Value-Related Terms
Data
The values you store in the database are data. Data is static in the sense that it remains in the same state until you modify it by some manual or automated process. Figure 3.1 shows some sample data.
Figure 3.1 An example of basic data.
George Edleman 92883 05/16/96 95.00
On the surface, this data is meaningless. For example, there is no easy way for you to determine what "92883" represents. Is it a zip code? Is it a part number? Even if you know it represents a customer identification number, is it one that is associated with George Edleman? There's just no way of knowing until you process the data.
Information
Information is data that you process in a manner that makes it meaningful and useful to you when you work with it or view it. It is dynamic in the sense that it constantly changes relative to the data stored in the database, and also in the sense that it can be processed and presented in an unlimited number of ways. You can show information as the result of a SELECT statement, display it in a form on your computer screen, or print it on paper as a report. The point to remember is that you must process your data in some manner so that you can turn it into meaningful information.
Figure 3.2 demonstrates how the data from the previous example can be processed and transformed into information. It has been manipulated in such a wayin this case as part of a patient invoice reportthat it is now meaningful to anyone who views it.
Figure 3.2. An example of data transformed into information.

It is very important for you to understand the difference between data and information. A database is designed to provide meaningful information to someone within a business or organization. This information can be provided only if the appropriate data exists in the database and the database is structured in such a way as to support that information. If you ever forget the difference between data and information, just remember this little axiom:
Data is what you store; information is what you retrieve.
When you fully understand this single, simple concept, the logic behind the database-design process will become crystal clear.
Note
Unfortunately, data and information are two terms that are still frequently used interchangeably (and, therefore, erroneously) throughout the database industry. You'll encounter this error in numerous trade magazines and commercial database books, and you'll even see the terms misused by authors who should know better.
Null
A null represents a missing or unknown value. You must understand from the outset that a null does not represent a zero or a text string of one or more blank spaces. The reasons are quite simple.
A zero can have a very wide variety of meanings. It can represent the state of an account balance, the current number of available first-class ticket upgrades, or the current stock level of a particular product.
Although a text string of one or more blank spaces is guaranteed to be meaningless to most of us, it is definitely meaningful to a query language like SQL. A blank space is a valid character as far as SQL is concerned, and a character string composed of three blank spaces (' ') is just as legitimate as a character string composed of three letters ('abc'). In Figure 3.3, a blank represents the fact that Washington, D.C., is not located in any county whatsoever.
Figure 3.3. An example of a table containing null values.
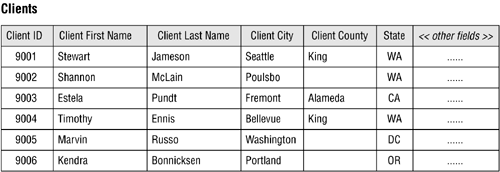
A zero-length stringtwo consecutive single quotes with no space in between ('')is also an acceptable value to languages such as SQL, and can be meaningful under certain circumstances. In an EMPLOYEES table, for example, a zero-length string value in a field called MIDDLEINITIAL may represent the fact that a particular employee does not have a middle initial in his name.
Note
Due to space restrictions, I cannot always show all of the fields for a given sample table. I will, however, show the fields that are most relevant to the discussion at hand and use <<other fields>> to represent fields that are unessential to the example. You'll see this convention in many examples throughout the remainder of the book.
The Value of Nulls
A null is quite useful when you use it for its stated purpose, and the CLIENTS table in Figure 3.3 clearly illustrates this. Each null in the CLIENT COUNTY field represents a missing or unknown county name for the record in which it appears. In order for you to use nulls correctly, you must first understand why they occur at all.
Missing values are commonly the result of human error. For example, consider the record for Shannon McLain. If you're entering the data for Ms. McLain and you fail to ask her for the name of the county she lives in, that data is considered missing and is represented in the record as a null. Once you recognize the error, however, you can correct it by calling Ms. McLain and asking her for the county name.
Unknown values appear in a table for a variety of reasons. One reason may be that a specific value you need for a field is as yet undefined. For instance, you could have a CATEGORIES table in a School Scheduling database that doesn't currently contain a category for a new set of classes that you want to offer beginning in the fall session. Another reason a table might contain unknown values is that they are truly unknown. Refer to the CLIENTS table in Figure 3.3 once again and consider the record for Marvin Russo. Say that you're entering the data for Mr. Russo and you ask him for the name of the county he lives in. If he doesn't know the county name and you don't happen to know the county that includes the city in which he lives, then the value for the county field in his record is truly unknown and is represented within the record as a null. Obviously, you can correct the problem once either of you determines the correct county name.
A field value may also be null if none of its values applies to a particular record. Assume for a moment that you're working with an EMPLOYEES table that contains a SALARY field and a HOURLYRATE field. The value for one of these two columns is always going to be null because an employee cannot be paid both a fixed salary and an hourly rate.
It's important to note that there is a very slim difference between "does not apply" and "is not applicable." In the previous example, the value of one of the two fields literally does not apply. Now assume you're working with a PATIENTS table that contains a field called HAIRCOLOR and you're currently updating a record for an existing male patient. If that patient recently became bald, then the value for that field is definitely "not applicable." Although you could just use a null to represent a value that is not applicable, I always recommend that you use a true value such as "N/A" or "Not Applicable." This will make the information clearer in the long run.
As you can see, whether you allow nulls in a table depends on the manner in which you're using the data. Now that we've shown you the positive side of using nulls, let's take a look at the negative implication of using them.
The Problem with Nulls
The major disadvantage of nulls is that they have an adverse effect on mathematical operations. An operation involving a null evaluates to null. This is logically reasonableif a number is unknown then the result of the operation is necessarily unknown. Note how a null alters the outcome of the operation in the following example:
(25 x 3) + 4 = 79
(Null x 3) + 4 = Null
(25 x Null) + 4 = Null
(25 x 3) + Null = Null
The PRODUCTS table in Figure 3.4 helps to illustrate the effects nulls have on mathematical expressions that incorporate fields from a table. In this case, the value for the TOTAL VALUE field is derived from the mathematical expression "[SRP] x [QTY ON HAND]." As you inspect the records in this table, note that the value for the TOTAL VALUE field is missing where the QTY ON HAND value is null, resulting in a null value for the TOTAL VALUE field as well. This leads to a serious undetected error that occurs when all the values in the TOTAL VALUE field are added together: an inaccurate total. This error is "undetected" because an RDBMS program will not inherently alert you of the error. The only way to avoid this problem is to ensure that the values for the QTY ON HAND field cannot be null.
Figure 3.4. The nulls in this table will have an effect on mathematical operations involving the table's fields.
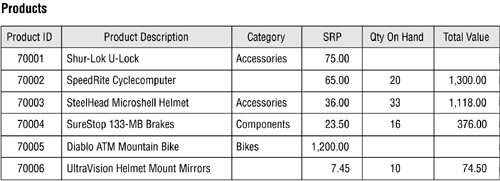
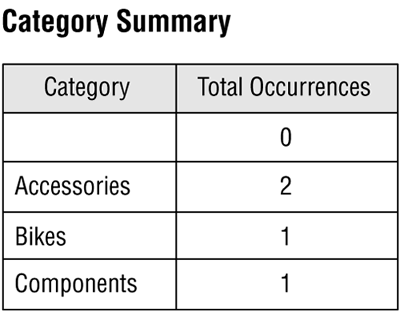
Figure 3.5 helps to illustrate the effect nulls have on aggregate functions that incorporate the values of a given field in a table. The result of an aggregate function, such as COUNT(<fieldname>), will be null if it is based on a field that contains null values. The table in Figure 3.5 shows the results of a summary query that counts the total number of occurrences of each category in the PRODUCTS table shown in Figure 3.4. The value of the TOTAL OCCURRENCES field is the result of the function expression COUNT([CATEGORY]). Notice that the summary query shows "0" occurrences of an unspecified category, implying that each product has been assigned a category. This information is clearly inaccurate because there are two products in the PRODUCTS table that have not been assigned a category.
Figure 3.5. Nulls affect the results of an aggregate function.
The issues of missing values, unknown values, and whether a value will be used in a mathematical expression or aggregate function are all taken into consideration in the database-design process, and we will revisit and discuss these issues further in later chapters.
| Top |








