2.4 Elements
Elements are the building blocks of XML, dividing a document into a hierarchy of regions, each serving a specific purpose. Some elements are containers, holding text or elements. Others are empty, marking a place for some special processing such as importing a media object. In this section, I'll describe the rules for how to construct elements.
2.4.1 Syntax
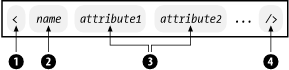
Figure 2-9 shows the syntax for a container element. It begins with a start tag consisting of an angle bracket (1) followed by a name (2). The start tag may contain some attributes (3) separated by whitespace, and it ends with a closing angle bracket (4). After the start tag is the element's content and then an end tag. The end tag consists of an opening angle bracket and a slash (5), the element's name again (2), and a closing bracket (4). The name in the end tag must match the one in the start tag exactly.
Figure 2-9. Container element syntax
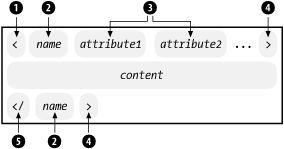
An empty element is very similar, as seen in Figure 2-10. It starts with an angle bracket delimiter (1), and contains a name (2) and a number of attributes (3). It is closed with a slash and a closing angle bracket (4). It has no content, so there is no need for an end tag.
Figure 2-10. Empty element syntax
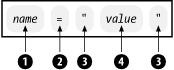
An attribute defines a property of the element. It associates a name with a value, which is a string of character data. The syntax, shown in Figure 2-11 is a name (1), followed by an equals sign (2), and a string (4) inside quotes (3). Two kinds of quotes are allowed: double (") and single ('). Quote characters around an attribute value must match.
Figure 2-11. Form of an attribute
Element naming must follow the rules of XML names, a generic term in the XML specification that also applies to names of attributes and some other kinds of markup. An XML name can contain any alphanumeric characters (a-z, A-Z, and 0-9), accented characters like ç, or characters from non-Latin scripts like Greek, Arabic, or Katakana. The only punctuation allowed in names are the hyphen (-), underscore (_) and period (.). The colon (:) is reserved for another purpose, which I will explain later. Names can only start with a letter, ideograph, or underscore. Names are case-sensitive, so Para, para, and pArA are three different elements.
The following elements are well-formed:
<to-do>Clean fish tank</to-do> <street_address>1420 Sesame Street</street_address> <MP3.name>Where my doggies at?</MP3.name> <a3/> <_-_>goofy, but legal</_-_>
These element names are not:
<-item>Bathe the badger</-item> <2nd-phone-number>785-555-1001</2nd-phone-number> <notes+comments>Huh?</notes+commments>
Technically, there is no limit to the length of an XML name. Practically speaking, anything over 50 characters is probably too long.
Inserting whitespace characters (tab, newline, and space) inside the tag is fine, as long as they aren't between the opening angle bracket and the element name. These characters are used to separate attributes. They are also often used to make tags more readable. In the following example, all of the whitespace characters are allowed:
<boat type="trireme" ><crewmember class="rower">Dronicus Laborius</crewmember >
There are a few important rules about the tags of container elements. The names in the start and end tags must be identical. An end tag has to come after (never before) the start tag. And both tags have to reside within the same parent element. Violating the last rule is an error called overlapping. It's an ambiguous situation where each element seems to contain the other, as you can see here:
<a>Don't <b>do</a> this!</b>
These untangled elements are okay:
<a>No problem</a><b>here</b>
Container elements may contain elements or character data or both. Content with both characters and elements is called mixed content. For example, here is an element with mixed content:
<para>I like to ride my motorcycle <emphasis>really</emphasis> fast.</para>
2.4.2 Attributes
In the element start tag you can add more information about the element in the form of attributes. An attribute is a name-value pair. You can use it to add a unique label to an element, place it in a category, add a Boolean flag, or otherwise associate some short string of data. In Chapter 1, I used an attribute in the telegram element to set a priority level.
One reason to use attributes is if you want to distinguish between elements of the same name. You don't always want to create a new element for every situation, so an attribute can add a little more granularity in differentiating between elements. In narrative applications like DocBook or HTML, it's common to see attributes like class and role used for this purpose. For example:
<message class="tip">When making crop circles, push down <emphasis>gently<emphasis> on the stalks to avoid breaking them.</message> <message class="warning">Farmers don't like finding people in their fields at night, so be <emphasis role="bold">very quiet</emphasis> when making crop circles.</message>
The class attribute might be used by a stylesheet to specify a special typeface or color. It might format the <message class="warning"> with a thick border and an icon containing an exclamation point, while the <message class="tip"> gets an icon of a light bulb and a thin border. The emphasis elements are distinguished in whether they have an attribute at all. The second does, and its purpose is to override the default style, whatever that may be.
Another way an attribute can distinguish an element is with a unique identifier, a string of characters that is unique to one particular element in the document. No other element may have the same identifier. This gives you a way to select that one element for special treatment, for cross referencing, excerpting, and so on.
For example, suppose you have a catalog with hundreds of product descriptions. Each description is inside a product element. You want to create an index of products, with one line per product. How do you refer to a particular product among hundreds? The answer is to give each a uniquely identifying label:
<product id="display-15-inch-apple"> ... </product> <product id="display-15-inch-sony"> ... </product> <product id="display-15-inch-ibm"> ... </product>
There is no limit to how many attributes an element can have, as long as no two attributes have the same name. Here's an example of an element start tag with three attributes:
<kiosk music="bagpipes" color="red" id="page-81527">
This example is not allowed:
<!-- Wrong --> <team person="sue" person="joe" person="jane">
To get around this limitation, you could use one attribute to hold all the values:
<team persons="sue joe jane">
You could also use attributes with different names:
<team person1="sue" person2="joe" person3="jane">
Or use elements instead:
<team> <person>sue</person> <person>joe</person> <person>jane</person> </team>
In a DTD, attributes can be declared to be of certain types. An attribute can have an enumerated value, meaning that the value must be one of a predefined set. Or it may have a type that registers it as a unique identifier (no other element can have the same value). It may be an identifier reference type, requiring that another element somewhere has an identifier attribute that matches. A validating parser will check all of these attribute types and report deviations from the DTD. I'll have more to say about declaring attribute types in Chapter 4.
|

2.4.3 Namespaces
Namespaces are a mechanism by which element and attribute names can be assigned to groups. They are most often used when combining different vocabularies in the same document, as I did in Chapter 1. Look at that example, and you'll see attributes in some elements like this one:
<math xmlns="http://www.w3.org/1998/Math/MathML">
Example 2-2 is another case. The part-catalog element contains two namespaces which are declared by the attributes xmlns:nw and xmlns. The elements inside part-catalog and their attributes belong to one or the other namespace. Those in the first namespace can be identified by the prefix nw:.
Example 2-2. Document with two namespaces
<part-catalog
xmlns:nw="http://www.nutware.com/"
xmlns="http://www.bobco.com/"
>
<nw:entry nw:number="1327">
<nw:description>torque-balancing hexnut</nw:description>
</nw:entry>
<part id="555">
<name>type 4 wingnut</name>
</part>
</part-catalog>
The attributes of part-catalog are called namespace declarations. The general form of a namespace declaration is illustrated in Figure 2-12. It starts with the keyword xmlns: (1) is followed by a namespace prefix (2), an equals sign (3), and a namespace identifier (5) in quotes (4).
Figure 2-12. Namespace declaration syntax
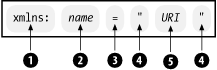
|
In a special form of the declaration, the colon and namespace prefix are left out, creating an implicit (unnamed) namespace. The second namespace declared in the example above is an implicit namespace. part-catalog and any of its descendants without the namespace prefix nw: belong to the implicit namespace.
|
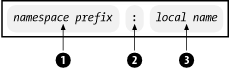
To include an element or attribute in a namespace other than the implicit namespace, you must use the form in Figure 2-13. This is called a fully qualified name. To the left of the colon (2) is the namespace prefix (1), and to the right is the local name (3).
Figure 2-13. Fully qualified name
Namespaces only affect a limited area in the document. The element containing the declaration and all of its descendants are in the scope of the namespace. The element's siblings and ancestors are not. It is also possible to override a namespace by creating another one inside it with the same name. In the following example, there are two namespaces named flavor, yet the chocolate-shell element is in a different namespace from the element chewy-center. The element flavor:walnut is in the latter namespace.
<flavor:chocolate-shell
xmlns:flavor="http://www.deliciouscandy.com/chocolate/">
<flavor:chewy-center
xmlns:flavor="http://www.deliciouscandy.com/caramel/">
<flavor:walnut/>
</flavor:chewy>
</flavor:chocolate-shell>
How an XML processor reacts when entering a new namespace depends on the application. For a web document, it may trigger a shift in processing from one kind (e.g., normal web text) to another (e.g., math formulae). Or, as in the case of XSLT, it may use namespaces to sort instructions from data where the former is kind of like a meta-markup.
Namespaces are a wonderful addition to XML, but because they were added after the XML specification, they've created a rather tricky problem. Namespaces do not get along with DTDs. If you want to test the validity of a document that uses non-implicit namespaces, chances are the test will fail. This is because there is no way to write a DTD to allow a document to use namespaces. DTDs want to constrain a document to a fixed set of elements, but namespaces open up documents to an unlimited number of elements. The only way to reconcile the two would be to declare every fully qualified name in the DTD which would not be practical. Until a future version of XML fixes this incompatibility, you will just have to give up validating documents that use multiple namespaces.
2.4.4 Whitespace
You'll notice in my examples, I like to indent elements to clarify the structure of the document. Spaces, tabs, and newlines (collectively called whitespace characters) are often used to make a document more readable to the human eye. Take out this visual padding and your eyes will get tired very quickly. So why not add some spaces here and there where it will help?
One important issue is how whitespace should be treated by XML software. At the parser level, whitespace is always passed along with all the other character data to the application level of the program. However, some programs may then normalize the space. This process strips out whitespace in element-only content, and in the beginning and end of mixed content. It also collapses a sequence of whitespace characters into a single space.
If you want to prevent a program from removing any whitespace characters from an element, you can give it a hint in the form of the xml:space attribute. If you set this attribute to preserve, XML processing software is supposed to honor the request by leaving all whitespace characters intact.
Consider this XML-encoded haiku:
<poem xml:space="preserve">
A wind shakes the trees,
An empty sound of sadness.
The file is not here.
</poem>
I took some poetic license by putting a bunch of spaces in there. (Hey, it's art!) So how do I keep the XML processor from throwing out the extra space in its normalization process? I gave the poem element an attribute named xml:space, and set its value to preserve. In Chapter 4, I'll show you how to make this the standard behavior for an element, by making the attribute implicit in the element declaration.
|
Some parsers, given a DTD for a document, will make reasonably smart guesses about which elements should preserve whitespace and which should not. Elements that are declared in a DTD to allow mixed content should preserve whitespace, since it may be part of the content. Elements not declared to allow text should have whitespace dropped, since any space in there is only to clarify the markup. However, you can't always rely on a parser to act correctly, so using the xml:space attribute is the safest option.
2.4.5 Trees
Elements can be represented graphically as upside-down, tree-like structures. The outermost element, like the trunk of a tree, branches out into smaller elements which in turn branch into other elements until the very innermost contentempty elements and character datais reached. You can think of the character data as leaves of the tree. Figure 2-14 shows the telegram document drawn as a tree.
Figure 2-14. A document tree
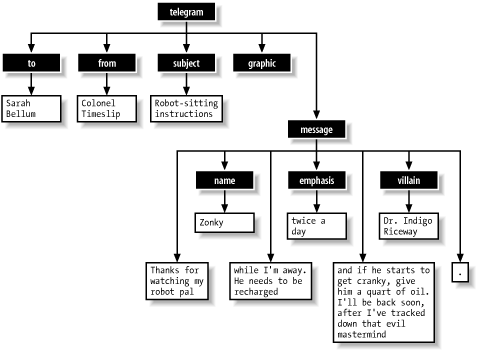
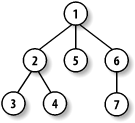
Since every XML document has only one possible tree, the diagram acts like a fingerprint, uniquely identifying the document. It's this unambiguous structure that makes XML so useful in containing data. The arboreal metaphor is also useful in thinking about how you would "move" through a document. Documents are parsed from beginning to end, naturally, which happens to correspond to a means of traversing a tree called depth-first searching. You start at the root, then move down the first branch to an element, take the first branch from there, and so on to the leaves. Then you backtrack to the last fork and take the next branch, as shown in Figure 2-15.
Figure 2-15. Depth-first search
Let me give you some terminology about XML trees. Every point in a treebe it an element, text, or something elseis called a node. This borrows from graph theory in mathematics, where a tree is a particular type of graph (directed, non-cyclic). Any branch of the tree can be snapped off and thought of as a tree too, just as you can plant the branch of a willow tree to make a new willow tree.[3] Branches of trees are often called subtrees or just trees. Collections of trees are appropriately called groves.
[3] Which is why you should never make fenceposts out of willow wood.
An XML tree or subtree (or subsubtree, or subsubsubtree . . . ) must adhere to the rules of well-formedness. In other words, any branch you pluck out of a document could be run through an XML parser, which wouldn't know or care that it wasn't a complete document. But a grove (group of adjacent trees) is not well-formed XML. In order to be well-formed, all of the elements must be contained inside just one, the document element.
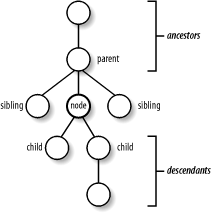
To describe elements in relation to one another, we use genealogical terms. Imagine that elements are like single-celled organisms, reproducing asexually. You can think of an element as the parent of the nodes it contains, known as its children. So the root of any tree is the progenitor of a whole family with numerous descendants. Likewise, a node may have ancestors and siblings. Siblings to the left (appearing earlier in the document) are preceding siblings while those to the right are following siblings. These relationships are illustrated in Figure 2-16.
Figure 2-16. Genealogical concepts
The tree model of XML is also important because it represents the way XML is usually stored in computer memory. Each element and region of text is packaged in a cell with pointers to children and parents, and has an object-oriented interface with which to manipulate data. This system is convenient for developers because actions, like moving document parts around and searching for text, are easier and more efficient when separated into tree structures.







