3.3 Complex Data
XML really shines when data is complex. It turns the most abstract concepts into concrete databases ready for processing by software. Multimedia formats like Scalable Vector Graphics (SVG) and Synchronized Multimedia Integration Language (SMIL) map pictures and movies into XML markup. Complex ideas in the scientific realm are just as readily coded as XML, as proven by MathML (equations), the Chemical Markup Language (chemical formulae), and the Molecular Dynamics Language (molecule interactions).
3.3.1 Elements as Objects
The reason XML is so good at modelling complex data is that the same building blocks for narrative documentselements and attributescan apply to any composition of objects and properties. Just as a book breaks down into chapters, sections, blocks, and inlines, many abstract ideas can be deconstructed into discrete and hierarchical components. Vector graphics, for example, are composed of a finite set of shapes with associated properties. You can represent each shape as an element and use attributes to hammer down the details.
SVG is a good example of how to represent objects as elements. Take a gander at the simple SVG document in Example 3-7. Here we have three different shapes represented by as many elements: a common rectangle, an ordinary circle, and an exciting polygon. Attributes in each element customize the shape, setting color and spatial dimensions.
Example 3-7. An SVG document
<?xml version="1.0"?> <svg> <desc>Three shapes</desc> <rect fill="green" x="1cm" y="1cm" width="3cm" height="3cm"/> <circle fill="red" cx="3cm" cy="2cm" r="4cm"/> <polygon fill="blue" points="110,160 50,300 180,290"/> </svg>
Vector graphics are scalable, meaning you can stretch the image vertically or horizontally without any loss of sharpness. The image processor just recalculates the coordinates for you, leaving you to concentrate on higher concepts like composition, color, and grouping.
SVG adds other benefits too. Being an XML application, it can be tested for well-formedness, can be edited in any generic XML editor, and is easy to write software for. DTDs and Schema are available to check for missing information, and they provide an easy way to distinguish between versions.
Are there limitations? Of course. XML is not so good when it comes to raster graphics. This category of graphics formats, which includes TIFF, GIF and JPEG, renders an image based on pixel data. Instead of a conceptual representation based on shapes, it's a big fat array of numbers. You could store this in XML, certainly, but the benefits of markup are irrelevant since elements would only increase the document's size without organizing the data well. Furthermore, these formats typically use compression to force the huge amount of data into more manageable sizes, something markup would only complicate. (Video presents similar, larger, problems.)
What other concepts are ideally suited to XML representation? How about chemicals? Every molecule has a unique blueprint consisting of some combination of atoms and bonds. Languages like the Chemical Markup Language (CML) and Molecular Dynamics Language (MoDL) follow a similar strategy to encode molecules.
Example 3-8 shows how a water molecule would be coded in MoDL. Notice the separation of head and body that is reminiscent of HTML. The head is where we define atomic types, giving them size and color properties for rendering. The body is where we assemble the molecule using definitions from the head.
Example 3-8. A molecule definition in MoDL
<?xml version="1.0"?>
<modl>
<head>
<meta name="title" content="Water" />
<DEFINE name="Hydrogen">
<atom radius="0.2" color="1 1 0" />
</DEFINE>
<DEFINE name="Oxygen">
<atom radius="0.5" color="1 0 1" />
</DEFINE>
</head>
<body>
<atom id="H0" type="Hydrogen" position="1 0 0" />
<atom id="H1" type="Hydrogen" position="0 0 1" />
<atom id="O" type="Oxygen" position="0 1 0" />
<bond atom1="O" atom2="H0" color="0 0 1" />
<bond atom1="O" atom2="H1" color="0 0 1" />
</body>
</modl>
For each atom instance, there is an element describing its type, position, and a unique identifier (e.g., "H0" for the first hydrogen atom). Each bond between atoms also has its own element, specifying color and the two atoms it joins. Notice the interplay between atoms and bonds. The unique identifiers in the first group are the "hooks" for the second group, which use attributes that refer to them. Unique identifiers are another invaluable technique in expressing relationships between concepts.
MoDL is a project by Swami Manohar and Vijay Chandru of the Indian Institute of Science. The goal is not just to model molecules, but to model their interactions. The language contains elements to express motion as well as the static initial positions. Elements can represent actions applied to molecules, including translate and rotate.
Software developed for this purpose converts MoDL documents into a temporal-spatial format called Virtual Reality Markup Language (VRML). When viewed in a VRML reader, molecules dance around and bump into each other! Read more about MoDL at http://violet.csa.iisc.ernet.in/~modl/ and VRML at http://www.web3d.org.
Again, there are limitations. Movies, just like graphics, can be vector-based or rasterized. Formats like MPEG and MOV are compressed sequences of bitmaps, a huge amount of pixel information that XML would not be good at organizing. Simple shapes bouncing around in space are one thing, but complex scenes involving faces and puppy dogs are probably never going to involve XML.
3.3.2 Presentation Versus Conceptual Encoding
Moving up in complexity is mathematics. The Mathematics Markup Language (MathML) attacks this difficult area with two different modes of markup: presentational and conceptual. If we were describing an equation, we could do it in two ways. I could say "the product of A and B" or I could write on a chalkboard the more compact "A x B," both conveying the same idea. MathML allows you to use either style and mix them together in a document.
Consider the mathematical expression in Figure 3-3. This example was generated with MathML and displayed with Mozilla, which recognizes MathML as of version 1.1.
Figure 3-3. A complex fraction
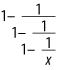
Example 3-9 is the MathML document used to generate this figure.
Example 3-9. Presentation encoding in MathML
<?xml version="1.0"?>
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mn>1</mn><mo>-</mo>
<mfrac><mrow><mn>1</mn></mrow>
<mrow><mn>1</mn><mo>-</mo>
<mfrac><mrow><mn>1</mn></mrow>
<mrow><mn>1</mn><mo>-</mo>
<mfrac><mrow><mn>1</mn></mrow>
<mrow><mi>x</mi></mrow>
</mfrac>
</mrow>
</mfrac>
</mrow>
</mfrac>
</math>
mfrac, as you may have guessed, sets up a fraction. It contains two elements called mrow, one each for the top and bottom. Notice how the denominator can itself contain a fraction. Take this recursively as far as you wish and it's perfectly legal in MathML. At the atomic level of expression are numbers, variables, and operators, which are marked up with the simple elements mn (number), mi (identifier), and mo (operator).
Conceptual encoding (also known as content encoding) is the name given for the other mode of MathML. It resembles functional programming, notably LISP, in that every sum, fraction, and product is represented as an operator followed by arguments all wrapped up in an apply element. Example 3-10 shows how the equation (2a + b)3 looks in MathML's content mode.
Example 3-10. Content encoding in MathML
<?xml version="1.0"?>
<math xmlns="http://www.w3.org/1998/Math/MathML">
<apply><power/>
<apply><plus/>
<apply><times/>
<cn>2</cn>
<ci>a</ci>
</apply>
<ci>b</ci>
</apply>
<cn>3</cn>
</apply>
</math>
Why the two modes of MathML? One reason is flexibility of authoring. But a more important reason is that each lends itself to a different means of processing. Presentational encoding is easier to render visually, and so is better supported in browsers and such. Content encoding, because it's more regular and closer to the meaning of the expression, is easier to process by calculator-type programs.
With support for MathML in browsers and other programs increasing, its popularity is growing. For more information, read A Gentle Introduction to MathML by Robert Miner and Jeff Schaeffer at http://www.dessci.com/en/support/tutorials/mathml/default.htm.







