8.5 Design of the Internal Domain Structure
Having designed the domain namespace, you can now concentrate on the internals of each domain. The design process itself is the same for each domain, but the order is mostly up to you. The first domain that you should design is the forest root domain. After that, iterate through the tree, designing subdomains within that first tree. Once the tree is finished, go on to the next tree and start at the root as before.
In a tree with three subdomains called Finance, Sales, and Marketing under the root, you could either design the entire tree below Finance, then the entire tree below Sales, and so on, or you could design the three tier-two domains first, then do all the subdomains immediately below these three, and so on.
When designing the internals of a domain, you need to consider both the hierarchical structure of Organizational Units and the users and groups that will sit in those Organizational Units. Let's look at each of those in turn.
|

8.5.1 Step 4Design the Hierarchy of Organizational Units
Earlier, when we discussed how to design domains, we spoke of how to minimize the number of domains you have. The idea is to represent most of your requirements for a hierarchical set of administrative permissions using Organizational Units instead.
Organizational Units are the best way to structure your data because of their flexibility. They can be renamed and easily moved around within and between domains and placed at any point in the hierarchy without affecting their contents. These two facts make them very easy for administrators to manage.
There are four main reasons to structure your data in an effective hierarchy:
- To represent your business model to ease management
-
Partitioning your data into an Organizational Unit structure that you will instantly recognize makes managing it much more comfortable than with every user and computer in one Organizational Unit.
- To delegate administration
-
Active Directory allows you to set up a hierarchical administration structure that wasn't possible with Windows NT. If you have three branches, and the main administrator wants to make one branch completely autonomous with its own administrator but wants to continue to maintain control over the other two branches, it's easy to set up. In a way, most of the limitations that you come up against when structuring Active Directory are limits that you set: political necessities, organizational models, and so on. Active Directory really won't care how you structure your data.
- To replace Windows NT resource domains
-
If you have a previous Windows NT installation with a master or multimaster domain model, you can replace your resource domains with Organizational Units in a single domain. This allows you to retain all the benefits of having resource domains (i.e., resource administration by local administrators who do not have account administration rights) without forcing you to have multiple domains that you don't really want or need.
- To apply policies to subsets of your users and computers
-
As policies can be applied to each individual Organizational Unit in the hierarchy, you can specify that different computers and users get different policies depending on where you place them in the tree. For example, let's say that you want to place an interactive touch-screen client in the lobby of your headquarters and allow people to interact with whatever applications you specify, such as company reports, maps of the building, and so on. Locking this down in Windows NT (so that the client could not compromise your network in any way) required time and may have required that the client be in a separate domain or even standalone. With Active Directory, if you lock down a certain Organizational Unit hierarchy using policies, you can guarantee that any computer and user accounts that you create or move to that part of the tree will be so severely restricted that hacking the network from the client won't be possible.
Let's take Leicester University as an example. The university is a large single site with mostly 10/100 MB links around campus and 2 MB links to some outlying areas a couple of miles away. The domain model was multimaster under Windows NT, but under Active Directory it moved to a single domain, so it is much simpler than before. Administration is centrally managed, which means that delegation of administration was of little concern during design. We had a departmental organizational model for the Organizational Unit structure holding our accounts. We created a flat structure with more than a hundred Organizational Units directly off the root and almost no lower Organizational Units at all. Each Organizational Unit corresponded to one department, and it held all the users from that department. We also had an Organizational Unit hierarchy for the computer accounts separate from the department Organizational Units. This was due to our requirement for group policies; we'll come back and discuss this in more detail in Chapter 10.
When creating Organizational Units, you need to ask:
How will the Organizational Units be used?
Who are the administrators and what sets of administrator permissions should they have?
What group policies will be applied?
The hierarchy should organize information in a manner pleasing to your administration and allowing you to delegate administration to various parts of the tree.
|
8.5.1.1 Recreating the business model
The easiest way to start a design is to consider the business model that you sat down with when starting these designs. You now need to recreate that structure in Active Directory using Organizational Units as the building blocks. Create a complete Organizational Unit structure that exactly mirrors your business model as represented by that domain. In other words, if the domain you are designing is the Finance domain, implement the finance organizational structure within the Finance domain. You don't create the entire organization's business model within each Organizational Unit; you create only the part of the model that would actually apply to that Organizational Unit. Draw this structure out on a piece of paper. Figure 8-3 shows the Organizational Unit structure of mycorp.com's domain. We've expanded only the Finance Organizational Unit here for the example.
Figure 8-3. The Mycorp domain's internal Organizational Unit structure
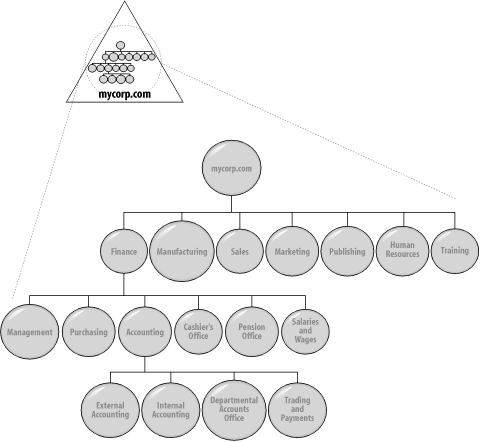
Once you have drawn an Organizational Unit structure as a template for your Active Directory hierarchy within the domain, you can begin to tailor it to your specific requirements. The easiest way to tailor the initial Organizational Unit design is to consider the hierarchy that you wish to create for your delegation of administration.
8.5.1.2 Delegating full administration
First, identify any areas of your hierarchy where you need to grant administrators autonomous access over their branch of the tree. These Organizational Units need to have at least two administrators who will look after that Organizational Unit. These administrators will look after the structure below that Organizational Unit, creating whatever Organizational Units, users, groups, shares, and so on that they desire. They will not, however, have administrator access to any other part of the tree.
|
You need to note three pieces of information about each of the Organizational Units that you identify:
Who will be the administrators?
Which branch of the tree will they administer?
Will the domain administrator have full or no administrative access to this branch?
The last is important. Let's take two examples. You may have a devolved administration scenario in which the domain administrator account is used only to grant administrator access to an Organizational Unit for two accounts. Once the two accounts have administrator access to the Organizational Unit, the administrator account's access is subsequently blocked by deliberate action from being inherited at that Organizational Unit. That effectively gives specific users administrative access over Organizational Units with the administrator account unable to be used to organize that data. In the second example, the domain administrator normally has access inherited throughout the tree, except at a number of key sensitive Organizational Units for political reasons. If this is the case, then once again, only the accounts that can manage the Organizational Unit have access to it.
|
8.5.1.3 Delegating other rights
Having noted the three pieces of information for all Organizational Units that need full administrative access, you next need to identify those Organizational Units that require some users to have a more restricted set of permissions. You may want to set up account administrators that have the ability to create and delete user accounts, as well as setting passwords and account details. You may want accounts that can create and publish printers. We're interested in rights only in general terms at the moment, so just note the following:
What the access rights are
Which branch of the tree the access rights will be applied to
Which users or groups (in general terms) will have these access rights
It is possible to set access rights of any sort down to the individual property level on a specific object if you require. That means you can allow a user named Richard Lang to change the password or telephone number of a user named Vicky Launders (and only that user) if you wish. Obviously the more minute the access, the more complex things can get, especially as permissions are inherited down a tree by default. To make things easier, Microsoft provides a simple Delegation Of Control wizard that allows you to set these access rights in a fairly easy manner. All this information on permissions to Active Directory is covered in much greater depth in Chapter 11. However, all we're concerned with at this stage in the design is delegation of control at the Organizational Unit level. From experience, we can tell you that assigning access rights at the Organizational Unit level is actually a lot simpler to manage than tracking permissions to individual objects and properties.
8.5.2 Step 5Design of Users and Groups
Before starting this section, we must make clear the distinction between groups and Organizational Units. Organizational Units are containers for objects that allow the objects to be represented in a hierarchical structure within a domain. Placing objects in such a hierarchy allows delegation of administration to those Organizational Units on a selective basis. We've seen all this already. Groups, on the other hand, have only users or computers as members and can be used in assigning permissions or rights to the members collectively. Let's say that we have 50 users contained in an Organizational Unit called FinanceOU, and the users are also members of a group called FinanceGrp. When we want to grant these 50 users read permissions to a share or restricted access to certain parts of a domain's hierarchy, we assign the permissions to the FinanceGrp. The fact that they are in the Organizational Unit makes no difference when you wish to assign permissions to objects contained inside the Organizational Unit. However, if we wish to delegate someone to have permission to manage those 50 accounts, we place the administrative delegation onto the Organizational Unit. Here we'll be talking about how to effectively design user accounts and the groups those users belong to.
8.5.2.1 Naming and placing users
When you are designing users, the only thing you really have to worry about is the username or user identifier that the client logs on with. Each username (the sAMAccountName property of a user object) must be unique throughout each domain. Arguably, if you have decided to delegate administration within your organization, you need to create a naming scheme to which each administrator will adhere so that unique usernames are generated for all users throughout your forest. That way, if you ever collapse the existing domains, you never need to rename the users if there are any conflicts. Naming groups is important, too.
Another name that you must give to all Active Directory users is known as the user principal name (the userPrincipalName property of the user object). This property looks like an RFC 822 email address, i.e., username@here.there.somewhere.com. In fact, this property is not the email address but is a unique identifier for the user in the entire forest. It has to be unique as it is stored in the GC. So while the users AlistairGLN in mycorp.com and AlistairGLN in finance.mycorp.com are perfectly valid, their UPNs (as the attribute is more commonly called) must be different. The normal way to create a UPN is simply to append an @ symbol and the domain onto the end of the username. This ensures uniqueness because the username was unique in the domain, and appending the domain forces a unique forest-wide UPN. This makes AlistairGLN@mycorp.com and AlistairGLN@finance.mycorp.com the UPNs for the two users in the example.
However, while it is conventional to construct the UPNs in this way, you can in fact make the UPN of a user anything you wish. We could, for example, append the domain@mycorp.com to all our users, eliminating the need to rely on domains at all. If we do that though, we need to make sure that our usernames (sAMAccountName) in each domain are unique not only domain-wide but also forest-wide. In the previous example, we can't have two users with the username AlistairGLN. For such a scheme to work, a central database or allocating authority needs to be set up to uniquely generate and allocate names. Leicester University has maintained a separate database from the early 1980s for this purpose, as have many other universities and companies. If this database or authority can generate unique usernames via a reliable algorithm, you can make use of a much simpler UPN.
|
UPNs are very important. Imagine a user sitting down at a client anywhere in a forest and being presented with the logon dialog box. Here he can type in his username (sAMAccountName), password, and domain and be authenticated to the forest. However, it is perfectly valid to authenticate with the UPN. If the user, presented with the same logon dialog box, instead types a UPN in the first field, the domain box becomes grayed out and inaccessible. In other words, a UPN and a password are all that is needed to authenticate to the tree. This makes sense, since the UPN is unique forest-wide, so apart from a password, nothing else should be needed. You now should be able to see that even with a very large and complex set of domains in a forest, you can use a simplified UPN form that does not contain a domain component and simply instruct users to log on with a UPN and a password. This means that users never need to care about what domain they are in.
Your choice of where you place the user accounts in each domain's hierarchy really is affected only by who is to administer the accounts and what GPOs will be applied on the Organizational Unit the account is in. Other than that, it makes little difference.
8.5.2.2 Naming and placing groups
Groups (especially universal groups that get stored in the GC) need unique names, too. A naming scheme for groups should be laid out in the design. Where you put groups is less important. In effect, groups can go almost anywhere in the hierarchy. The GPOs that determine your placement of users, for example, do not apply to groups. However, as the groups available to you will differ based on the mode or functional level of your forest, the only way you can do a proper design is to know roughly how long you intend to stay in mixed or interim mode before upgrading. If you have no previous Windows NT infrastructure and do not require any applications that run on NT, you can go native and Windows 2003 forest functional level immediately.
If you are planning to wait a while on mixed/interim mode before upgrading, for whatever reason, you need to do two sets of group designs: what the groups will be prior to the upgrade and what you will convert them to after the upgrade. Of course, the two designs may be the same.
|
8.5.2.3 Creating proper security group designs
If your organization is based on a single site (in the sense of being a "fast interconnected set of subnets," which is detailed in the next chapter), you can use universal security groups entirely. You don't have to, but for the purposes of design, it will make very little difference in the long run which you choose.
Assuming, however, that your organization has multiple domains, you should make use of Domain Local Security and Domain Global Security groups as well as Universal Security groups. If you wish to use Universal Security groups, do not put individual users into them as members. Remember that the Universal Security group and its members are held in the GC, so if you only add other groups as members you are unlikely to create as many group memberships as you would using individual users. That will limit the size of the GC and thus the impact of replication.
Based on the tables in Chapter 2, for large complex organizations with many different sets of permissions to many individual resources, we would still suggest using two sets of security groups. One set of security groups has permissions to local resources on a particular server, and the other set of security groups contains the users. You then can add one set of security groups to another to control access. In this manner, you are maintaining a fine-grained control over the access permissions for groups while not having to add users many times over to multiple groups.
In mixed mode, we would use Domain Local Security groups for access to local resources and add users to Domain Global Security groups or even Universal Distribution groups. In native mode we would do one of three things:
Continue as before, but now allow Universal Security groups to be members of Domain Local Security groups.
Convert the Domain Local Security groups to Universal Security groups with the same membership as before, because this is now allowed under native mode.
Convert the Domain Local Security groups and Domain Global Security groups to Universal Security groups, understanding the impact this will have on the GC and the potential for token explosion.
8.5.3 Step 6Global Catalog Design
The GC is part friend, part enemy. When it comes to aiding searches, it is very useful, but the GC can be a real problem if it starts replicating data everywhere. If you properly design the GC and understand its limitations, you are unlikely to have problems.
The GC design is dependent partially on the namespace and partially on the replication design. On the namespace side, designing the GC's contents is important to properly respond to searches, and on the replication side, designing the GC to interact using a reasonable amount of your bandwidth is important. We'll consider only half the picture in this chapter and do a draft design, coming back and revising the draft design in the next chapter. You have the choice of adding multiple GC servers or of not even hosting the GC on a site at all if you wish.
With Windows Server 2003 Active Directory, the dependencies on the GC are not as great as with Windows 2000. With Windows 2000 Active Directory, a GC had to be available for clients to log in. This was necessary because a user's universal groups needed to be enumerated to ensure their token was complete and accurate. Universal group membership is stored in the GC, and since universal group objects can reside anywhere in a forest, the only way for a DC to determine what universal groups a user is a member of is by querying the GC. In Windows Server 2003, you can enable universal group caching and effectively eliminate the need for a GC to be present during login. This means you no longer have to deploy GC servers just to ensure users can log in.
|
Each attribute in the Active Directory schema has a modifiable attribute that is used to indicate whether the attribute is to be contained in the GC. Most objects store at least one property in the GC, even if it is only their common name (cn) attribute. Examples of properties that are held in the GC include the password for all user objects (so that authentication is rapid) and the access permissions for each object (so that details on objects are not given out in responses if the requester does not have the relevant permissions).
|
If an attribute that you specifically do not want included is being placed in the GC, you can exclude it. You can do this either by unchecking the box in the Schema Manager MMC or programmatically via ADSI by setting isMemberOfPartialAttributeSet equal to FALSE. If you want an attribute included in the GC, the process is the reverse.
Obviously, the more data that you specify to be stored in the GC, the larger the GC will get. If the attribute that you include is for a class that contains only a handful of objects, the impact will be negligible. If you specify an attribute for a class of object that has tens of thousands of instances, you will impact the size of the GC.
|
This doesn't mean that you should not change anything. You just have to be aware of the potential impact. The time taken for searches is not immediately easy to measure. Every administrator knows that network bandwidth utilization is never the same twice and fluctuates every second with different numbers of users doing different tasks. This will affect your query times.
What you need to consider in this stage of namespace design is which attributes you wish to include and which default attributes you wish to exclude. This decision is affected by the fact that searches for properties that are contained in the GC are conducted forestwide, while searches for properties not contained in the GC are conducted only domainwide.
|
8.5.4 Including and Excluding Attributes
Microsoft has decided that a certain core set of attributes should go in the GC. If you wish to remove attributes from the GC, any searches on the attributes that you remove will be conducted only within the domain that generated the query.
You can add any attribute you want to the GC, but you have to be aware of the ramifications. When you add a new attribute to the GC, the value contained within that attribute for every object that uses that attribute must be replicated to every GC server. Depending on how you disperse your GC servers and the configuration of your network, this could be a major event. But if the attribute you are adding is not populated on many or any objects, the impact will be minimal.
|
Finally, a word of caution: you must be careful when excluding attributes from the default set. It's fine to exclude attributes that seem to make little difference to the overall picture, but restricting attributes that other applications may be depending on can be problematic.
8.5.5 Step 7Design the Application Partition Structure
Another significant namespace design issue to consider is the application partition structure for your forest. As described in Chapter 3, application partitions, new to Windows Server 2003 Active Directory, are user-defined partitions that have a customized replication scope. Application partitions can be especially helpful in branch office deployment scenarios where you have to deploy a lot of domain controllers. Often you'll have applications that want to store data in Active Directory, but that data is not pertinent or used frequently enough to warrant replicating to all domain controllers, especially in the branch offices. With application partitions, you can configure a new partition to hold application data that replicates data only among your hub domain controllers. The other great thing about application partitions is that you are not restricted by domain boundaries. If you want to replicate data globally and have domain controllers geographically located, you can create an application partition that replicates data between your geographically dispersed domain controllers regardless of which domain they reside in.
Application partitions have an impact on your namespace design because they are named very much like domains. For example, say you wanted to create an application partition in the mycorp.com forest; you could name it dc=apps,dc=mycorp,dc=com. In fact, application partitions have the same implications on the namespace and to DNS as do regular domains. So in the dc=apps,dc=mycorp,dc=com example, the apps.mycorp.com DNS domain will be populated with the standard SRV records, just like a domain.
You can also nest application partitions. For example, if you had a specific application you wanted to create a partition for, you could host it directly off the apps partition we just mentioned. We could name it dc=MyApp,dc=apps,dc=mycorp,dc=com.







