5.3 Rule Matching
We will delve now into the details of selector syntax and all the ways a rule can match an element or attribute. Don't worry yet about what the properties actually mean. I'll cover all that in the next section. For now, concentrate on how rules drive processing and how they interact with each other.
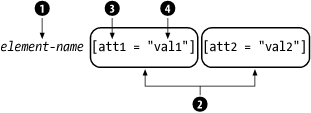
Figure 5-7 shows the general syntax for selectors. They typically consist of an element name (1) followed by some number of attribute tests (2) in square brackets, which in turn contain an attribute name (3) and value (4). Note that only an element or attribute is required. The other parts are optional. The element name can contain wildcards to match any element, and it can also contain chains of elements to specify hierarchical information. The attribute tests can check for the existence of an attribute (with any value), the existence of a value (for any attribute), or in the strictest case, a particular attribute-value combination.
Figure 5-7. Syntax for a CSS selector
5.3.1 Elements
Matching an element is as simple as writing its name:
emphasis {
font-style: italic;
font-weight: bold; }
This rule matches any emphasis element in the document. This is just the tip of the iceberg. There are many ways to qualify the selection. You can specify attribute names, attribute values, elements that come before and after, and even special conditions such as whether the cursor is currently hovering over a link, or in what language the document claims to be written.
A list of names is also allowed, letting you apply the same properties to many kinds of elements. Here, a set of three properties applies to any of the four elements, name, phone, email, and address:
name, phone, email, address {
display-type: block;
margin-top: 2em;
margin-bottom: 2em;
}
Besides using definite element names, you can use an asterisk (*) as a wildcard to match any element name. It's called the universal selector. For example, the following rule applies to any element in a document, setting the text color to blue:
* { color: blue }
Since this is a very general selector, it takes a low precedence in the set of rules. Any other element that defines a color property will override this rule.
5.3.2 Attributes
For a finer level of control, you can qualify the selection of elements by their attributes. An attribute selector consists of an element name immediately followed by the attribute refinement in square brackets. Varying levels of precision are available:
- planet[atmosphere]
-
This selector matches any planet element that has an atmosphere attribute. For example, it selects <planet atmosphere="poisonous"/> and <planet atmos-phere="breathable"/>, but not <planet/>.
You can leave out the element name if you want to accept any element that contains the attribute. The selector [atmosphere] matches both <planet atmosphere="dense"/> and <moon atmosphere="wispy"/>.
- planet[atmosphere="breathable"]
-
Adding a value makes the selector even more specific. This selector matches <planet atmosphere="breathable"/>, but it doesn't match <planet atmosphere="poisonous"/>.
- planet[atmosphere~="sweet"]
-
If the attribute's value is a space-separated list of strings, you can match any one of them by using the operator ~= instead of the equals sign (=). This selector matches <planet atmosphere="breathable sweet dense"/> or <planet atmos-phere="foggy sweet"/>, but it does not match <planet atmosphere="breathable stinky"/>.
- planet[populace|="barbaric"]
-
Similar to the item-in-list matching operator, a selector with the operator |= matches an item in a hyphen-separated value list, provided it begins with the value in the selector. This matches <planet populace="barbaric-hostile"/>.
This kind of selector is often used to distinguish between language types. The value of the XML attribute xml:lang is a language identifier, a string that looks like this: en-US. The two-character code "en" stands for "English" and the code "US" qualifies the United States variant. To match a planet element with an xml:lang attribute that specifies English, use the selector planet[language|="en"]. This selects both en-US and en-UK.
- planet[atmosphere="breathable"][populace="friendly"]
-
Selectors can string together multiple attribute requirements. To match, the attribute selectors must be satisfied, just as if they were bound with a logical AND operator. The above selector matches <planet atmosphere="breathable" populace="friendly"/> but not <planet populace="friendly"/>.
- #mars
-
This special form is used to match ID attributes. It matches <planet id="mars"/> or <candy-bar id="mars"/>, but not <planet id="venus"/>. Remember that only one element in the whole document can have an ID attribute with a given value, so this rule is very specific.
- planet.uninhabited
-
An attribute that is frequently used to designate special categories of an element for stylesheets is class. A shortcut for matching class attributes is the period, which stands for class=. The selector above matches <planet class="uninhabited"/> but doesn't match <planet class="colony"/>.
- planet:lang(en)
-
This selector form is used to match elements with a particular language specified. In pre-XML versions of HTML, language would be specified in a lang attribute. In XML, the attribute is xml:lang. The attribute values are matched in the same way as with the |= operator: a hyphenated item is a match if its name begins with a string identical to the one in the selector. The xml:lang attribute is an exception to XML's usual rules of case-sensitivity; values here are compared without regard to case. So in this example the selector matches <planet lang="en"/>, <planet lang="EN-us"/>, or <planet lang="en-US"/>, but not <planet lang="jp"/>.
5.3.3 Contextual Selection
Selectors can also use contextual information to match elements. This information includes the element's ancestry (its parent, its parent's parent, etc.) and siblings, and is useful for cases in which an element needs to be rendered differently depending on where it occurs.
5.3.3.1 Ancestry
You can specify that an element is a child of another element using the greater-than symbol (>). For example:
book > title { font-size: 24pt; }
chapter > title { font-size: 20pt; }
title { font-size: 18pt; }
The element to select here is title. If the title appears in a book, then the first rule applies. If it appears within a chapter, the second rule is chosen. If the title appears somewhere else, the last rule is used.
The > operator works only when there is one level separating the two elements. To reach an element at an arbitrary depth inside another element, list them in the selector, separated by spaces. For example:
table para { color: green }
para { color: black }
The first rule matches a para that occurs somewhere inside a table, like this:
<table>
<title>A plain ol' table</title>
<tgroup>
<tbody>
<row>
<entry>
<para>Hi! I'm a table cell paragraph.</para>
...
There's no limit to the number of elements you can string in a row. This is useful if you ever need to go far back into the ancestry to gather information. For example, say you want to use a list inside a list, perhaps to create an outline. By convention, the inner list should be indented more than the outer list. The following rules would provide you with up to three levels of nested lists:
list { indent: 3em }
list > list { indent: 6em }
list > list > list { indent: 9em }
The universal selector (*) can be used anywhere in the hierarchy. For example, given this content:
<chapter><title>Classification of Bosses</title>
<sect1><title>Meddling Types</title>
<sect2><title>Micromanagers</title>
...
You can match the last two title elements with this selector:
chapter * title
The first title is not selected, since the universal selector requires at least one element to sit between chapter and title.
5.3.3.2 Position
Often, you need to know where an element occurs in a sequence of same-level elements. For example, you might want to treat the first paragraph of a chapter differently from the rest, by making it all uppercase perhaps. To do this, add a special suffix to the element selector like this:
para:first-child { font-variant: uppercase; }
para:first-child matches only a para that is the first child of an element. A colon (:) followed by a keyword like first-child is called a pseudo-class in CSS. It provides extra information that can't be expressed in terms of element or attribute names. We saw another earlier: :lang.
Another way to examine the context of an element is to look its siblings. The sibling selector matches an element immediately following another. For example:
title + para { text-indent: 0 }
matches every para that follows a title and turns off its initial indent. This works only for elements that are right next to each other; there may be text in between, but no other elements.
You can select parts of an element's content with pseudo-element selectors. :first-line applies to the first line of an element as it appears in a browser. (This may vary, since the extent of the line depends on unpredictable factors such as window size.) With this selector, we can set the first line of a paragraph to all-caps, achieving a nice stylistic effect to open an article. This rule transforms the first line of the first para of a chapter to all capitals:
chapter > para:first-child:first-line {
text-transform: uppercase }
In a similar fashion, :first-letter operates solely on the first letter in an element's content, as well as any punctuation preceding the letter within the element. This is useful for drop caps and raised capitals:
body > p:first-child:first-letter {
font-size: 300%;
font-color: red }
With the pseudo-classes :before and :after, you can select a point just before or just after an element, respectively. This is most valuable for adding generated text: character data not present in the XML document. Figure 5-8 illustrates the following example:
warning > *:first-child:before {
content: "WARNING!";
font-weight: bold;
color: red }
Figure 5-8. Autogenerated text in an admonition object

5.3.4 Resolving Property Conflicts
We talked before about how multiple rules can match the same element. When that happens, all unique property declarations are applied. Conflicting properties have to be resolved with a special algorithm to find the "best" match.
Consider this stylesheet:
* {font-family: "ITC Garamond"}
h1 { font-size: 24pt }
h2 { font-size: 18pt }
h1, h2 { color: blue }
The h1 element matches three of these rules. The net effect is to render it with the font ITC Garamond at 24-point size in the color blue.
What if there's a conflict between two or more values for the same property? For example, there might be another rule in this stylesheet that says:
h1:first-child {
color: red
}
An h1 that is the first child of its parent would have conflicting values for the color property.
CSS defines an algorithm for resolving conflicts like these. The basic principle is that more specific selectors override more general selectors. The following list outlines the decision process:
IDs are more specific than anything else. If one rule has an ID selector and another doesn't, the one with the ID selector wins. More IDs are stronger than fewer, though given that IDs are unique within a document, a rule doesn't really need more than one.
More attribute selectors and pseudo-classes are stronger than fewer. This means that para:first-child is more specific than title + para, and that *[role="powerful"][class="mighty"] overrides para:first-child.
More specific genealogical descriptions win over less specific chains. So chapter > para has precedence over para, but not over title + para. Pseudo-elements don't count here.
If the selectors are still in a dead heat, there's a tie-breaking rule: the one that appears later in the stylesheet wins out.
Property value conflicts are resolved one property at a time. One rule might be more specific than another, but set only one property; other properties may be set by a less specific rule, even though one of the rule's properties has been overridden. So in our earlier example, the first h1 in an element gets the color red, not blue.







