Anatomy of a View
There are three types of views (data, aggregate, validation) that you can define as you design the logical structure of the database and two types of views (materialized and partitioned) that you can define as you implement your database within an RDBMS. The ability to define the latter two types of views and the manner in which you do so are highly dependent upon your RDBMS, so they are beyond the scope of this book. We will, therefore, focus our attention on the first three types of views.
Data View
You use this type of view to examine and manipulate data from a single base table or multiple base tables.
Single-Table Data View
Although you could use all of the fields from the base table to build this type of view, you'll usually just use selected fields. (Building a view using all of the base table's fields would simply produce a virtual copy of the base table.) For example, say you want to make a list of employee names and phone numbers available to everyone in the organization. You can construct an EMPLOYEE PHONE LIST view based on the EMPLOYEES table using just the EMPLOYEE ID, EMPFIRST NAME, EMPLAST NAME, and EMPPHONE NUMBER fields. Figure 12.1 shows a diagram of this particular view. (Note the new symbol used to indicate a view.)
Figure 12.1. The EMPLOYEE PHONE LIST view.
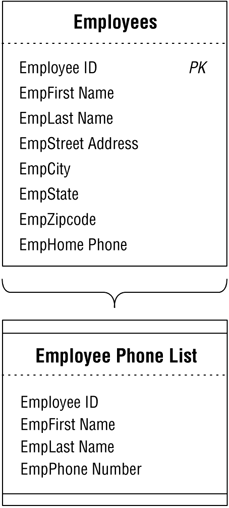
Your RDBMS will rebuild and repopulate the EMPLOYEE PHONE LIST view each time you access it, and the view will reflect the latest changes you've made to the data in the EMPLOYEES table. Figure 12.2 shows how an RDBMS will typically display the data within a view. Note that the view's appearance is quite similar to that of a table; this is yet another reason why a view is known as a "virtual table."
Figure 12.2. Information from the EMPLOYEE PHONE LIST view.
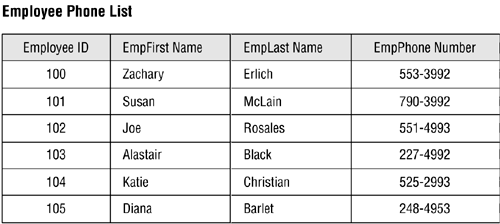
You can modify the data within a single-table data view at any time, and the modifications you make will flow through the view and into the base table. Keep in mind, however, that field specifications and business rules will determine what types of modifications you can make to the data. For example, you won't be able to delete a last name in the EMPLOYEE PHONE LIST view if the Null Support element of the field specification for the EMPLAST NAME field is set to "No Nulls."
Note
View implementation varies to some degree among most RDBMS software. Make sure you examine your RDBMS's documentation to determine how fully the RDBMS supports views and what types of constraints it imposes (if any) on modifying the data in a view.
Multitable Data View
As I mentioned at the beginning of this section, you can define a data view using two or more tables. The only requirement is that the tables you use to create the view must bear a relationship to each other; this helps ensure that the information the view presents is both valid and meaningful. For example, assume you're designing a database for a local community college and that the tables in Figure 12.3 are part of the database. You've just decided that you need to create a view called CLASS ROSTER that shows the name of each class and the names of the students who are currently registered to attend it. This will be an easy task for you to perform because you can use these three tables as the basis of the view; they contain the fields you need to define the view, and they bear a relationship to one another.
Figure 12.3. Base tables for the CLASS ROSTER view.
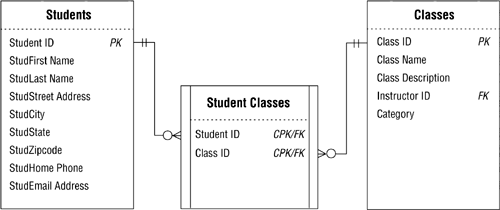
Now you define the CLASS ROSTER view by using the CLASS NAME field from the CLASSES table and the STUDFIRST NAME and STUDLAST NAME fields from the STUDENTS table. The appropriate student names will appear for each class because CLASSES and STUDENTS are related (and therefore connected) through the STUDENT CLASSES linking table. Figure 12.4 shows the diagram for the CLASS ROSTER view. Note that no changes have been made to any of the base tables.
Figure 12.4. The diagram for the CLASS ROSTER view.
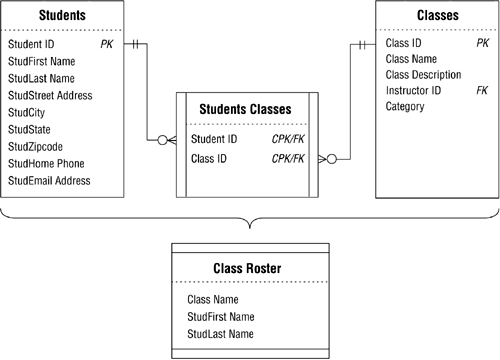
Every time you access the CLASS ROSTER view, the RDBMS will rebuild and repopulate it using the most current data from the view's base tables. Figure 12.5 shows a sample of the view's data.
Figure 12.5. A partial sample of data from the CLASS ROSTER view.
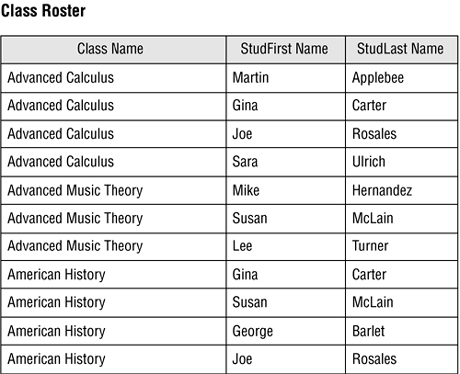
You can modify most of the data within a multitable data view at any time, and the modifications you make will flow through the view and into the base tables. Quite obviously, you can't modify the value of any primary keys that you incorporate from the base tables. As in the case of a single-table view, field specifications and business rules will determine what types of modifications you can make to the data. (Again, be sure to check your RDBMS documentation for any further constraints it may place upon your views.)
The redundant data in the CLASS ROSTER view (which you should have noticed) is the result of merging a record from the CLASSES table with two or more records from the STUDENTS table; the number of times a particular class name appears is equal to the number of students that are registered to attend that class. This apparent redundancy is acceptable because the data is not physically stored in the viewrather, it is drawn from the view's base tables, where it is stored in accordance with the rules of proper database design. RDBMSs commonly display data from multitable views in this fashion.
Another point to note is that a data view does not contain its own primary key. It lacks a primary key because it is not a table; a true table stores data and requires a primary key to serve as a unique identifier for each of its records. You can incorporate a primary key from any (or all) of the base tables within the view, however, when you determine it will contribute to the information the view provides.
Note
In order to avoid any unnecessary ambiguity or confusion, make certain you do not have any primary key indicators within the view symbol when you diagram a data view.
Aggregate View
You use this type of view to display information produced by aggregating a particular set of data in a specific manner. As with a data view, you can define an aggregate view using one or more base tables. You can then include one or more calculated fields that incorporate the functions that aggregate the data and one or more data fields (drawn from the view's base tables) to group the aggregated data. Sum, Average (arithmetic mean), Minimum, Maximum, and Count are the most common aggregate functions that you can apply to a set of data, and every major RDBMS supports them.
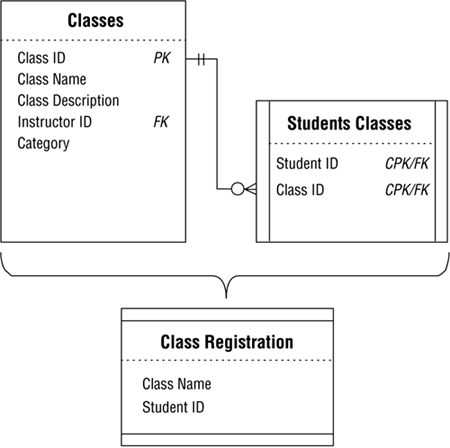
Let's say that you wanted to know how many students are registered for each class, and you're using the tables from the school example shown in Figure 12.3. Your first impulse is to define a data view called CLASS REGISTRATION that will provide the information you need to answer your question. So, you use the CLASS NAME field from the CLASSES table and the STUDENT ID field from the STUDENT CLASSES table to build the view. Figure 12.6 shows a diagram for the new CLASS REGISTRATION view.
Figure 12.6. View diagram for the new CLASS REGISTRATION view.
Now you access the view so that you can answer your question. Figure 12.7 shows a partial sample of the data in the view.
Figure 12.7. A partial sample of data from the CLASS REGISTRATION view.
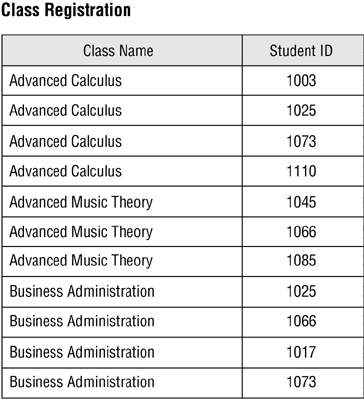
In order to answer your question, you must now count each instance of a given class name so that you can determine how many students are registered for that class. Imagine the work you have ahead of youthis will not be an easy task! Rather than going though all this tedious work, you can answer your question quite easily (and more efficiently) using an aggregate view.
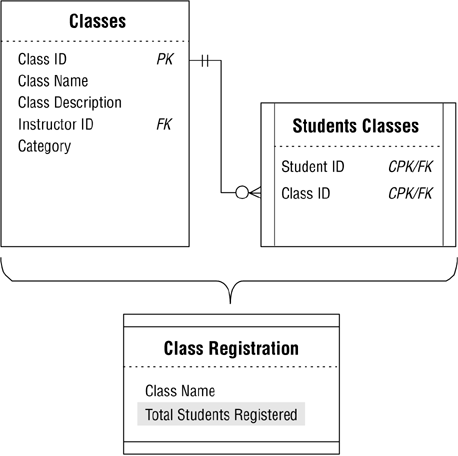
There's no need to define a new view because you can modify the one you have just now. Remove the STUDENT ID field from the view and replace it with a calculated field called TOTAL STUDENTS REGISTERED that counts the number of students per class. (When you work with a calculated field, make certain that you give it a name that is meaningful and that will distinguish it from other calculated fields in the view.) The calculated field will use a Count function to count the number of STUDENT IDs in the STUDENT CLASSES table that are associated with each CLASS ID in the STUDENT CLASSES table. (Later, you'll learn how to document a view and record the expression the calculated field will use.) Figure 12.8 shows the revised diagram for the CLASS REGISTRATION view.
Figure 12.8. Revised diagram for the CLASS REGISTRATION view.
As was the case with the data view, the RDBMS will rebuild and repopulate the CLASS REGISTRATION view every time you access it, using the most current data from the view's base tables. Figure 12.9 shows a sample of the view's data.
Figure 12.9. A sample of data from the revised CLASS REGISTRATION view.
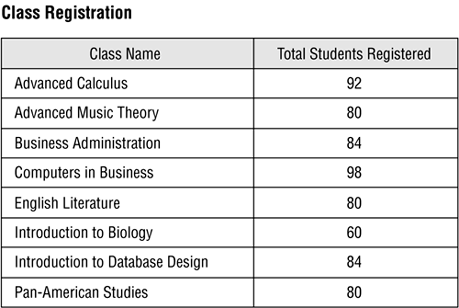
There are three things to note about this view:
The TOTAL STUDENTS REGISTERED field displays a single number for each class name, which represents the total number of students registered for that class.
The redundancy within the CLASS NAME field has been eliminated; all instances of a given class name have been grouped into a single instance. As a result, CLASS NAME is now a grouping field, and its values cannot be modified in any way.
Note
All data fields in an aggregate view are grouping fields.
Because an aggregate view is composed entirely of grouping fields and calculated fields, you cannot modify any of its data.
An aggregate view is most useful as the basis of a report or as a means of providing various types of statistical information. You'll learn later that you can apply filtering criteria to this (or any) view in order to control and restrict the data that the view displays.
Validation View
A validation view is similar to a validation table in that it can help implement data integrity. When a business rule limits a particular field's range of values, you can enforce the constraint just as easily with a validation view as you can with a validation table. The difference between the two lies in their constructiona validation table stores its own data, whereas a validation view draws data from its base tables. Although you can define a validation view using one or more base tables, you'll commonly define a validation table using a single base table and incorporate only two or three of the base table's fields. (This structure is quite similar to that of a validation table.)
For example, let's say you're designing a database for a small contractor and you're working with the tables in Figure 12.10.
Figure 12.10. Tables from a database for a small contractor.
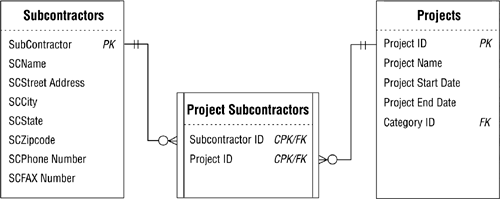
As you can see, the SUBCONTRACTOR ID field in the SUBCONTRACTORS table provides the range of values for the SUBCONTRACTOR ID field in the PROJECT SUBCONTRACTORS table. (Recall that a foreign key draws its values from the primary key to which it refers.) You've determined, however, that you want to restrict the access users currently have to certain fields in the SUBCONTRACTORS table; you've decided that the only fields users should be able to access are the SUBCONTRACTOR ID, SCNAME, SCPHONE NUMBER, and SCFAX NUMBER fields. So, you define a validation view called APPROVED SUBCONTRACTORS that will incorporate these fields and still provide the range of values for the SUBCONTRACTOR ID field in the PROJECT SUBCONTRACTORS table. Figure 12.11 shows a revised diagram of the tables, including the new view.
Figure 12.11. Revised table diagram; note the new APPROVED SUBCONTRACTORS view.
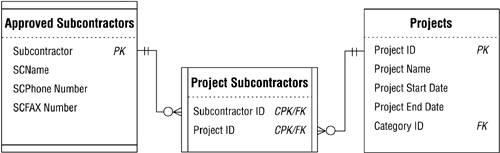
The APPROVED SUBCONTRACTORS view now gives users access only to those fields that you've indicated and provides the appropriate range of values for the SUBCONTRACTOR ID field in the PROJECT SUBCONTRACTORS table. Additionally, the view will still enforce the relationship characteristics that exist for the SUBCONTRACTORS table because it (as you will recall) is the view's base table.
| Top |







