3.1 Simple Data Storage
XML can be used like an extremely basic database. Since the early days of computer operating systems, data has been stored in files as tables, like the venerable /etc/passwd file:
nobody:*:-2:-2:Unprivileged User:/nohome:/noshell root:*:0:0:System Administrator:/var/root:/bin/tcsh daemon:*:1:1:System Services:/var/root:/noshell smmsp:*:25:25:Sendmail User:/private/etc/mail:/noshell
Data like this isn't too hard to parse, but it has problems, too. Certain characters aren't allowed. Each record lives on a separate line, so data can't span lines. A syntax error is easy to create and may be difficult to locate. XML's explicit markup gives it natural immunity to these types of problems.
If you are writing a program that reads or saves data to a file, there are good reasons to go with XML. Parsers have been written to parse it already, so all you need to do is link to a library and use one of several easy interfaces: SAX, DOM, or XPath. Syntax errors are easy to catch, and that too is automated by the parser. Technologies like DTDs and Schema even check the structure and contents of elements for you, to ensure completeness and ordering.
3.1.1 Dictionaries
A dictionary is a simple one-to-one mapping of properties to values. A property has a name, or key, which is a unique identifier. A dictionary is kind of like a table with two columns. It's a simple but very effective way to serialize data.
In the Macintosh OS X operating system, Apple selected XML as its format for preference files (called property lists). For the Chess program, the property list is in a file called com.apple.Chess.plist, shown here:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist SYSTEM "file://localhost/System/Library/DTDs/PropertyList.dtd">
<plist version="0.9">
<dict>
<!-- KEY VALUE -->
<key>BothSides</key> <false/>
<key>Level</key> <integer>1</integer>
<key>PlayerHasWhite</key> <true/>
<key>SpeechRecognition</key> <false/>
</dict>
</plist>
Here the data is stored in a tabular form within a dict (dictionary) element. Each "row" is a pair of elements, the first a key (the name of a property), and the second a value. Values come in different types, such as the Boolean (true or false) and integer values you see here. The property SpeechRecognition is assigned the boolean value FALSE, which means that this feature is turned off in the program. The property Level (difficulty level) is set to 1 because I'm a lousy chess player.
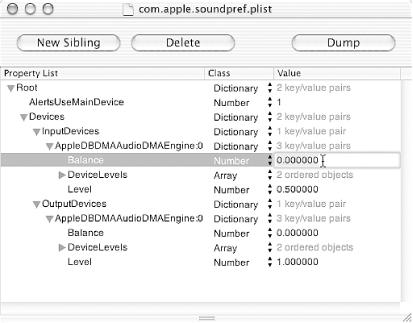
Here's a more complex example. It's the property list for system sounds, com.apple.soundpref.plist:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/
DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>AlertsUseMainDevice</key> <integer>1</integer>
<key>Devices</key>
<dict>
<key>InputDevices</key>
<dict>
<key>AppleDBDMAAudioDMAEngine:0</key>
<dict>
<key>Balance</key> <real>0.0</real>
<key>DeviceLevels</key> <array>
<real>0.5</real>
<real>0.5</real>
</array>
<key>Level</key> <real>0.5</real>
</dict>
</dict>
<key>OutputDevices</key>
<dict>
<key>AppleDBDMAAudioDMAEngine:0</key>
<dict>
<key>Balance</key> <real>0.0</real>
<key>DeviceLevels</key> <array>
<real>1</real>
<real>1</real>
</array>
<key>Level</key> <real>1</real>
</dict>
</dict>
</dict>
</dict>
</plist>
In this example, the structure is recursive. A dict can be a value, allowing you to associate a key with a whole set of settings. This allows for better organization by creating categories like Devices and, under that, subcategories like InputDevices and OutputDevices. Notice also the array type, which associates multiple values to one key. Here, arrays are used to set the left and right volume levels.
I really like this way of storing preferences because it gives me two ways to access the data. I can fiddle with settings in the program's preferences window. The program would then update this XML file the moment I click on the "OK" button. Alternatively, I can edit the file myself. This may be an easier way to affect changes, especially if some features aren't addressed in the GUI. I can edit it in a text editor, or in the special application included with the Macintosh OS called Property List Editor, whose interface is very easy to use, as shown in Figure 3-1.
Figure 3-1. Apple's Property List Editor
3.1.2 Records
A database typically stores information in records, packages of data that follow the same pattern as dictionaries. There are lots of records, each with the same set of data fields, sometimes accessed by a unique identifier. For example, a personnel database would have a record for each employee. Example 3-1 is a simple record-style XML document used for expense tracking.
Example 3-1. A checkbook document
<?xml version="1.0"?>
<checkbook balance-start="2460.62">
<title>expenses: january 2002</title>
<debit category="clothes">
<amount>31.19</amount>
<date><year>2002</year><month>1</month><day>3</day></date>
<payto>Walking Store</payto>
<description>shoes</description>
</debit>
<deposit category="salary">
<amount>1549.58</amount>
<date><year>2002</year><month>1</month><day>7</day></date>
<payor>Bob's Bolts</payor>
</deposit>
<debit category="withdrawal">
<amount>40</amount>
<date><year>2002</year><month>1</month><day>8</day></date>
<description>pocket money</description>
</debit>
<debit category="savings">
<amount>25</amount>
<date><year>2002</year><month>1</month><day>8</day></date>
</debit>
<debit category="medical" check="855">
<amount>188.20</amount>
<date><year>2002</year><month>1</month><day>8</day></date>
<payto>Boston Endodontics</payto>
<description>cavity</description>
</debit>
<debit category="supplies">
<amount>10.58</amount>
<date><year>2002</year><month>1</month><day>10</day></date>
<payto>Exxon Saugus</payto>
<description>gasoline</description>
</debit>
<debit category="car">
<amount>909.56</amount>
<date><year>2002</year><month>1</month><day>14</day></date>
<payto>Honda North</payto>
<description>car repairs</description>
</debit>
<debit category="food">
<amount>24.30</amount>
<date><year>2002</year><month>1</month><day>15</day></date>
<payto>Johnny Rockets</payto>
<description>lunch</description>
</debit>
</checkbook>
Each record is either a debit (expense) or a deposit (income). It contains information about the expense/income category, to whom I paid money (or received money from), the date it happened, and a brief description. I have used documents like this to balance my checkbook and summarize expenses in tables so I can figure out where all my money goes.
How can you do this? I'll show you a quick program you can write in Perl to calculate the ending balance in the previous example. Example 3-2 shows a program that spits out a number on the command line.
Example 3-2. A tabulate program
#!/usr/bin/perl
use XML::LibXML;
my $parser = new XML::LibXML;
my $doc = $parser->parse_file( shift @ARGV );
my $balance = $doc->findvalue( '/checkbook/@balance-start' );
foreach my $record ( $doc->findnodes( '//debit' )) {
$balance -= $record->findvalue( 'amount' );
}
foreach my $record ( $doc->findnodes( '//deposit' )) {
$balance += $record->findvalue( 'amount' );
}
print "Current balance: $balance\n";
The library XML::LibXML parses the document and stores it in an object tree called $doc. This object supports two interfaces: DOM and XPath. I used XPath queries as arguments to the methods findnodes( ) and findvalue( ) to reach into parts of the document and pull out elements and character data. What could be easier?
Run the above program on the data file and you'll get:
$ tab data Current balance: 2781.37
This example shows how XML makes reading and accessing data easy for the programmer. What's more, the XML is flexible enough to allow you to restructure the data without rewriting the program. Adding new fields, such as an ID attribute or a time element, wouldn't affect the program a bit. With an ad hoc solution like the colon-delimited /usr/passwd file, you would not have that kind of flexibility.
3.1.3 XML and Databases
XML is very good at modelling simple data structures like the examples you've seen so far. We've seen all kinds of data types represented: strings, integers, real numbers, arrays, dictionaries, records. XML is easier to modify than flat files, with minimal impact on processing software, so you can add or remove fields as you like. Writing programs to process the data is easy, since much of the parsing work has been abstracted out, and plenty of interfaces are available. Since XML support is ubiquitous, there are many ways to modify the data.
The downside is that XML is not optimized for rapid, repetitive access. An XML parser has to read the entire document to pick out even a single detail, a huge overhead for one lookup. As the document grows, the access time gets longer. Storing it in memory isn't much better, since searches are not optimized for finding records by unique identifier. It's not as bad as doing an exhaustive search through many files, but not as good as a true database.
Dedicated databases are designed to store data in a way that is independent of the size and number of records. They are fast, but they lack the flexibility and ease of access of XML. A data processing program must access the data indirectly, through an interface like SQL. This can be cumbersome because data is stored in separate rows of a table, and it make take several queries to reach the right data point. Even worse, no two databases work the same way. Each has its quirks and refinements that make it difficult or impossible to write universal software without some kind of middleware adapter.
Storing data as XML versus storing it in a database does not have to be an exclusive choice. There is no reason why you can't do both at once. One technique I have used is to store XML in a database. Consider the document in Example 3-3. It contains a number of villain elements, each with an id attribute containing a unique identifier.
Example 3-3. An XML document to put in a database
<villain-database>
<villain id="v1">
<name>Darth Vader</name>
<evil>8</evil>
<intelligence>9</intelligence>
<fashion>5</fashion>
</villain>
<villain id="v3">
<name>Doctor Evil</name>
<evil>6</evil>
<intelligence>6</intelligence>
<fashion>8</fashion>
</villain>
<villain id="v4">
<name>Scorpius</name>
<evil>9</evil>
<intelligence>9</intelligence>
<fashion>4</fashion>
</villain>
</villain-database>
You want to be able to access a villain by id attribute. As an XML document, this access would be slow. If the record is near the bottom, the XML processor needs to read through most of the document before it gets there. With thousands of villain elements, that search could take a very long time.
Now let us create a database with a table that matches the following schema. I will use SQL data types.
|
Field |
Data type |
|---|---|
|
id |
varchar(8) |
|
content |
text |
You can store the information from Example 3-3 in the database. Each villain element will be a row in the table we just created. Get the id from the attribute in villain, and put the rest of the element in the content field. Here is what the table would look like:
|
id |
content |
|---|---|
|
v1 |
<villain> <name>Darth Vader</name> <evil>8</evil> <intelligence>9</intelligence> <fashion>5</fashion> </villain> |
|
v3 |
<villain> <name>Doctor Evil</name> <evil>6</evil> <intelligence>6</intelligence> <fashion>8</fashion> </villain> |
|
v4 |
<villain> <name>Scorpius</name> <evil>9</evil> <intelligence>9</intelligence> <fashion>4</fashion> </villain> |
In this arrangement, you can search quickly for records using the id as a primary key. The content field still contains the content of each record as XML. An advantage to keeping XML in a field is that you can add or remove elements any time without affecting the rest of the database. A disadvantage to storing data in elements instead of fields is that you can't use the database's built-in functionality, such as searching on one of those fields or checking the validity of an element's value. If you only need to search for a record using the id and will validate the content on your own, then this method works well. A good application of this arrangement is a web content management system, where the content is HTML to be served as a page.
Another way to combine the performance of databases with the convenience of XML is to convert database queries into XML. You store the data exclusively in the database's native field types, but when you retrieve information, a piece of code translates it into XML in real time. For example, someone may write a SAX driver tailored to the particular brand of database you are using. It would be simple to write a program that interfaces with this driver to assemble an XML document containing requested data. We will go over SAX in Chapter 10.







