6.1 Nodes and Trees
Remember in Chapter 2 when we talked about trees and XML? I said that every XML document can be represented graphically with a tree structure. The reason that is important will now be revealed. Because there is only one possible tree configuration for any given document, there is a unique path from the root (or any point inside) to any other point. XPath simply describes how to climb the tree in a series of steps to arrive at a destination.
By the way, we will be slipping into some tree-ish terminology throughout the chapter. It's assumed you read the quick introduction to trees in Chapter 2. If you hear me talking about ancestors and siblings and have no idea what that has to do with XML, go back and refresh your vocabulary.
6.1.1 Node Types
Each step in a path touches a branching or terminal point in the tree called a node. In keeping with the arboreal terminology, a terminal node (one with no descendants) is sometimes called a leaf. In XPath, there are seven different kinds of nodes:
- Root
-
The root of the document is a special kind of node. It's not an element, as you might think, but rather it contains the document element. It also contains any comments or processing instructions that surround the document element.
- Element
-
Elements and the root node share a special property among nodes: they alone can contain other nodes. An element node can contain other elements, plus any other node type except the root node. In a tree, it would be the point where two branches meet. Or, if it is an empty element, it would be a leaf node.
- Attribute
-
For simplicity's sake, XPath treats attributes as separate nodes from their element hosts. This allows you to select the element as a whole, or merely the attribute in that element, using the same path syntax. An attribute is like an element that contains only text.
- Text
-
A region of uninterrupted text is treated as a leaf node. It is always the child of an element. An element may have more than one text node child, however, if it is broken up by elements or other node types. Keep that in mind if you process text in an element: you may have to check more than one node.
- Comment
-
Though technically it does not contribute anything to the content of the document, and most XML processors just throw it away, an XML comment is considered a valid node. This may be a way to express a document in such a way that it can be reconstructed down to the character (although, as I will explain later, this is not strictly possible). And who knows, maybe you want to keep the comments around.
- Processing instruction
-
Like comments, a processing instruction can appear anywhere in the document under the root node.
- Namespace
-
You might think it strange that a namespace declaration should be treated differently from an attribute. But think about this: a namespace is actually a region of the document, not just the possession of a single element. All the descendants of that element will be affected. XML processors must pay special attention to namespaces, so XPath makes it a unique node type.
What isn't included in this list is the DTD. You can't use XPath to poke around in the internal or external subsets. XPath just considers that information to be implicit and not worth accessing directly. It also assumes that any entity references are resolved before XPath enters the tree. This is probably a good thing, because entities can contain element trees that you would probably want to be able to reach.
It isn't strictly true that XPath will maintain all the information about a document so that you could later reconstruct it letter for letter. The structure and content are preserved, however, which makes it semantically equivalent. What this means is, if you were to slurp up the document into a program and then rebuild it from the structure in memory, it would probably not pass a diff [1] test. Little things would be changed, such as the order of attributes (attribute order is not significant in XML). Whitespace between elements may be missing or changed, and entities will all be resolved. To compare two semantically equivalent documents you'd need a special kind of tool. One that I know of in the Perl realm is the module XML::SemanticDiff, which will tell you if structure or content is the same.
[1] diff is a program in Unix that compares two text files and reports when any two lines are different. Even if one character is out of place, it will find and report that fact.
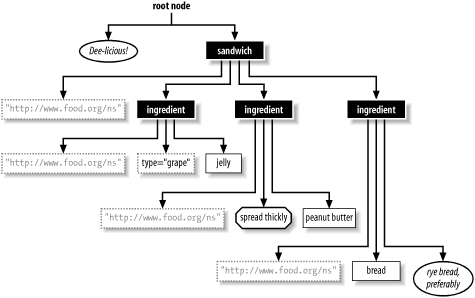
To show these nodes in their natural habitat, let's look at an example. The following document contains all the node types, and Figure 6-1 shows how it looks as a tree.
<!-- Dee-licious! -->
<sandwich xmlns="http://www.food.org/ns">
<ingredient type="grape">jelly</ingredient>
<ingredient><?knife spread thickly?>
peanut butter</ingredient>
<ingredient>bread
<!-- rye bread, preferably --></ingredient>
</sandwich>
Figure 6-1. Tree view showing all kinds of nodes
6.1.2 Trees and Subtrees
If you cut off a branch from a willow tree and plant it in the ground, chances are good it will sprout into a tree of its own. Similarly, in XML, any node in the tree can be thought of as a tree its own right. It doesn't have a root node, so that part of the analogy breaks down, but everything else is there: the node is like a document element, it has descendants, and it preserves the tree structure in a sort of fractal way. A tree fashioned from an arbitrary node is called a subtree.
For example, consider this XML document:
<?xml version="1.0"?>
<manual type="assembly" id="model-rocket">
<parts-list>
<part label="A" count="1">fuselage, left half</part>
<part label="B" count="1">fuselage, right half</part>
<part label="F" count="4">steering fin</part>
<part label="N" count="3">rocket nozzle</part>
<part label="C" count="1">crew capsule</part>
</parts-list>
<instructions>
<step>
Glue parts A and B together to form the fuselage.
</step>
<step>
Apply glue to the steering fins (part F) and insert them into
slots in the fuselage.
</step>
<step>
Affix the rocket nozzles (part N) to the fuselage bottom with a
small amount of glue.
</step>
<step>
Connect the crew capsule to the top of the fuselage. Do not use
any glue, as it is spring-loaded to detach from the fuselage.
</step>
</instructions>
</manual>
The whole document is a tree with manual as the root element (or document element); the parts-list and instructions elements are also in the form of trees, with roots and branches of their own.
XML processing techniques often rely on nested trees. Trees facilitate recursive programming, which is easier and more clear than iterative means. XSLT, for example, is elegant because a rule treats every element as a tree.
It's important to remember that you cannot take just any fragment of an XML document and expect it to form a node tree. It has to be balanced. In other words, there should be a start tag for every end tag. An unbalanced piece of XML is really difficult to work with in the XML environment, and certainly with XPath.







