Early Database Models
In the days before the relational database model, two data models were commonly used to maintain and manipulate datathe hierarchical database model and the network database model.
Note
Although use of these models is rapidly waning, I've provided a brief overview of each for historical purposes. In an overall sense, I believe it is useful for you to know what preceded the relational model so that you have a basic understanding of what led to its creation and evolution.
In the following overview I briefly describe how the data in each model is structured and accessed, how the relationship between a pair of tables is represented, and one or two of the advantages or disadvantages of each model.
Some of the terms you'll encounter in this section are explained in more detail in Chapter 3, "Terminology."
The Hierarchical Database Model
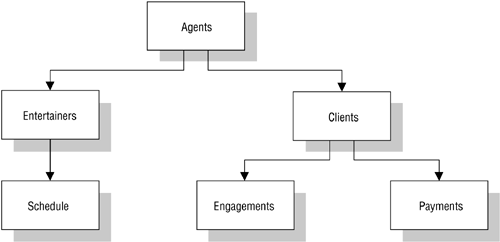
Data in this type of database is structured hierarchically and is typically diagrammed as an inverted tree. A single table in the database acts as the "root" of the inverted tree and other tables act as the branches flowing from the root. Figure 1.1 shows a diagram of a typical hierarchical database structure.
Figure 1.1. Diagram of a typical hierarchical database.
Agents Database
In the example shown in Figure 1.1, an agent books several entertainers, and each entertainer has his own schedule. An agent also maintains a number of clients whose entertainment needs are met by the agent. A client books engagements through the agent and makes payments to the agent for his services.
A relationship in a hierarchical database is represented by the term parent/child. In this type of relationship, a parent table can be associated with one or more child tables, but a single child table can be associated with only one parent table. These tables are explicitly linked via a pointer or by the physical arrangement of the records within the tables. A user accesses data within this model by starting at the root table and working down through the tree to the target data. This access method requires the user to be very familiar with the structure of the database.
One advantage to using a hierarchical database is that a user can retrieve data very quickly because there are explicit links between the table structures. Another advantage is that referential integrity is built in and automatically enforced. This ensures that a record in a child table must be linked to an existing record in a parent table, and that a record deleted in the parent table will cause all associated records in the child table to be deleted as well.
A problem occurs in a hierarchical database when a user needs to store a record in a child table that is currently unrelated to any record in a parent table. Consider an example using the Agents database shown in Figure 1.1. A user cannot enter a new entertainer in the ENTERTAINERS table until the entertainer is assigned to an agent in the AGENTS table. Recall that a record in a child table (in this case, ENTERTAINERS) must be related to a record in the parent table (AGENTS). Yet in real life, entertainers commonly sign up with the agency well before they are assigned to specific agents. This scenario is difficult to model in a hierarchical database. The rules can be bent without breaking them if a dummy agent record is inserted in the AGENTS table; however, this option is not really optimal.
This type of database cannot support complex relationships, and there is often a problem with redundant data. For example, there is a many-to-many relationship between clients and entertainers; an entertainer will perform for many clients, and a client will hire many entertainers. You can't directly model this type of relationship in a hierarchical database, so you'll have to introduce redundant data into both the SCHEDULE and ENGAGEMENTS tables.
The SCHEDULE table will now have client data (such as client name, address, and phone number) to show for whom and where each entertainer is performing. This particular data is redundant because it is currently stored in the CLIENTS table.
The ENGAGEMENTS table will now contain data on entertainers (such as entertainer name, phone number, and type of entertainer) to indicate which entertainers are performing for a given client. This data is redundant as well because it is currently stored in the ENTERTAINERS table.
The problem with this redundancy is that it opens up the possibility of allowing a user to enter a single piece of data inconsistently. This, in turn, can result in producing inaccurate information.
A user can solve this problem in a roundabout manner by creating one hierarchical database specifically for entertainers and another specifically for agents. The new Entertainers database will contain only the ENTERTAINERS table, and the revised Agents database will contain the AGENTS, CLIENTS, PAYMENTS, and ENGAGEMENTS tables. The SCHEDULE table is no longer needed in the Entertainers database because you can define a logical child relationship between the ENGAGEMENTS table in the Agents database and the ENTERTAINERS table in the Entertainers database. With this relationship in place, you can retrieve a variety of information, such as a list of booked entertainers for a given client or a performance schedule for a given entertainer. Figure 1.2 shows a diagram of the new model.
Figure 1.2. Using two hierarchical databases to resolve a many-to-many relationship.
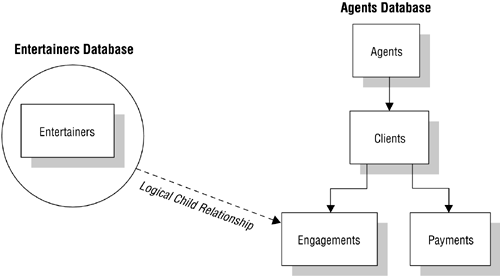
As you see, a person designing a hierarchical database must be able to recognize the need to use this technique for a many-to-many relationship. Here the need is relatively obvious, but many relationships are more obscure and may not be discovered until very late in the design process or, more disturbingly, well after the database has been put into operation.
The hierarchical database lent itself well to the tape storage systems used by mainframes in the 1970s and was very popular in companies that used those systems. But, despite the fact that the hierarchical database provided fast and direct access to data and was useful in a number of circumstances, it was clear that a new database model was needed to address the growing problems of data redundancy and complex relationships among data.
The Network Database Model
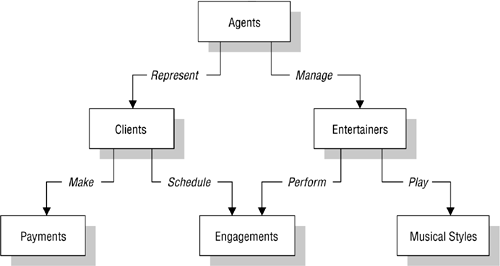
The network database was, for the most part, developed as an attempt to address some of the problems of the hierarchical database. The structure of a network database is represented in terms of nodes and set structures. Figure 1.3 shows a diagram of a typical network database.
Figure 1.3. Diagram of a typical network database.
Agents Database
In the example shown in Figure 1.3, an agent represents a number of clients and manages a number of entertainers. Each client schedules any number of engagements and makes payments to the agent for his or her services. Each entertainer performs a number of engagements and may play a variety of musical styles.
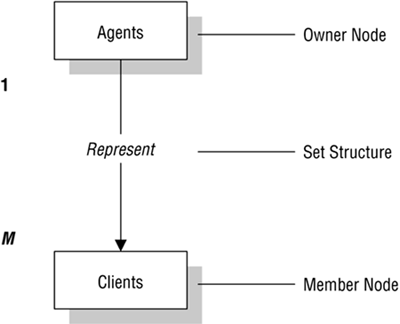
A node represents a collection of records, and a set structure establishes and represents a relationship in a network database. It is a transparent construction that relates a pair of nodes together by using one node as an owner and the other node as a member. (This is a valuable improvement on the parent/child relationship.) A set structure supports a one-to-many relationship, which means that a record in the owner node can be related to one or more records in the member node, but a single record in the member node is related to only one record in the owner node. Additionally, a record in the member node cannot exist without being related to an existing record in the owner node. For example, a client must be assigned to an agent, but an agent with no clients can still be listed in the database. Figure 1.4 shows a diagram of a basic set structure.
Figure 1.4. A basic set structure.
One or more sets (connections) can be defined between a specific pair of nodes, and a single node can also be involved in other sets with other nodes in the database. In Figure 1.3, for instance, the CLIENTS node is related to the PAYMENTS node via the Make set structure. It is also related to the ENGAGEMENTS node via the Schedule set structure. Along with being related to the CLIENTS node, the ENGAGEMENTS node is related to the ENTERTAINERS node via the Perform set structure.
A user can access data within a network database by working through the appropriate set structures. Unlike the hierarchical database, where access must begin from a root table, a user can access data from within the network database, starting from any node and working backward or forward through related sets. Consider the Agents database in Figure 1.3 once again. Say a user wants to find the agent who booked a specific engagement. She begins by locating the appropriate engagement record in the ENGAGEMENTS node, and then determines which client "owns" that engagement record via the Schedule set structure. Finally, she identifies the agent that "owns" the client record via the Represent set structure. The user can answer a wide variety of questions as long as she navigates properly through the appropriate set structures.
One advantage the network database provides is fast data access. It also allows users to create queries that are more complex than those they created using a hierarchical database. A network database's main disadvantage is that a user has to be very familiar with the structure of the database in order to work through the set structures. Consider the Agents database in Figure 1.3 once again. It is incumbent on the user to be familiar with the appropriate set structures if she is to determine whether a particular engagement has been paid. Another disadvantage is that it is not easy to change the database structure without affecting the application programs that interact with it. Recall that a relationship is explicitly defined as a set structure in a network database. You cannot change a set structure without affecting the application programs that use this structure to navigate through the data. If you change a set structure, you must also modify all references made from within the application program to that structure.
Although the network database was clearly a step up from the hierarchical database, a few people in the database community believed that there must be a better way to manage and maintain large amounts of data. As each data model emerged, users found that they could ask more complex questions, thereby increasing the demands made upon the database. And so, we come to the relational database model.
| Top |







