The Relational Database Model
The relational database was first conceived in 1969 and has arguably become the most widely used database model in database management today. The father of the relational model, Dr. Edgar F. Codd, was an IBM research scientist in the late 1960s and was at that time looking into new ways to handle large amounts of data. His dissatisfaction with the database models and database products of the time led him to begin thinking of ways to apply the disciplines and structures of mathematics to solve the myriad of problems he had been encountering. Being a mathematician by profession, he strongly believed that he could apply specific branches of mathematics to solve problems, such as data redundancy, weak data integrity, and a database structure's overdependence on its physical implementation.
Dr. Codd formally presented his new relational model in a landmark work entitled "A Relational Model of Data for Large Shared Databanks"[1] in June of 1970. He based his new model on two branches of mathematicsset theory and first-order predicate logic. Indeed, the name of the model itself is derived from the term relation, which is part of set theory. (A widely held misconception is that the relational model derives its name from the fact that tables within a relational database can be related to one another.)
[1] Edgar F. Codd, "A Relational Model of Data for Large Shared Databanks," Communications of the ACM, June 1970, 37787.
A relational database stores data in relations, which the user perceives as tables. Each relation is composed of tuples, or records, and attributes, or fields. (I'll use the terms tables, records, and fields throughout the remainder of the book.) The physical order of the records or fields in a table is completely immaterial, and each record in the table is identified by a field that contains a unique value. These are the two characteristics of a relational database that allow the data to exist independently of the way it is physically stored in the computer. As such, a user isn't required to know the physical location of a record in order to retrieve its data. This is unlike the hierarchical and network database models, in which knowing the layout of the structures is crucial to retrieving data.
The relational model categorizes relationships as one-to-one, one-to-many, and many-to-many. (These relationships are covered in detail in Chapter 10.) A relationship between a pair of tables is established implicitly through matching values of a shared field. In Figure 1.5, for example, the CLIENTS and AGENTS tables are related via an AGENT ID field; a specific client is associated with an agent through a matching AGENT ID. Likewise, the ENTERTAINERS and ENGAGEMENTS tables are related via an ENTERTAINER ID; a record in the ENTERTAINERS table can be associated with a record in the ENGAGEMENTS through matching ENTERTAINER IDs.
Figure 1.5. Examples of related tables in a relational database.
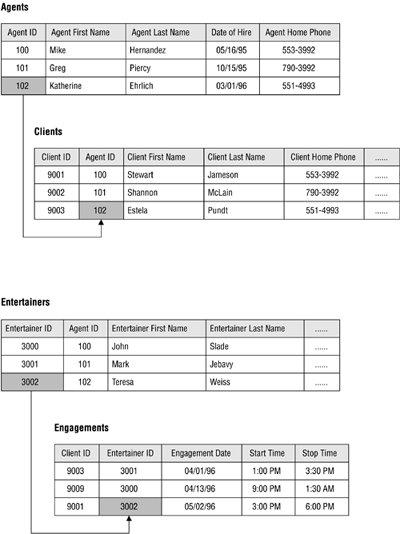
As long as a user is familiar with the relationships among the tables in the database, he can access data in an almost unlimited number of ways. He can access data from tables that are directly related and from tables that are indirectly related. Consider the Agents database in Figure 1.5. Although the CLIENTS table is indirectly related to the ENGAGEMENTS table, the user can produce a list of clients and the entertainers who have performed for them. (Of course, it really depends on how the tables are actually structured, but I digress. This example serves our purpose for now.) He can do this easily because CLIENTS is directly related to ENGAGEMENTS and ENGAGEMENTS is directly related to ENTERTAINERS.
Retrieving Data
You retrieve data in a relational database by using Structured Query Language (SQL). SQL is the standard language used to create, modify, maintain, and query relational databases. Figure 1.6 shows a sample SQL query statement you can use to produce a list of all clients in the city of El Paso.
Figure 1.6 A sample SQL query statement.
SELECT ClientLastName, ClientFirstName, ClientPhoneNumber FROM Clients WHERE City = "El Paso" ORDER BY ClientLastName, ClientFirstName;
The three components of a basic SQL query are the SELECT…FROM statement, the WHERE clause, and the ORDER BY clause. You use the SELECT clause to indicate the fields you want to use in the query and the FROM clause to indicate the table(s) to which the fields belong. You can filter the records the query returns by imposing criteria against one or more fields with the WHERE clause, and then sort the results in ascending or descending order with the ORDER BY clause.
Most of today's major relational database software programs incorporate various forms of SQL implementations, ranging from windows in which users can manually enter "raw" SQL statements to graphical tools that allow users to build queries using various graphic elements. For example, a user working with R:BASE Technologies's R:BASE can opt to build and execute SQL query statements directly from a command prompt, while someone using Microsoft Access may find it easier to build queries using Access's graphical query builder. Regardless of how the queries are built, the user can save them for future use.
It's not always necessary for you to know SQL in order to work with a database. If your database software provides a graphical query builder or you're using a custom-built application to work with the data in your database, you'll never need to write a single SQL statement. It's a good idea, however, for you to gain a basic understanding of SQL. It will help those of you using query-building tools to understand and troubleshoot the queries you create with these tools, and it will definitely be to your advantage should you need to work high-end database software programs, such as Oracle and Microsoft SQL Server.
Note
Although a detailed discussion of SQL is beyond the scope of this book, you should understand that SQL is a language directly related to the relational database model. If you have a desire or need to study SQL, you could start by reading my second book, SQL Queries for Mere Mortals, and then move on to any of the other SQL books that are on my recommended reading list in Appendix A.
Advantages of a Relational Database
The relational database provides a number of advantages over previous models, such as the following:
Built-in multilevel integrity: Data integrity is built into the model at the field level to ensure the accuracy of the data; at the table level to ensure that records are not duplicated and to detect missing primary key values; at the relationship level to ensure that the relationship between a pair of tables is valid; and at the business level to ensure that the data is accurate in terms of the business itself. (Integrity is discussed in detail as the design process unfolds.)
Logical and physical data independence from database applications: Neither changes a user makes to the logical design of the database, nor changes a database software vendor makes to the physical implementation of the database, will adversely affect the applications built upon it.
Guaranteed data consistency and accuracy: Data is consistent and accurate due to the various levels of integrity you can impose within the database. (This will become quite clear as you work through the design process.)
Easy data retrieval: At the user's command, data can be retrieved either from a particular table or from any number of related tables within the database. This enables a user to view information in an almost unlimited number of ways.
These and other advantages have proved beneficial to the business community and to all those who need to collect and manage data. Indeed, the relational database has become the database of choice in many circumstances.
Until recently, one perceived disadvantage of the relational database was that software programs based on it ran very slowly. This was not a fault of the relational model itself, but of the ancillary technology available at the time of the model's introduction. Processing speed, memory, and storage were simply insufficient to provide database software vendors with a platform on which to build a full implementation of the relational database, so the initial relational database software programs fell woefully short of their full potential. Since the early 1990s, however, advances in both hardware technology and software engineering have made processing speed an insignificant issue and have allowed vendors to make significant gains in their efforts to support the model more fully.
You'll learn more about the relational database model as you work through the design process presented in this book. Some of the topics you'll encounter include creating tables, establishing data integrity, working with relationships, and establishing business rules.
| Top |







