2.5 Entities
Entities are placeholders in XML. You declare an entity in the document prolog or in a DTD, and you can refer to it many times in the document. Different types of entities have different uses. You can substitute characters that are difficult or impossible to type with character entities. You can pull in content that lives outside of your document with external entities. And rather than type the same thing over and over again, such as boilerplate text, you can instead define your own general entities.
Figure 2-17 shows the different kinds of entities and their roles. In the family tree of entity types, the two major branches are parameter entities and general entities. Parameter entities are used only in DTDs, so I'll talk about them later, in Chapter 4. This section will focus on the other type, general entities.
Figure 2-17. Entity types
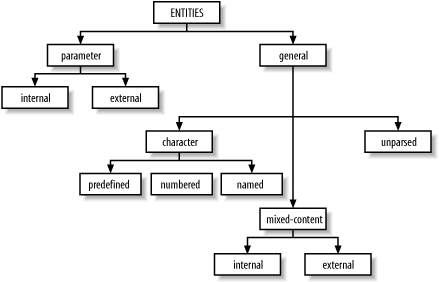
An entity consists of a name and a value. When an XML parser begins to process a document, it first reads a series of declarations, some of which define entities by associating a name with a value. The value is anything from a single character to a file of XML markup. As the parser scans the XML document, it encounters entity references, which are special markers derived from entity names. For each entity reference, the parser consults a table in memory for something with which to replace the marker. It replaces the entity reference with the appropriate replacement text or markup, then resumes parsing just before that point, so the new text is parsed too. Any entity references inside the replacement text are also replaced; this process repeats as many times as necessary.
Recall from Section 2.3.2 earlier in this chapter that an entity reference consists of an ampersand (&), the entity name, and a semicolon (;). The following is an example of a document that declares three general entities and references them in the text:
<?xml version="1.0"?> <!DOCTYPE message SYSTEM "/xmlstuff/dtds/message.dtd" [ <!ENTITY client "Mr. Rufus Xavier Sasperilla"> <!ENTITY agent "Ms. Sally Tashuns"> <!ENTITY phone "<number>617-555-1299</number>"> ]> <message> <opening>Dear &client;</opening> <body>We have an exciting opportunity for you! A set of ocean-front cliff dwellings in Piñata, Mexico, have been renovated as time-share vacation homes. They're going fast! To reserve a place for your holiday, call &agent; at ☎. Hurry, &client;. Time is running out!</body> </message>
The entities &client;, &agent;, and ☎ are declared in the internal subset of this document (discussed in Section 2.3.2) and referenced in the <message> element. A fourth entity, ñ, is a numbered character entity that represents the character ñ. This entity is referenced but not declared; no declaration is necessary because numbered character entities are implicitly defined in XML as references to characters in the current character set. (For more information about character sets, see Chapter 9.) The XML parser simply replaces the entity with the correct character.
The previous example looks like this with all the entities resolved:
<?xml version="1.0"?> <!DOCTYPE message SYSTEM "/xmlstuff/dtds/message.dtd"> <message> <opening>Dear Mr. Rufus Xavier Sasperilla</opening> <body>We have an exciting opportunity for you! A set of ocean-front cliff dwellings in Piñata, Mexico, have been renovated as time-share vacation homes. They're going fast! To reserve a place for your holiday, call Ms. Sally Tashuns at <number>617-555-1299</number>. Hurry, Mr. Rufus Xavier Sasperilla. Time is running out!</body> </message>
All entities (besides predefined ones, which I'll describe in a moment) must be declared before they are used in a document. Two acceptable places to declare them are in the internal subset, which is ideal for local entities, and in an external DTD, which is more suitable for entities shared between documents. If the parser runs across an entity reference that hasn't been declared, either implicitly (a predefined entity) or explicitly, it can't insert replacement text in the document because it doesn't know what to replace the entity with. This error prevents the document from being well-formed.
2.5.1 Character Entities
Entities that contain a single character are called, naturally enough, character entities. These fall into a few groups:
- Predefined character entities
-
Some characters cannot be used in the text of an XML document because they conflict with the special markup delimiters. For example, angle brackets (<>) are used to delimit element tags. The XML specification provides the following predefined character entities, so you can express these characters safely.
|
Entity |
Value |
|---|---|
|
amp |
& |
|
apos |
' |
|
gt |
> |
|
lt |
< |
|
quot |
" |
- Numeric references
-
XML supports Unicode, a huge character set with tens of thousands of different symbols, letters, and ideograms. You should be able to use any Unicode character in your document. It isn't easy, however, to enter a nonstandard character from a keyboard with less than 100 keys, or to represent one in a text-only editor display. One solution is to use a numbered character reference which refers to the character by its number in the Unicode character set.
The number in the entity name can be expressed in decimal or hexadecimal format. Figure 2-18 shows the form of a numeric character entity reference with a decimal number, consisting of the delimiter &# (1), the number (2), and a semicolon (3).
Figure 2-18. Numeric character reference (decimal)
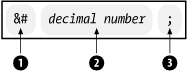
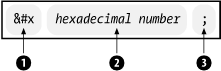
Figure 2-19 shows another form using a hexadecimal number. The difference is that the start delimiter includes the letter "x."
Figure 2-19. Numeric character entity reference (hexadecimal)
For example, a lowercase c with a cedilla (ç) is the 231st Unicode character. It can be represented in decimal as ç or in hexadecimal as ç. Note that the hexadecimal version is distinguished with an x as the prefix to the number. Valid characters are #x9, #xA, #xD, #x20 through #xD7FF, #xE000 through #xFFFD, and #x10000 through #x10FFFF. Since not all hexadecimal numbers map to valid characters, this is not a continuous range. I will discuss character sets and encodings in more detail in Chapter 9.
- Named character entities
-
The problem with numbered character references is that they're hard to remember: you need to consult a table every time you want to use a special character. An easier way to remember them is to use mnemonic entity names. These named character entities use easy-to-remember names like Þ, which stands for the Icelandic capital thorn character (
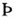 ).
).Unlike the predefined and numeric character entities, you do have to declare named character entities. In fact, they are technically no different from other general entities. Nevertheless, it's useful to make the distinction, because large groups of such entities have been declared in DTD modules that you can use in your document. An example is ISO-8879, a standardized set of named character entities including Latin, Greek, Nordic, and Cyrillic scripts, math symbols, and various other useful characters found in European documents.
2.5.2 Mixed-Content Entities
Entity values aren't limited to a single character, of course. The more general mixed-content entities have values of unlimited length and can include markup as well as text. These entities fall into two categories: internal and external. For internal entities, the replacement text is defined in the entity declaration; for external entities, it is located in another file.
2.5.2.1 Internal entities
Internal mixed-content entities are most often used to stand in for oft-repeated phrases, names, and boilerplate text. Not only is an entity reference easier to type than a long piece of text, but it also improves accuracy and maintainability, since you only have to change an entity once for the effect to appear everywhere. The following example proves this point:
<?xml version="1.0"?> <!DOCTYPE press-release SYSTEM "http://www.dtdland.org/dtds/reports.dtd" [ <!ENTITY bobco "Bob's Bolt Bazaar, Inc."> ]> <press-release> <title>&bobco; Earnings Report for Q3</title> <par>The earnings report for &bobco; in fiscal quarter Q3 is generally good. Sales of &bobco; bolts increased 35% over this time a year ago.</par> <par>&bobco; has been supplying high-quality bolts to contractors for over a century, and &bobco; is recognized as a leader in the construction-grade metal fastener industry.</par> </press-release>
The entity &bobco; appears in the document five times. If you want to change something about the company name, you only have to enter the change in one place. For example, to make the name appear inside a companyname element, simply edit the entity declaration:
<!ENTITY bobco "<companyname>Bob's Bolt Bazaar, Inc.</companyname>">
When you include markup in entity declarations, be sure not to use the predefined character entities (e.g., < and >) to escape the markup. The parser knows to read the markup as an entity value because the value is quoted inside the entity declaration. Exceptions to this are the quote-character entity " and the single-quote character entity '. If they would conflict with the entity declaration's value delimiters, then use the predefined entities, e.g., if your value is in double quotes and you want it to contain a double quote.
Entities can contain entity references, as long as the entities being referenced have been declared previously. Be careful not to include references to the entity being declared, or you'll create a circular pattern that may get the parser stuck in a loop. Some parsers will catch the circular reference, but it is an error.
2.5.2.2 External entities
Sometimes you may need to create an entity for such a large amount of mixed content that it is impractical to fit it all inside the entity declaration. In this case, you should use an external entity, an entity whose replacement text exists in another file. External entities are useful for importing content that is shared by many documents, or that changes too frequently to be stored inside the document. They also make it possible to split a large, monolithic document into smaller pieces that can be edited in tandem and that take up less space in network transfers.
External entities effectively break a document into multiple physical parts. However, all that matters to the XML processor is that the parts assemble into a perfect whole. That is, all the parts in their different locations must still conform to the well-formedness rules. The XML parser stitches up all the pieces into one logical document; with the correct markup, the physical divisions should be irrelevant to the meaning of the document.
External entities are a linking mechanism. They connect parts of a document that may exist on other systems, far across the Internet. The difference from traditional XML links (XLinks) is that for external entities the XML processor must insert the replacement text at the time of parsing.
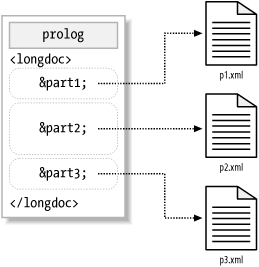
External entities must always be declared so the parser knows where to find the replacement text. In the following example, a document declares the three external entities &part1;, &part2;, and &part3; to hold its content:
<?xml version="1.0"?> <!DOCTYPE doc SYSTEM "http://www.dtds-r-us.com/generic.dtd" [ <!ENTITY part1 SYSTEM "p1.xml"> <!ENTITY part2 SYSTEM "p2.xml"> <!ENTITY part3 SYSTEM "p3.xml"> ]> <longdoc> &part1; &part2; &part3; </longdoc>
As shown in Figure 2-20, the file at the top of the pyramid, which we might call the "master file," contains the document declarations and external entity references. The other files are subdocumentsthey contain XML, but are not documents in their own right. You could not legally insert document prologs in them. Each may contain more than one XML tree. Though you can't validate them individually (you can only validate a complete document), any errors in a subdocument will affect the whole. External entities don't shield you from parse errors.
Figure 2-20. Document with external entities
|

The syntax just shown for declaring an external entity uses the keyword SYSTEM followed by a quoted string containing a filename. This string is called a system identifier and is used to identify a resource by location. The quoted string is actually a URL, so you can include files from anywhere on the Internet. For example:
<!ENTITY catalog SYSTEM "http://www.bobsbolts.com/catalog.xml">
The system identifier suffers from the same drawback as all URLs: if the referenced item is moved, the link breaks. To avoid that problem, you can use a public identifier in the entity declaration. In theory, a public identifier will endure any location shuffling and still fetch the correct resource. For example:
<!ENTITY faraway PUBLIC "-//BOB//FILE Catalog//EN"
"http://www.bobsbolts.com/catalog.xml">
Of course, for this to work, the XML processor has to know how to use public identifiers, and it must be able to find a catalog that maps them to actual locations. In addition, there's no guarantee that the catalog is up to date. A lot can go wrong. Perhaps for this reason, the public identifier must be accompanied by a system identifier (here, "http://www.bobsbolts.com/catalog.xml"). If the XML processor for some reason can't handle the public identifier, it falls back on the system identifier. Most web browsers in use today can't deal with public identifiers, so including a backup is a good idea.
|
2.5.3 Unparsed Entities
The last kind of entity discussed in this chapter is the unparsed entity. This kind of entity holds content that should not be parsed because it contains something other than text or XML and would likely confuse the parser. The only place from which unparsed entities can be referred to is in an attribute value. They are used to import graphics, sound files, and other noncharacter data.
The declaration for an unparsed entity looks similar to that of an external entity, with some additional information at the end. For example:
<!DOCTYPE doc [ <!ENTITY mypic SYSTEM "photos/erik.gif" NDATA GIF> ]> <doc> <para>Here's a picture of me:</para> <graphic src="&mypic;" /> </doc>
This declaration differs from an external entity declaration in that there is an NDATA keyword following the system path information. This keyword tells the parser that the entity's content is in a special format, or notation, other than the usual parsed mixed content. The NDATA keyword is followed by a notation identifier that specifies the data format. In this case, the entity is a graphic file encoded in the GIF format, so the word GIF is appropriate.







