9.1 Character Encodings
Throughout the book, I have treated characters as a sort of commodity, just something used to fill up documents. But understanding characters and how they are represented in documents is of great importance in XML. After all, characters are both the building material for markup and the cargo it was meant to carry.
Every XML document has a character encoding property. I'll give you a quick explanation now and a more complete description later. In a nutshell, it is the way the numerical values in files and streams are transformed into the symbols that you see on the screen. Encodings come in many different kinds, reflecting the cultural diversity of users, the capabilities of systems, and the inevitable cycle of progress and obsolescence.
Character encodings are probably the most confusing topic in the study of XML. Partly, this is because of a glut of acronyms and confusing names: UTF-8, UCS-4, Shift-JIS, and ISO-8859-1-Windows-3.1-Latin-1, to name a few. Also hampering our efforts to understand is the interchangeability of incompatible terms. Sometimes a character encoding is called a set, as in the MIME standard, which is incorrect and misleading.
In this section, I will try to explain the terms and concepts clearly, and describe some of the common character encodings in use by XML authors.
9.1.1 Specifying an Encoding
If you choose to experiment with the character encoding for your document, you will need to specify it in the XML declaration. For example:
<?xml version="1.0" encoding="encoding-name"?>
encoding-name is a registered string corresponding to a formal character encoding. No distinction is made between uppercase and lowercase letters, but spaces are disallowed (use hyphens instead). Some examples are UTF-16, ISO-8859-1, and Shift_JIS.
A comprehensive list of encoding names is maintained by the Internet Assigned Numbers Authority (IANA), available on the Web at http://www.iana.org/assignments/character-sets. Many of these encoding names have aliases. The aliases for US-ASCII include ASCII, US-ASCII, and ISO646-US.
If you do not explicitly state otherwise, the parser will assume your encoding is UTF-8, unless it can determine the encoding another way. Sometimes a file will contain a byte order mark (BOM), a hidden piece of information in the file inserted by software that generated it. The XML processor can use a BOM to determine which character encoding to use, such as UTF-16. Every XML processor is required to support both UTF-8 and UTF-16. Other encodings are optional, so you enter that territory at your own risk.
9.1.2 Basic Concepts
The atomic unit of information in XML is the character. A character can be a visible symbol, such as the letters on this page, or a formatting code, like the ones that force space between words and separate lines in paragraphs. It may come from a Latin script or Greek, Thai, or Japanese. It may be a dingbat or punctuation mark. Most generally, a character is any symbol, with possibly different representations, whose meaning is understood by a community of people.
Every character belongs to a finite, ordered list called a character set (also called a coded character set). It is really not a set in the mathematical sense, but more of a sequence or table. Perhaps the best description, according to Dan Connolly in his article "Character Set Considered Harmful,"[1] is to think of it as "a function whose domain is a subset of the integers, and whose range is a set of characters." In other words, give the function a positive integer, or code position, and it will give you back a character from that place in its character repertoire.
[1] Read it on the Web at http://www.w3.org/MarkUp/html-spec/charset-harmful.html.
The earliest character set in common use is the American Standard Code for Information Interchange (US-ASCII), also known as ISO-646. It contains just 128 characters, listed in Figure 9-1.
Figure 9-1. The US-ASCII character set
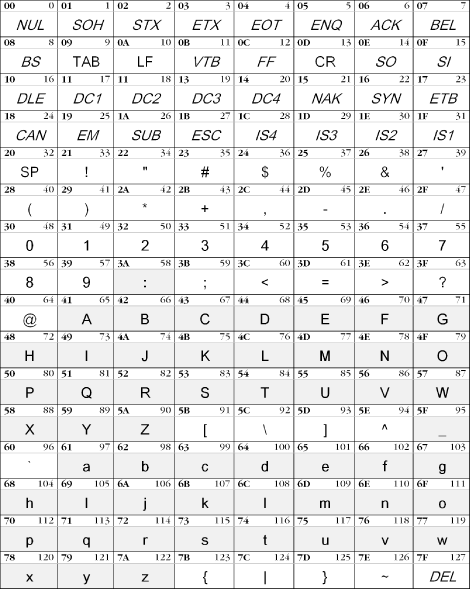
The first 32 codes are for control characters, invoking some action from the device, such as CR (carriage return: originally, it used to make the print head on a teletype return to its leftmost position) and BEL (bell: used to make a "ding" noise in the terminal). Today, many of the meanings behind these codes are somewhat ambiguous, since the devices have changed.
The rest of the characters produce some kind of visible shape called a glyph. These include uppercase and lowercase versions of the latin alphabet, plus an assortment of punctuation, digits, and other typographical conveniences.
If you think of US-ASCII as a function, its domain is the set of integers from 0 to 127. Plug in the hexadecimal numbers 48, 65, 6C, 6C, 6F, and 21, and you will get the string "Hello!" back. You might think that this is how all electronic documents are represented. In truth, however, it is usually more complex than that.
The character encoding for a document is the scheme by which characters are derived from the numerical values in its underlying form. An encoding scheme is a function that maps sequences of positive integers to a subset of a character set's repertoire. The input sequence may or may not have anything to do with the actual code position. Quite often, an algorithm must be applied to arrive at an actual code position.
The need for encodings becomes clear when you consider the vast gulf between character sets and the requirements of devices and protocols. Character sets range from tiny, 7-bit ASCII to huge, 32-bit Unicode. Devices and protocols may not be flexible enough to handle this wide variation.
Internet protocols historically have been defined in terms of 8-bit characters, or octets. ISO-646, which is based on the 7-bit ASCII character code, is designed for 8-bit systems, recommending that the eighth bit be set to zero. This encoding is just a simple way of making 7 bits seem like 8 bits.
Mail transport systems such as the simple mail transfer protocol (SMTP) have a restriction of 7 bits per character. Binary files such as compiled executables have to be encoded such that only the lower 7 bits per byte are used. 8-bit character sets also have to be encoded specially so they don't confuse the email transport agent. The Unix program uuencode, for example, turns any binary file into an ASCII string that looks like gibberish, but can be turned back into the original binary format later.
Large character sets such as Unicode are a sticky problem for legacy programs that were programmed for 8-bit character sets. Some encodings, such as UTF-8, repackage 16-bit and 32-bit characters as strings of octets so that they can be handled safely with older programs. These characters may not be rendered correctly, but at least they will pass through unmolested, and without crashing the software. For example, the text editor I like to use on my documents is Emacs. Emacs does not understand Unicode yet, but it can open and edit UTF-8 encoded files, and treat the unknown high characters in a way that I can see and work around.
9.1.3 Unicode and UCS
Compared to most other alphabets and scripts around the world, the English alphabet is extremely compact. While it may be suitable for English speakers, it lacks too many pieces for use with other languages. Most languages based on the Latin alphabet use ligatures and accents not found in ASCII. And Latin is just a minority among the many writing systems around the world.
Many attempts to accommodate other alphabets simply packed new characters into the unused 128 characters from the extra bit in 8-bit ASCII. Extensions specializing in everything from Greek to Icelandic appeared. Computer manufacturers also made up their own versions of 8-bit character sets. The result was a huge number of specialty character sets. Many of these have been standardized, such as ISO 8859, which includes character sets like the popular ISO Latin-1, Cyrillic, Arabic, Hebrew, and others.
One critical flaw in using specialty character sets is how to include characters from different sets in the same document. A hackish solution is to use code switching, a technique of replacing a byte with a sequence of bytes headed by a special control character. Thus, you could switch between character sets as necessary and still maintain the 8-bit character stream. Although it worked okay, it was not an ideal solution.
By the late 1980s, pressure was building to create a 16-bit character set that included all the writing systems into one superset. In 1991, the Unicode Consortium began work on the ambitious Unicode character set. With 16 bits per code position, it had space for 216 = 65,536 characters. The first 256 characters were patterned after ISO 8859-1 (ISO Latin-1), of which the first 128 are ASCII. The Unicode Consortium publishes the specification in a weighty tome with pictures of every glyph and extensive annotations.
Whereas Western languages tend to be alphabetic, composing words in sequences of characters, many Eastern languages represent entire words and ideas as single pictures, or ideographs. Since there are many more concepts than sounds in a language, the number of ideographs tends to run in the thousands. Three scripts, Chinese, Japanese, and Korean, have some overlapping glyphs. By throwing out the redundancies and combining them in one unified ideographic system (often called CJK for the initials of each language), their number was reduced to the point where it was practical to add them to Unicode.
This is often cited as one of the critical flaws of Unicode. Although it is fairly comprehensive in including the most used glyphs, the way it combines different systems together makes it very inconvenient for constructing a Unicode font, or to divide it into useful contiguous subsets. An ideograph found in both Chinese and Japanese should really be represented as two different characters, each keeping with the styling of the uniquely Chinese or Japanese characters. Furthermore, even though over 20,000 Han ideographs found a place in Unicode, this is still just a fraction of the total. There are still 60,000 that didn't make the cut.
Meanwhile, ISO had also been working to develop a multilingual character set. Called the Universal Multiple-Octet Coded Character Set (UCS), or ISO/IEC 10646-1, it was based on a 31-bit character, providing for over 2 billion characters. That is certainly enough to hold all the glyphs and symbols the human race has developed since a person first got the urge to scribble.
Quickly realizing the redundancy of their projects, the Unicode Consortium and ISO got together to figure out how to pool their work. UCS, being the larger of the two, simply made Unicode a subset. Today, both groups publish independent specifications, but they are totally compatible.
Some terminology helps to divide the vast space of UCS. A row is 256 characters. Wherever possible, an 8-bit character set is stuffed into a single row. For example, ISO Latin-1 inhabits the first row (positions 0x0000 to 0x00FF).[2] 256 rows (65,534 characters) is called a plane. Most of Unicode lives in the first plane (0x0000 to 0xFFFD), also called the Basic Multilingual Plane (BMP), though recent versions have moved beyond that set.
[2] The syntax 0xNNNN is used to represent a hexadecimal number. This is a base-16 system convenient for representing integers in systems based on powers of 2. It's more convenient than decimal because it can be easily divided by powers of 2 merely by shifting the decimal point. Since character encoding domains are frequently based on powers of 2, I will frequently use hexadecimal numbers to describe code positions.
UCS/Unicode assigns to each character in the BMP a code number, which is the string "U+" and four hexadecimal numbers, and a formal name. The number for "A" is U+0041 and its name is "Latin capital letter A." In ASCII, it would be 0x41, and the same in ISO Latin-1. Converting between these character sets is not difficult once you know the base number in UCS.
In addition to defining the character ordering, the Unicode Standard includes semantics related to issues such as sorting, string comparison, handling leftward and rightward scripts, and mixing together bidirectional scripts. UCS, in contrast, is not much more than a big table. The Unicode Consortium's web page (http://www.unicode.org/) has a wealth of resources including character tables, an FAQ, and descriptions of related technologies.
In the decade it has been around Unicode managed to attract enough favorable attention to become a necessary component in the Internet. Most operating systems ship with some support for Unicode, including extensive font sets and Unicode-cognizant web browsers and editing tools. Most programming languages in use today support Unicode. Java was designed from the start with Unicode support. Others, like Perl, added support later. And, most important for readers of this book, Unicode is the standard character set for XML.
9.1.4 Common Encodings
When choosing a character encoding for your document, you must consider several things. Do the constraints of your authoring environment require an 8-bit encoding or can you move up to 16-bits or higher? Do you really need the high characters of Unicode or can you live with the limitations of a smaller set like ISO Latin-1? Do you have the fonts to support your encoding's character repertoire? Does it support the byte order of your operating system? In this section, I will present a few of the more common character encodings available and attempt to answer these questions for each.
9.1.4.1 ISO 8859
ISO 8859 is a collection of 8-bit character encodings developed in the late 1980s. It includes ISO 8859-1 (Latin 1), the most common character encoding used on Unix systems today. Table 9-1 lists encodings in this specification.
|
Encoding |
Character set |
|
ISO 8859-2 |
Latin 2 (Central European characters) |
|
ISO 8859-4 |
Latin 4 (Baltic languages) |
|
ISO 8859-5 |
Cyrillic |
|
ISO 8859-6 |
Arabic |
|
ISO 8859-7 |
Greek |
|
ISO 8859-8 |
Hebrew |
|
ISO 8859-9 |
Latin 5 |
|
ISO 8859-14 |
Celtic |
ISO 8859-1 is a popular choice for documents because it is contains most European characters and, because it is a straight 8-bit mapping, it is compatible with a wide range of legacy software. If you suspect that your software is rejecting your document because of the default UTF-8 encoding, try setting the encoding to Latin 1. Then, if you need to use special symbols or high characters, you can insert them with character entity references. IANA-registered encoding names for ISO Latin-1 include ISO-8859-1 (the preferred MIME name), latin1, and l1.
A variant of Latin 1 is ISO-8859-1-Windows-3.1-Latin-1. This is the encoding used by U.S. and Western European versions of Microsoft Windows. It's almost the same as ISO 8859-1, but adds some useful punctuation in an area reserved for control characters in the ISO character sets. This encoding is also known as codepage 1252, but that's not a registered encoding name.
9.1.4.2 UCS-2 and UCS-4
A straight mapping of 16-bit Unicode is UCS-2. Every character occupies two bytes in the document. Likewise, 32-bit UCS is represented by the encoding UCS-4 and requires four bytes per character. Since Unicode and UCS are just big code tables assigning integers to characters, it is not difficult to understand these encoding schemes. You can convert a US-ASCII or Latin-1 file into UCS-2 simply by adding a 0x00 byte in front of every ASCII byte. Make that three 0x00 bytes to convert to UCS-4.
UCS-2 and UCS-4 have issues about byte ordering. On some systems, including Intel and VAX architectures, multibyte numbers are stored least significant byte first. The number 0x1234 would be stored as 0x34 followed by 0x12. This is called a little-endian architecture. In contrast, many Unix systems such as Solaris put the most significant byte first, which is called big-endian architecture.
UCS-2 and UCS-4 generally follow the big-endian convention. As a developer this is very important to know, because software written for a little-endian system will need to transpose adjacent bytes as it reads them into memory. As a user, you only need to know if your software is aware of UCS-2 or UCS-4, and you can trust that it will be handled correctly.
On some systems (namely, Win32), every Unicode file starts with the a special character known as the byte order mark (BOM), with the value U+FEFF. This is the zero-width, no-break space character, which is typically invisible and so will not change the appearance of your document. However, it helps to disambiguate whether the encoding is big-endian or little-endian. Transpose the bytes and you will get U+FFFE, which is not a valid Unicode character. This simple test gives a quick and automatic way to determine the endian-ness of the file.
UCS-2 and UCS-4 (and even UTF-16) have not been that widely deployed because, for Western alphabets, where most characters can be encoded within 8-bits, it effectively doubles the size of every file.
Another, and perhaps more worrisome, reason is that most software was written to handle text with one-byte characters. Running these programs on multibyte characters can have unpredictable, even dangerous, results. Most low-level routines in Unix are written in C and read 8-bit char datatypes. Certain bytes have special meaning, such as / in filenames and \0 as a stream terminator. When the program reads in a wide UCS character as a sequence of bytes, one of those bytes may map to a control character and then who knows what could happen.
A better alternative is an encoding that passes through 8-bit systems unmolested, yet retains the information of Unicode high characters. Both of these requirements are satisfied by UTF-8.
9.1.4.3 UTF-8
The UCS Transformation Format for 8-bits (UTF-8) was developed by the X/Open Joint Internationalization Group (XOJIG) in 1992 and later included in both the Unicode and UCS standards. It is particularly important to us because it is the default character encoding for XML documents. If you do not set the character encoding in the XML declaration explicitly, XML parsers are supposed to assume the document is encoded with UTF-8.[3]
[3] see RFC 2279
The main attraction of UTF-8 is that it allows Unicode characters to be included in documents without posing any danger to legacy text handling software. It was originally called UTF-FSS (UTF File System Safe), because it was designed with the sensitivity of Unix file system utilities in mind. Recall from the last section that wide 2-byte and 4-byte characters from UCS-2 and UCS-4 pose a risk because they may be decomposed into bytes that resemble reserved characters.
UTF-8 encoded text uses variable-length strings of bytes to represent each Unicode/UCS character. The first byte describes the type of byte sequence. If its value is between 0x0000 and 0x007F (0 through 127), then it will be interpreted as an ASCII character. Files and strings containing only 7-bit ASCII characters have the same encoding under US-ASCII and UTF-8.
If the first byte is 0x0080 or greater, a number of bytes following it will be used to determine the Unicode/UCS character. Table 9-2 shows the encoding algorithm for UCS. (The algorithm is the same for Unicode if you substitute 2-byte code positions, but only the first four rows in the table apply.) I use the binary representation of UTF-8 byte strings to show how certain bits are used to pad the bytes. The "xxx" portion is to be filled with bits of the character code number when converted to binary, and the rightmost bit is the least significant.
|
UCS character number |
UTF-8 byte string (in binary) |
|---|---|
|
U-00000000 - U-0000007F |
0xxxxxxx |
|
U-00000080 - U-000007FF |
110xxxxx 10xxxxxx |
|
U-00000800 - U-0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
|
U-00010000 - U-001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
|
U-00200000 - U-03FFFFFF |
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
|
U-04000000 - U-7FFFFFFF |
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
To encode the Unicode character 0+x03C0 (the Greek small letter pi), first compose it in binary: 0011 1100 0000. We select the second row from the table and pack the bits into "x" slots to get, in binary: 11001111 10000000. So the byte sequence in UTF-8 for this character is 0xCF 0x80.
You can see from this algorithm that the only time a byte sequence contains bytes with values between 0x00 and 0x7F is when they are one byte in length and represent the ASCII characters with those code positions. Other byte sequences range from 0xC0 to 0xFD for the first byte, and from 0x80 to 0xBF in following bytes. Keeping the first and following bytes in different ranges makes allows for error detection and easy resynchronization in the event of missing bytes during a transmission.
UTF-8 encoding is optimized for common Western characters. The lower a character's position in the Unicode/UCS pool, the shorter its encoded string of bytes. While UTF-8 characters can theoretically be as long as 6 bytes, those in the BMP portion of UCS will be at most 3 bytes long. Many European scripts will be just 2 bytes in length, and all ASCII characters only 1 byte. If there is any disadvantage to using UTF-8, it is that non-Western scripts are penalized with longer characters and increased document size.
9.1.4.4 UTF-16
UTF-16 is closely related to UTF-8, using a similar transformation algorithm to get from Unicode positions to numeric sequences. In this case, the sequences consist of 16-bit integers, not bytes. As with UCS-2 and UCS-4, byte is an issue you have to take into account. Some systems will use a BOM (byte order mark) and be able to detect byte order automatically. You can also explicitly select a byte order by using the more specific encoding name UTF-16LE (low-endian) or UTF-16BE (big-endian).
This encoding is one of the two required encodings all proper XML parsers must support. In reality, a few handle UTF-8 but not UTF-16, as 16-bit support for characters is not yet a universal feature in programming languages. Perl, for example, is moving that way but some legacy parsers still are not there.
This concludes my list of most common encodings used in XML documents. There are literally hundreds more, but they are either beyond the scope of this book or only of esoteric value. In case you are interested in researching this topic more, I will include some resources in Appendix A for you to follow.
9.1.5 Character References
Although Unicode puts a vast range of characters in one place for authors to use, many XML editing software packages do not offer a convenient way to access those characters. Recognizing that this difficulty could hurt its adoption, the designers of XML have included a convenient mechanism for placing Unicode characters in a document. Character entity references (also called character references) that incorporate the character number in their names stand in for those characters and do not need to be declared beforehand.
There are two forms, based on decimal and hexadecimal representations of the code position. The decimal character reference uses the form &#n;, where n is the decimal position of the character in Unicode. The hexadecimal variation has the form &#xNNNN;, where NNNN is a hexadecimal value for the position of the Unicode character. For example, the Greek small letter pi can be represented in XML as π or as π. In general, you may find the hexadecimal version to be more useful. Unicode specifications always give character code positions in hexadecimal.
The problem with numerical character references like these is that they are hard to remember. You have to keep looking them up in a table, cluttering your workspace, and generally going mad in the process. A better idea might be to use named entity references, such as those defined in ISO 8879.
This specification defines a few hundred useful entity declarations divided by knowledge area into a handful of files. For each character, there is a declaration for a general entity with an intuitive name. Here are a few of the defined characters:
|
Description |
Unicode character |
Entity name |
|---|---|---|
|
Latin small letter "a" with breve accent |
U+0103 |
abreve |
|
Planck constant over two pi |
U+210F |
planck |
|
Yen sign |
U+00A5 |
yen |
To use named entity references in your document, you need to obtain the entity declarations and either import them through the internal subset of your document, or import them into your DTD. I got a set when I downloaded DocBook-XML from the OASIS web site (thanks to DocBook maintainer Norm Walsh for creating an XML version of ISO 8879).







