Hack 57 Create a Traditional Index Section from Keywords
![]()
![]()
Add a search feature to your print edition.
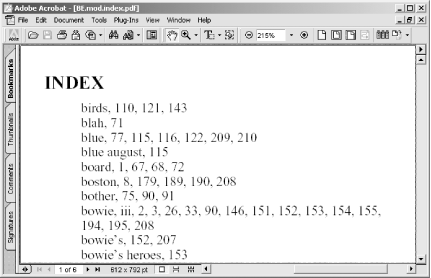
Creating a good document Index section is a difficult job performed by professionals. However, an automatically generated index still can be very helpful. Use automatic keywords [Hack #19] or select your own keywords. This hack will locate their pages, build a reference, and then create PDF pages that you can append to your document, as shown in Figure 5-5. It even uses your PDF's page labels (also known as logical page numbering) to ensure trouble-free lookup.
Figure 5-5. Turning document keywords into a PDF Index section
5.8.1 Tool Up
Download and install pdftotext [Hack #19], our kw_index [Hack #19], and pdftk [Hack #79] . You must also have enscript (Windows users visit http://gnuwin32.sf.net/packages/enscript.htm) and ps2pdf. ps2pdf comes with Ghostscript [Hack #39] . Our kw_index package includes the kw_catcher and page_refs programs (and source code) that we use in the following sections.
5.8.2 The Procedure
First, set your PDF's logical page numbering [Hack #62] to match your document's page numbering. Then, use pdftk to dump this information into a text file, like so:
pdftk mydoc.pdf dump_data output mydoc.data.txt
Next, convert your PDF to plain text with pdftotext:
pdftotext mydoc.pdf mydoc.txtCreate a keyword list [Hack #19] from mydoc.txt using kw_catcher, like so:
kw_catcher 12 keywords_only mydoc.txt > mydoc.kw.txt
Edit mydoc.kw.txt to remove duds and add missing keywords. At present, only one keyword is allowed per line. If two or more keywords are adjacent in mydoc.txt, our page_refs program will assemble them into phrases.
Now pull all these together to create a text index using page_refs:
page_refs mydoc.txt mydoc.kw.txt mydoc.data.txt > mydoc.index.txt
Finally, create a PDF from mydoc.index.txt using enscript and ps2pdf:
enscript --columns 2 --font 'Times-Roman@10' \ --header '|INDEX' --header-font 'Times-Bold@14' \ --margins 54:54:36:54 --word-wrap --output - mydoc.index.txt \ | ps2pdf - mydoc.index.pdf
5.8.3 The Code
Of course, the thing to do is to wrap this procedure into a tidy script. Copy the following Bourne shell script into a file named make_index.sh, and make it executable by applying chmod 700. Windows users can get a Bourne shell by installing MSYS [Hack #97] .
#!/bin/sh
# make_index.sh, version 1.0
# usage: make_index.sh <PDF filename> <page window>
# requires: pdftk, kw_catcher, page_refs,
# pdftotext, enscript, ps2pdf
#
# by Ross Presser, Imtek.com
# adapted by Sid Steward
# http://www.pdfhacks.com/kw_index/
fname=`basename $1 .pdf`
pdftk ${fname}.pdf dump_data output ${fname}.data.txt && \
pdftotext ${fname}.pdf ${fname}.txt && \
kw_catcher $2 keywords_only ${fname}.txt \
| page_refs ${fname}.txt - ${fname}.data.txt \
| enscript --columns 2 --font 'Times-Roman@10' \
--header '|INDEX' --header-font 'Times-Bold@14' \
--margins 54:54:36:54 --word-wrap --output - \
| ps2pdf - ${fname}.index.pdf5.8.4 Running the Hack
Pass the name of your PDF document and the kw_catcher window size to make_index.sh like so:
make_index.sh mydoc.pdf 12The script will create a document index named mydoc.index.pdf. Review this index and append it to your PDF document [Hack #51] if you desire. The script also creates two intermediate files: mydoc.data.txt and mydoc.txt. If the PDF index is faulty, review these intermediate files for problems. Delete them when you are satisfied with the PDF index.
The second argument to make_index.sh controls the keyword detection sensitivity. Smaller numbers yield fewer keywords at the risk of omitting some keywords; larger numbers admit more keywords and also more noise. [Hack #19] discusses this parameter and the kw_catcher program that uses it.






