2.6 Miscellaneous Markup
Rounding out the list of markup objects are comments, processing instructions, and CDATA sections. They all have one thing in common: they shield content from the parser in some fashion. Comments keep text from ever getting to the parser. CDATA sections turn off the tag resolution, and processing instructions target specific processors.
2.6.1 Comments
Comments are notes in the document that are not interpreted by the XML processor. If you're working with other people on the same files, these messages can be invaluable. They can be used to identify the purpose of files and sections to help navigate a cluttered document, or simply to communicate with each other.
Figure 2-21 shows the form of a comment. It starts with the delimiter <!-- (1) and ends with the delimiter --> (3). Between these delimiters goes the comment text (2) which can be just about any kind of text you want, including spaces, newlines, and markup. The only string not allowed inside a comment is two or more dashes in succession, since the parser would interpret that string as the end of the comment.
Figure 2-21. Comment syntax

Comments can go anywhere in your document except before the XML declaration and inside tags. The XML processor removes them completely before parsing begins. So this piece of XML:
<p>The quick brown fox jumped<!-- test -->over the lazy dog. The quick brown <!-- test --> fox jumped over the lazy dog. The<!-- test -->quick brown fox jumped over the lazy dog.</p>
will look like this to the parser:
<p>The quick brown fox jumpedover the lazy dog. The quick brown fox jumped over the lazy dog. Thequick brown fox jumped over the lazy dog.</p>
Since comments can contain markup, they can be used to "turn off" parts of a document. This is valuable when you want to remove a section temporarily, keeping it in the file for later use. In this example, a region of code is commented out:
<p>Our store is located at:</p> <!-- <address>59 Sunspot Avenue</address> --> <address>210 Blather Street</address>
When using this technique, be careful not to comment out any comments, i.e., don't put comments inside comments. Since they contain double dashes in their delimiters, the parser will complain when it gets to the inner comment.
2.6.2 CDATA Sections
If you mark up characters frequently in your text, you may find it tedious to use the predefined entities <, >, and &. They require typing and are generally hard to read in the markup. There's another way to include lots of forbidden characters, however: the CDATA section.
CDATA is an acronym for "character data," which just means "not markup." Essentially, you're telling the parser that this section of the document contains no markup and should be treated as regular text. The only thing that cannot go inside a CDATA section is the ending delimiter (]]>).
A CDATA section begins with the nine-character delimiter <![CDATA[ (1), and it ends with the delimiter ]]> (3). The content of the section (2) may contain markup characters (<, >, and &), but they are ignored by the XML processor (see Figure 2-22).
Figure 2-22. CDATA section syntax
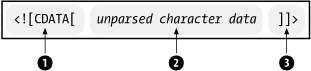
Here's an example of a CDATA section in action:
<para>Then you can say "<![CDATA[if (&x < &y)]]>" and be done with it.</para>
This is effectively the same as:
<para>Then you can say "if (&x < &y)" and be done with it.</para>
CDATA sections are convenient for large swaths of text that contains a lot of forbidden characters. However, the very thing that makes them useful can also be a problem. You will not be able to use any elements or attributes inside the marked region. If that's a problem for you, then you would probably be better off using character entity references or entities.
|
2.6.3 Processing Instructions
Presentational information should be kept out of a document whenever possible. Still, there may be times when you don't have any other option, for example, if you need to store page numbers in the document to facilitate generation of an index. This information applies only to a specific XML processor and may be irrelevant or misleading to others. The prescription for this kind of information is a processing instruction. It is a container for data that is targeted toward a specific XML processor.
Processing instructions (PIs) contain two pieces of information: a target keyword and some data. The parser passes processing instructions up to the next level of processing. If the processing instruction handler recognizes the target keyword, it may choose to use the data; otherwise, the data is discarded. How the data will help processing is up to the developer.
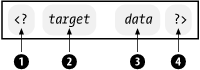
A PI (shown in Figure 2-23) starts with a two-character delimiter <? (1), followed by a target (2), an optional string of characters (3) that is the data portion of the PI, and a closing delimiter ?> (4).
Figure 2-23. Processing instruction syntax
"Funny," you say, "PIs look a lot like the XML declaration." You're right: the XML declaration can be thought of as a processing instruction for all XML processors[4] that broadcast general information about the document, though the specification defines it as a different thing.
[4] This syntactic trick allows XML documents to be processed by older SGML systems; they simply treat the XML declaration as another processing instruction, ignoring it since it obviously isn't meant for them.
The target is a keyword that an XML processor uses to determine whether the data is meant for it or not. The keyword doesn't necessarily mean anything, such as the name of the software that will use it. More than one program can use a PI, and a single program can accept multiple PIs. It's sort of like posting a message on a wall saying, "The party has moved to the green house," and people interested in the party will follow the instructions, while those who aren't interested won't.
The PI can contain any data except the combination ?>, which would be interpreted as the closing delimiter. Here are some examples of valid PIs:
<?flubber pg=9 recto?> <?thingie?> <?xyz stop: the presses?>
If there is no data string, the target keyword itself can function as the data. A forced line break is a good example. Imagine that there is a long section heading that extends off the page. Rather than relying on an automatic formatter to break the title just anywhere, we want to force it to break in a specific place.
Here is what a forced line break would look like:
<title>The Confabulation of Branklefitzers <?lb?>in a Portlebunky Frammins <?lb?>Without Denaculization of <?lb?>Crunky Grabblefooties </title>
Now you know all the ins and outs of markup. You can read and understand any XML document as if you were a living XML parser. But it still may not be clear to you why things are marked up as they are, or how to mark up a bunch of data. In the next chapter, I'll cover these issues as we look at the fascinating topic of data modeling.







