.2.1 System and public identifiers
The DTD identifier supports two methods of identification: system-specific and public. A system identifier takes the form shown in Figure 2-5, the keyword SYSTEM (1) followed by a physical address (3) such as a filesystem path or URI, in quotes (2).
Figure 2-5. Form of the system identifier
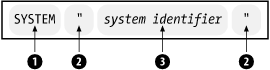
Here is an example with a system identifier. It points to a file called simple.dtd in the local filesystem.
<!DOCTYPE doc SYSTEM "/usr/local/xml/dtds/simple.dtd">
An alternative scheme to system identifiers is the public identifier. Unlike a system path or URI that can change anytime an administrator feels like moving things around, a public identifier is never supposed to change, just as a person may move from one city to another, but her social security number remains the same. The problem is that so far, not many parsers know what to do with public identifiers, and there is no single official registry mapping them to physical locations. For that reason, public identifiers are not considered reliable on their own, and must include an emergency backup system identifier.
Figure 2-6 shows the form of a public identifier. It starts with the keyword PUBLIC (1), and follows with a character string (3) in quotes (2), and the backup system identifier (4), also in quotes (2).
Figure 2-6. Form of the public identifier
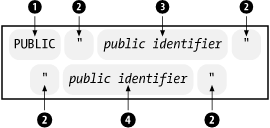
Here is an example with a public identifier:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2//EN" "http://www.w3.org/TR/HTML/html.dtd">
2.3.2.2 Declarations
Declarations are pieces of information needed to assemble and validate the document. The XML parser first reads declarations from the external subset (given by the system or public identifier), then reads declarations from the internal subset (the portion in square brackets) in the order they appear. In this chapter, I will only talk about what goes in the internal subset, leaving the external subset for Chapter 3.
There are several kinds of declarations. Some have to do with validation, describing what an element may or may not contain (again, I will go over these in Chapter 3). Another kind is the entity declaration, which creates a named piece of XML that can be inserted anywhere in the document.
The form of an entity declaration is shown in Figure 2-7. It begins with the delimiter <!ENTITY (1), is followed by a name (2), then a value or identifier (3), and the closing delimiter > (4).
Figure 2-7. Form of an entity declaration

The value or identifier portion may be a system identifier or public identifier, using the same forms shown in Figure 2-5 and Figure 2-6. This associates a name with a piece of XML in a file outside of the document. That segment of XML becomes an entity, which is a component of the document that the parser will insert before parsing. For example, this entity declaration creates an entity named chap2 out of the file ch02.xml:
<!ENTITY chap2 SYSTEM "ch02.xml">
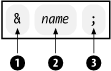
You can insert this entity in the document using an entity reference which takes the form in Figure 2-8. It consists of the entity name (2), bounded on the left by an ampersand (1), and on the right by a semicolon (3). You can insert it anywhere in the document element or one of its descendants. The parser will replace it with its value, taken from the external resource, before parsing the document.
Figure 2-8. Form of an entity reference
In this example, the entity reference is inserted in the XML inside a book element:
<book><title>My Exciting Book</title> &chap2; </book>
Alternatively, an entity declaration may specify an explicit value instead of a system or public identifier. This takes the form of a quoted string. The string can be mixed content (any combination of elements and character data). For example, this declaration creates an entity called jobtitle and assigns it the text <jobtitle>Herder of Cats</jobtitle>:
<!ENTITY jobtitle "<jobtitle>Herder of Cats</jobtitle>">
We're really just scratching the surface of entities. I'll cover entities in much greater depth later in the chapter.







