6.4 XPointer
Closely related to XPath is the XML Pointer Language (XPointer). It uses XPath expressions to find points inside external parsed entities, as an extension to uniform resource identifiers (URIs). It could be used, for example, to create a link from one document to an element inside any other.
Originally designed as a component of the XML Linking Language (XLink), XPointer has become an important fragment identifier syntax in its own right. The XPointer Framework became a recommendation in 2003 along with the XPointer element( ) Scheme (allowing basic addressing of elements) and the XPointer xmlns( ) Scheme (incorporating namespaces). The xpointer( ) scheme itself is stuck at Working Draft, getting no further development.
An XPointer instance, which I'll just call an xpointer, works much like the fragment identifier in HTML (the part of a URL you sometimes see on the right side of a hash symbol). It's much more versatile than HTML's mechanism, however, as it can refer to any element or point inside text, not just to an anchor element (<a name="..."/>). By virtue of XPath, it has a few advantages over HTML fragment identifiers:
You can create a link to the target element itself, rather than to a proxy element (e.g., <a name="foo"/>.
You don't need to have anchors in the target document. You're free to link to any region in any document, whether the author knows about it or not.
The XPath language is flexible enough to reach any node in the target document.
XPointer actually goes further than XPath. In addition to nodes, it has two new location types. A point is any place inside a document between two adjacent characters. Whereas XPath would only locate an entire text node, XPointer can be more granular and locate a spot in the middle of any sentence. The other type introduced by XPointer is a range, defined as all the XML information between two points. This would be useful for, say, highlighting a region of text that may start in one paragraph and end in another.
Because of these new types, the return value of an XPointer is not a node set as is the case with XPath expressions. Instead, it is a more general location set, where a location is defined as a point, range, or node. A point is represented by a pair of objects: a container node (the closest ancestor element to the point), and a numeric index that counts the number of characters from the start of container node's content to the point. A range is simply two points, and the information inside it is called a sub-resource.
The XPointer specification makes no attempt to describe the behavior of an xpointer. It simply returns a list of nodes or strings to be processed, leaving the functionality up to the developer. This is a good thing because XPointer can be used in many different ways. When used in XLink, the information it describes may be imported into the source target, or left unloaded until the user actuates the link. A completely different application might be to use xpointers as hooks for annotations, stored in a local database. The user agent may use this information to insert icons into the formatted view of the target document that, when selected, bring up another window containing commentary. So by not explaining how XPointer is meant to be used, its flexibility is enhanced.
Whatever Happened to XLink?Plans for XLink were announced in the early days of XML. There were great expectations for it. The limitations of HTML links were to give way to a whole new world of possibilities, from customizable navigation views to third-party collections of documents, a document soup if you will. The recommendation is divided into two levels: simple and extended. Simple covers the traditional, inline hypertext links that we are all familiar with. Extended links are an exciting new mechanism, describing links between resources from either point, or even a third document. Now it is two years after XLink reached recommendation status (it took four years just to reach that point), and hardly any implementations are available. None of the web browsers available today offer extended link support, and only a few support even simple links. Why XLink failed to capture the imagination of developers and XML users may have to do with the popularity of embedded programming languages like JavaScript and Java. While XLink was slowly wending its way through the standards process, browser vendors quickly added support for various coding platforms to enable all kinds of stunts, including many of the problems XLink was meant to solve. Had XLink appeared sooner, its chances for success might well have been better, and I suspect it would have saved a lot of headaches for web site developers. All programming languages (yes, even Java) are platform-dependent solutions. They don't always work as expected, and they aren't well suited to archiving information for a long period of time. Perhaps XLink is an example of when the standards process does not work as advertised. Instead of inspiring developers to adopt a best practice, all it managed to inspire was a collective yawn. Whether it's because the recommendation fails to address the problem adequately, or it clashes with the marketing plans of commercial developers, or the new functionality does not justify the effort to implement it, these things do happen. |
6.4.1 Syntax
The following is an example of an xpointer:
xpointer(id('flooby')/child::para[2])
If successful, it will return a node corresponding to the second <para> child of the element whose id attribute has the value 'flooby'. If unsuccessful, it will return an empty location set.
6.4.1.1 Schemes and chained xpointers
The keyword xpointer is called a scheme, which serves to identify a syntax method and delimit the data inside. The data for an xpointer scheme is an XPath expression, or a shorthand form of one. There is no need to quote the XPath expression because the parentheses are sufficient to mark the start and end.
It is possible to chain together xpointers. They will be evaluated in order, until one is successful. For example:
xpointer(id('flooby'))xpointer(//*[@id='flooby'])
Here, the two xpointers semantically mean the same thing, but the first case may fail for an XPointer processor that does not implement id( ) properly. This could happen if the processor requires a DTD to tell it which attributes are of type ID, but no DTD is given. When the first expression returns an error, processing shunts over to the next xpointer as a fallback.
Besides xpointer, two other schemes are available: xmlns and element. The purpose of the xmlns scheme is to update the current evaluation environment with a new namespace declaration. Here, an xmlns declaration sets up a namespace prefix which is used in the xpointer that follows it:
xmlns(foo=http://www.hasenpfeffer.org/)xpointer(//foo:thingy)
It may seem odd, but the xmlns scheme returns an error status that forces processing to proceed on to the next part of the xpointer, using the definition of the foo namespace prefix.
The element scheme provides a syntactic shortcut. It represents the nth child of an element with a bare number. A string of numbers like this is called a child sequence and is defined in the XPointer element( ) Scheme recommendation. To find the third child of the fifth child of the element whose ID is flooby, you can use this xpointer:
element(flooby/5/3)
6.4.1.2 Shorthand pointers
A shorthand xpointer only contains a string that corresponds to the form of an ID type attribute. It substitutes for the id( ) term, making code easier to read and write. These two xpointers are equivalent:
flooby
xpointer(id('flooby'))
6.4.2 Points
A point inside a document is represented by two things: a container node and an index. The index counts the number of points from the start of a node, beginning with zero. If the point is inside text, the container is the text node in which it resides, not the element containing the text. The point may also lie outside of text, between two elements for instance.
Figure 6-2 shows how to find the index for points in a small piece of XML, listed here:
<para>These are <emphasis>strange</emphasis> times.</para>
Figure 6-2. Character points
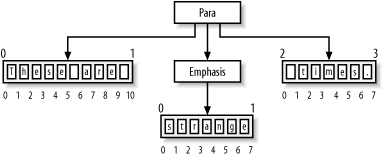
Inside each text node (and any node without children) are points between text characters, or character points. The point to the left of the first character is zero. The last point follows the last character in the text node, and its index is equal to the length of the string. It's important to note that the first point in the first text node of the example above is not equal to the first point of the element para. These are two separate points.
|
Inside each container node, the point whose index is zero is called the start point. The point with the highest index is the end point. (A range also has start and end points, but they might not come from the same container node.)
6.4.3 Character Escaping
XPointers have somewhat complex character escaping rules. This is a side effect of the fact that they can appear in different contexts. Inside an XML document, for example, the well-formedness rules apply. So characters like < and & must be represented with appropriate character entity references.
When using xpointers you always should be careful with three characters: left and right parentheses and the circumflex (^). Parentheses mark the beginning and end of data inside a location term, so any parenthesis that is meant to be data is liable to confuse an XPointer parser. The way to escape such a character is to precede it with a circumflex. As the circumflex is the escaping character, it too must be escaped if it appears on its own. Simply precede it with another circumflex.
If the xpointer is to be used inside a URI reference, then you need to respect the character escaping rules laid out in IETF RFC 2396. In this scheme, certain characters are represented with a percent symbol (%) and a hexadecimal number. For example, a space character would be replaced by %20 and a percent symbol by %25.
Here is an xpointer before escaping:
xpointer(string-range(//para,"I use parentheses (a lot)."))
You must at minimum escape it like so:
xpointer(string-range(//para,"I use parentheses ^(a lot^)."))
If the xpointer appears in an URI reference, some other characters need to be escaped, including the circumflexes:
xpointer(string-range(//para,"I%20use%20parentheses%20%5E(a%20lot%5E)."))
6.4.4 XPointer Functions
XPointer inherits from XPath all the functions and tests defined in that recommendation. To that set it adds a few specific to points and ranges.
6.4.4.1 Constructing ranges
The function range-to( ) creates a range starting from the context node and extending to the point given as its argument. In other words, it creates a range from the last step to the next step.
For example, suppose you have a document that defines index terms that each spans several pages. The element marking the start of the range is indexterm and has the attribute class="startofrange". The element ending the range is the same type, but has an attribute class="endofrange". The following xpointer would create a range for each pair of such elements:
xpointer(indexterm[@class='startofrange']/range-to(following:: indexterm[@class='endofrange']))
6.4.4.2 Ranges from points and nodes
The function range( ) returns the covering range for every location in its argument, the location set. A covering range is the range that exactly contains a location. For a point, the range's start and end points would equal that point (a zero-length, or collapsed, range). The covering range for a range is the range itself (same start and end points). For any other object, the covering range starts at the point preceding it and ends at the point following it, both of which belong to the object's container node.
The function range-inside( ) changes nodes into ranges. For each node in a given location set, the function treats it as a container node and finds the start and end points. Ranges and points are passed through unchanged.
6.4.4.3 Ranges from strings
To create ranges for arbitrary regions of text, you can use string-range( ). This function takes up to four arguments:
A location set, positions from which to search for strings.
A string, the pattern to match against.
An offset from the start of the match (default is 1).
The length of the result string, default being the length of the pattern in the second argument.
For example, this xpointer would locate the ninth occurrence of the word "excelsior" in a document:
xpointer(string-range(/,"excelsior")[9])
And this next xpointer would return a range for the eight characters following the string "username: " (with one space for padding) inside an element with id="user123". (Note that the indexing for characters is different from that for points. Here, the first character's position is 1, not zero.)
xpointer(string-range(id('user123'),"username: ",1,8))
Note that setting the length (the last argument) to zero would result in a range for a zero-length string. This collapsed range is effectively the same as a single point.
An interesting thing about string-range( ) is that it ignores the boundaries of nodes. It's as if all the content were dumped into a plain text file without XML tags. Effectively, text nodes are concatenated together into one long string of text. So in the following markup:
free as in <em>freedom</em>
This xpointer would match it whether the <em> tags were there or not:
xpointer(string-range(/,"free as in freedom")
6.4.4.4 Finding range endpoints
The functions start-range( ) and end-range( ) locate the points at the beginning and end of a range, respectively. Each takes one argument, a location set. If that set is a point, the returned value is the point itself. For nodes, the value would be the start or end point for the covering range of that node. These functions fail, however, for nodes of type attribute and namespace.
6.4.4.5 Returning points from documents
If the xpointer is inside an XML document, it can use the function here( ) to represent its location. This would be useful for, say, specifying the origin of a link. If the xpointer occurs inside a text node within an element, the return value is the element. Otherwise, the node that directly contains the xpointer is returned. Because the xpointer can only be at one place at any time, only one item is returned in the location set.
Another function is origin( ). It is only meaningful when used in the context of links, returning the location of the link's origin (where the user or program initiated traversal). This is necessary for complex link types defined in XLink where the link's information does not reside at either of the endpoints.







