Optical Character Recognition
Before I wrap up this discussion of Kooka, let me tell you about one other very cool thing the program does. Say you have an old document page that you want to transcribe. The obvious first choice is to sit it in front of you, open up a word processor, and start typing. Your second option is to pop that page on your scanner, use Kooka to scan it, then run it through OCR.
Here's how you do it. Because most people won't be using OCR, most distributions don't install the supporting software by default. Visit jocr.sourceforge.net (that is not a typo) or check your distribution CDs for a package called gocr and install it. Kooka uses it to do OCR.
Start by scanning your page as you would any image. Binary scan mode is probably fine for straight text but this is one case where the higher the resolution, the better your chances are of an accurate OCR. When you are happy with the preview, click Final Scan, and you should see your page in the right-hand window. Now click ImageCanvas on the menu bar, and select OCR image. Alternatively, you can click the second icon from the left in the icon bar?it does the same thing.
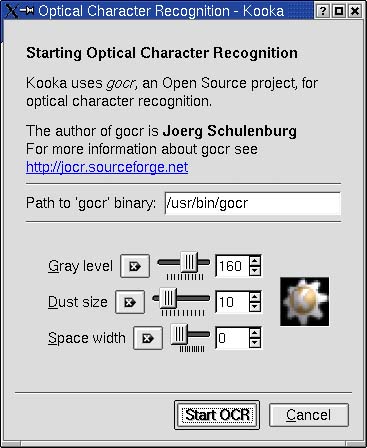
A window labeled Optical Character Recognition will pop up (Figure 16-9), which allows you to specify a handful of settings to tune the character recognition software. Remember; OCR is not perfect by any means but with some tweaking, you can achieve fairly high levels of accuracy. For your first scan, simply leave it at the defaults and click Start OCR. The whole process of character recognition may take a few seconds, so be patient.
Figure 16-9. OCR settings.
After the process is complete, a window will appear showing you the results of the OCR process (Figure 16-10).
Figure 16-10. Kooka OCR results window.
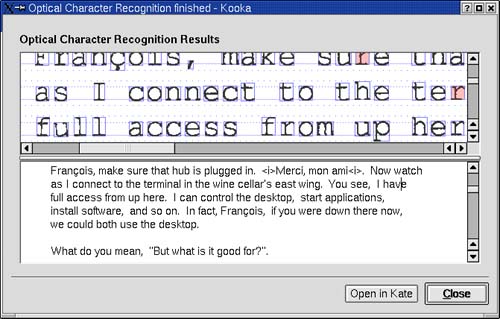
If you want to save the results, click Open in Kate, which will start KDE's multipurpose text editor. Once in the editor, click File from the menu bar, select Save As, and you'll be able to save the document in whatever directory you wish. Further editing can then be done with OpenOffice.org Writer or whatever word processor suits your needs.







