Types of Relationships
Before you begin to establish relationships between tables in the database, you must know what types of relationships can exist between a given pair of tables. Knowing how to identify them properly is an invaluable skill for designing a database successfully.
There are three specific types of relationships that can exist between a pair of tables: one-to-one, one-to-many, and many-to-many. The tables participate in only one type of relationship at any given time. (You'll rarely need to change the type of relationship between a pair of tables. Only major changes in either of the table's structures could cause you to change the relationship.)
Note
The discussion for each type of relationship begins with a generic example of the relationship. Learning how to visualize a relationship generically enables you to understand the principle behind the relationship itself. Once you understand how and why the relationship works, you'll be able to determine whether it exists between a given pair of tables quite easily.
Each discussion also includes an example of how to diagram the relationship. I provide special instructions pertaining to the diagramming process where appropriate and explain the symbols incorporated within the diagram as necessary. This allows you to learn the diagramming method at a reasonable pace and keeps you from having to memorize the entire set of diagram symbols all at once.
Figure 10.2 shows the first symbols you will use to diagram a table relationship.
Figure 10.2. Diagramming symbols for a data table and a subset table.
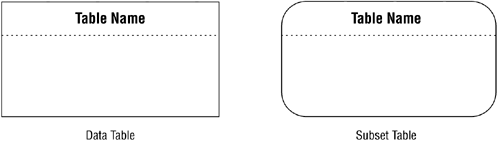
One-to-One Relationships
A pair of tables bears a one-to-one relationship when a single record in the first table is related to only one record in the second table, and a single record in the second table is related to only one record in the first table. Figure 10.3 shows a generic example of a one-to-one relationship.
Figure 10.3. A generic example of a one-to-one relationship.
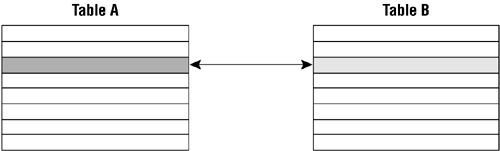
As you can see, a single record in TABLE A is related to only one record in TABLE B, and a single record in TABLE B is related to only one record in TABLE A. A one-to-one relationship usually (but not always) involves a subset table. Figure 10.4 shows an example of a typical one-to-one relationship that you might find in a database for an organization's human resources department. This example also illustrates a situation where neither of the tables is a subset table.
Figure 10.4. A typical example of a one-to-one relationship.
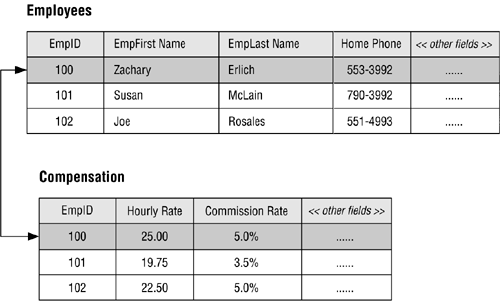
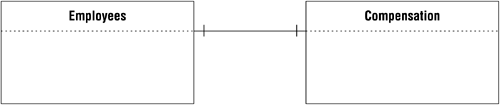
Although the fields in these tables could be combined into a single table, the database designer chose to place the fields that can be viewed by anyone in the organization in the EMPLOYEES table and the fields that can be viewed only by authorized personnel in the COMPENSATION table. Only one record is required to store the compensation data for a given employee, so there is a distinct one-to-one relationship between a record in the EMPLOYEES table and a record in the COMPENSATION table.
A one-to-one relationship usually (but not always) involves a subset table. (Indeed, neither of the tables in Figure 10.4 is a subset table.) Figure 10.5 shows a generic example of how you create a relationship diagram for a one-to-one relationship.
Figure 10.5. Diagramming a one-to-one relationship.
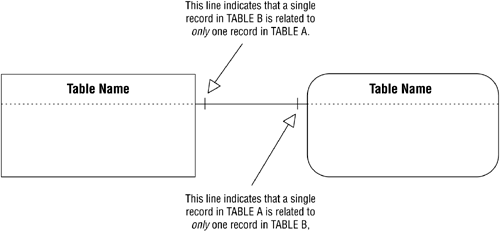
The line that appears between the tables in the diagram indicates the type of relationship, and there is a particular line that you use for each type. Later in this chapter, you'll learn how to modify the line to show the characteristics of the relationship as well. Figure 10.6 shows the relationship diagram for the EMPLOYEES and COMPENSATION tables in Figure 10.4. (Note that a Data Table symbol represents each table.)
Figure 10.6. The relationship diagram for the EMPLOYEES and COMPENSATION tables.
One-to-Many Relationships
A one-to-many relationship exists between a pair of tables when a single record in the first table can be related to one or more records in the second table, but a single record in the second table can be related to only one record in the first table. Let's look at a generic example of this type of relationship.
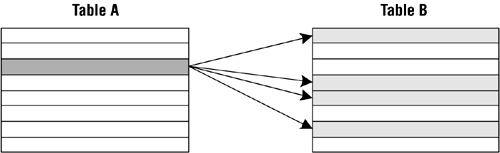
Say you're working with two tables, TABLE A and TABLE B, that have a one-to-many relationship between them. Because of the relationship, a single record in TABLE A can be related to one or more records in TABLE B. Figure 10.7 shows the relationship from the perspective of TABLE A.
Figure 10.7. A one-to-many relationship from the perspective of TABLE A.
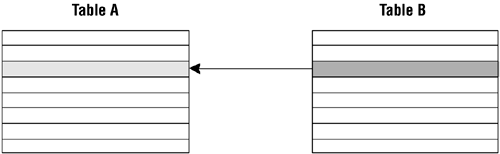
Conversely, a single record in the TABLE B can be related to only one record in TABLE A. Figure 10.8 shows the relationship from the perspective of TABLE B.
Figure 10.8. A one-to-many relationship from the perspective of TABLE B.
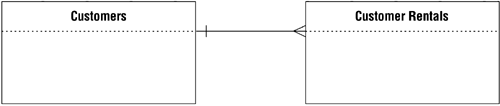
This is by far the most common relationship that exists between a pair of tables in a database, and it is the easiest to identify. It is crucial from a data-integrity standpoint because it helps to eliminate duplicate data and to keep redundant data to an absolute minimum. Figure 10.9 shows a common example of a one-to-many relationship that you might find in a database for a video rental store.
Figure 10.9. A typical example of a one-to-many relationship.
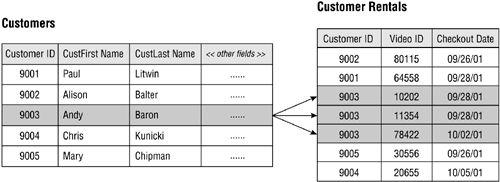
A customer can check out any number of videos, so a single record in the CUSTOMERS table can be related to one or more records in the CUSTOMER RENTALS table. A single video, however, is associated with only one customer at any given time, so a single record in the CUSTOMER RENTALS table is related to only one record in the CUSTOMERS table.
Figure 10.10 shows a generic example of how you create a relationship diagram for a one-to-many relationship.
Figure 10.10. Diagramming a one-to-many relationship.
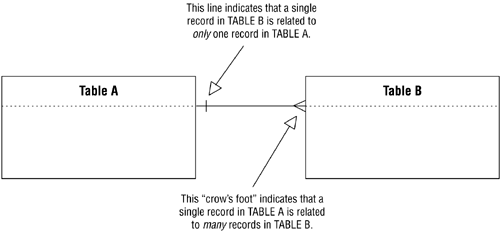
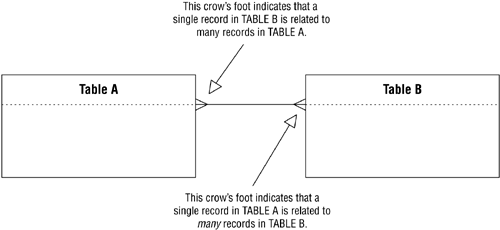
Note that the crow's foot symbol is always located next to the table on the "many" side of the relationship. Figure 10.11 shows the relationship diagram for the CUSTOMERS and CUSTOMER RENTALS tables in Figure 10.9.
Figure 10.11. The relationship diagram for the CUSTOMERS and CUSTOMER RENTALS tables.
Many-to-Many Relationships
A pair of tables bears a many-to-many relationship when a single record in the first table can be related to one or more records in the second table and a single record in the second table can be related to one or more records in the first table.
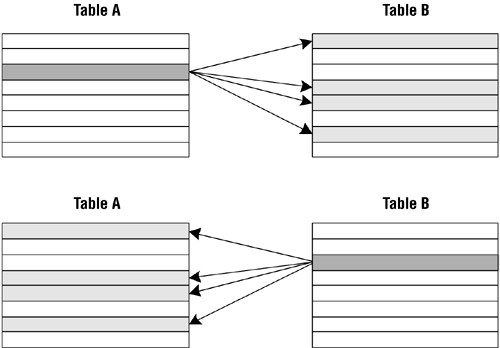
Assume once again that you're working with TABLE A and TABLE B and that there is a many-to-many relationship between them. Because of the relationship, a single record in TABLE A can be related to one or more records (but not necessarily all) in TABLE B. Conversely, a single record in the TABLE B can be related to one or more records (but not necessarily all) in TABLE A. Figure 10.12 shows the relationship from the perspective of each table.
Figure 10.12. A many-to-many relationship from the perspective of both TABLE A and TABLE B.
This is the second most common relationship that exists between a pair of tables in a database. It can be a little more difficult to identify than a one-to-many relationship, so you must be sure to examine the tables carefully. Figure 10.13 shows a typical example of a many-to-many relationship that you might find in a school database, which happens to be a classic example of this type of relationship (no pun intended!).
Figure 10.13. A typical example of a many-to-many relationship.
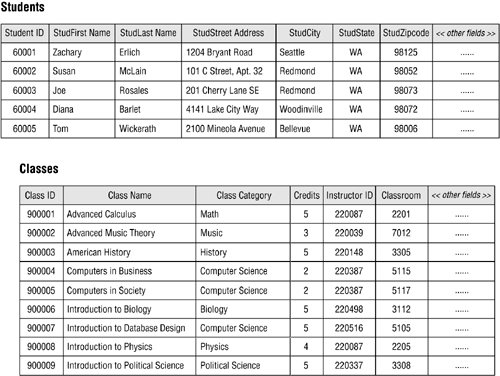
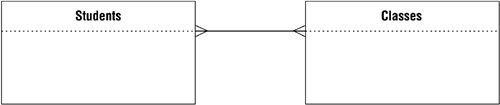
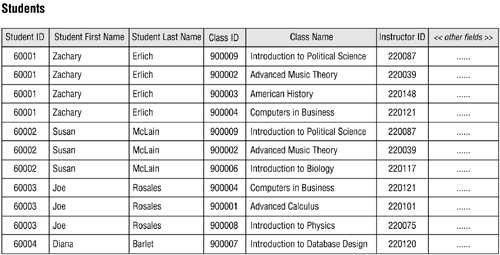
A student can attend one or more classes during a school year, so a single record in the STUDENTS table can be related to one or more records in the CLASSES table. Conversely, one or more students will attend a given class, so a single record in the CLASSES table can be related to one or more records in the STUDENTS table.
Figure 10.14 shows a generic example of how you create a relationship diagram for a many-to-many relationship.
Figure 10.14. Diagramming a many-to-many relationship.
In this case, there is a crow's foot symbol located next to each table. Figure 10.15 shows the relationship diagram for the STUDENTS and CLASSES tables in Figure 10.13.
Figure 10.15. The relationship diagram for the STUDENTS and CLASSES tables.
Problems with Many-to-Many Relationships
A many-to-many relationship has an inherent peculiarity that you must address before you can effectively use the data from the tables involved in the relationship. The issue is this: How do you easily associate records from the first table with records in the second table in order to establish the relationship? This is an important question because you'll encounter problems such as these if you do not establish the relationship properly:
It will be tedious and somewhat difficult to retrieve information from one of the tables.
One of the tables will contain a large amount of redundant data.
Duplicate data will exist within both tables.
It will be difficult for you to insert, update, and delete data.
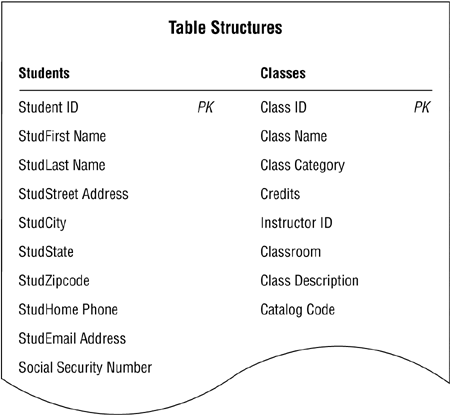
There are two common methods that novice and inexperienced developers use in a futile attempt to address this situation. I'll demonstrate how you might apply these methods using the STUDENTS and CLASSES tables in Figure 10.16 as examples.
Figure 10.16. Structures of the STUDENTS and CLASSES tables.
Note
As this example unfolds, keep in mind that every many-to-many relationship you encounter will exhibit these same issues.
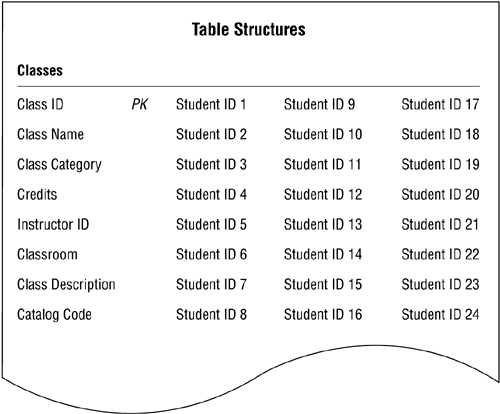
As you can see, there is no actual connection between the two tables, so you have no way of associating records in one table with records in the other table. The first method you might use to attempt to establish a connection involves taking a field from one table and incorporating it a given number of times within the other table. (This approach usually appeals to people who are accustomed to working with spreadsheets.) For example, you could take the STUDENT ID field from the STUDENTS table and incorporate it within the CLASSES table structure, creating as many copies of the field as you need to represent the maximum number of students that could attend any class. Figure 10.17 shows the revised version of the CLASSES table structure.
Figure 10.17. Incorporating STUDENT ID fields within the CLASSES table structure.
This structure is likely to be problematic, so you might try taking the CLASS ID field from the CLASSES table and incorporating it within the STUDENTS table structure instead. Figure 10.18 shows the revised version of the STUDENTS table structure.
Figure 10.18. Incorporating CLASS ID fields within the STUDENTS table structure.

Do these structures look (vaguely) familiar? They should. All you've done using this method is introduce a "flattened" multivalued field into the table structure. In doing so, you've also introduced the problems associated with a multivalued field. (If necessary, review Chapter 7.) Although you know how to resolve a multivalued field, this is not a good or proper way to establish the relationship.
The second method you might attempt to use is simply a variation of the first method. In this case, you take one or more fields from one table and incorporate a single instance of each field within the other table. For example, you could take the CLASS ID, CLASS NAME, and INSTRUCTOR ID fields from the CLASSES table and incorporate them into the STUDENTS table in order to identify the classes in which a student is currently enrolled. This may seem to be a distinct improvement over the first method, but you'll see that there are problems that arise from such modifications when you load the revised STUDENTS table with sample data.
Figure 10.19 clearly illustrates the problems you'll encounter using this method.
The table contains unnecessary duplicate fields. You learned all about unnecessary duplicate fields and the problems they pose back in Chapter 7, so you know that using them here is not a good idea. Besides, it is very likely that the CLASS NAME and INSTRUCTOR ID fields are not appropriate in the STUDENTS tablethe CLASS ID field identifies the class sufficiently, and it is really all you need to identify the classes a student is taking.
There is a large amount of redundant data. Even if you remove the CLASS NAME and INSTRUCTOR ID fields from the STUDENTS table, the CLASS ID field will still produce a lot of redundant data.
It is difficult to insert a new record. If you enter a record in the STUDENTS table for a new class (instead of entering it in the CLASSES table) without also entering student data, the fields pertaining to the student will be nullincluding the primary key of the STUDENTS table (STUDENT ID). This will automatically trigger a violation of the Elements of a Primary Key because the primary key cannot be null; therefore, you cannot insert the record into the table until you can provide a proper primary key value.
It is difficult to delete a record. This is especially true if the only data about a new class has been recorded in the particular student record you want to delete. Note the record for Diana Barlet, for example. If Diana decides not to attend any classes this year and you delete her record, you will lose the data for the "Introduction to Database Design" class. That might not create a serious problemunless someone neglected to enter the data about this class into the CLASSES table as well. Once you delete Diana's record, you'll have to re-enter all of the data for the class in the CLASSES table.
Figure 10.19. The revised STUDENTS table with sample data.
Fortunately, you will not have to worry about any of these problems because you're going to learn the proper way to establish a many-to-many relationship.
Self-Referencing Relationships
This particular type of relationship does not exist between a pair of tables, which is why it isn't mentioned at the beginning of this section. It is instead a relationship that exists between the records within a table. Ironically, you'll still regard this throughout the design process as a table relationship.
A table bears a self-referencing relationship (also known as a recursive relationship) to itself when a given record in the table is related to other records within the table. Similar to its dual-table counterpart, a self-referencing relationship can be one-to-one, one-to-many, or many-to-many.
One-to-One
A self-referencing one-to-one relationship exists when a given record in the table can be related to only one other record within the table. The MEMBERS table in Figure 10.20 is an example of a table with this type of relationship. In this case, a given member can sponsor only one other member within the organization; the SPONSOR ID field stores the member identification number of the member acting as a sponsor. Note that Susan McLain is Tom Wickerath's sponsor.
Figure 10.20. Example of a self-referencing one-to-one relationship.
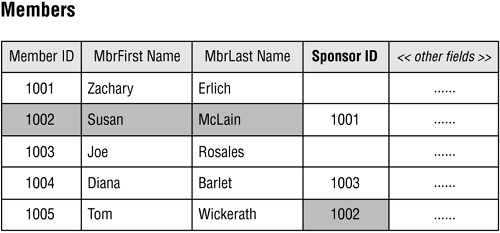
Figure 10.21 shows how you diagram this type of relationship.
Figure 10.21. Diagramming a self-referencing one-to-one relationship.
One-to-Many
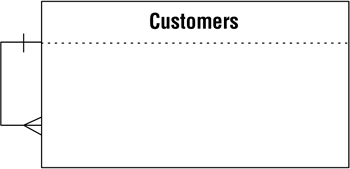
A table bears a self-referencing one-to-many relationship to itself when a given record in the table can be related to one or more other records within the table. Figure 10.22 shows an example in which a given customer can refer other customers to the organization. The REFERRED BY field stores the customer identification number of the customer making the referral. Note that Paul Litwin referred both Andy Baron and Mary Chipman.
Figure 10.22. Example of a self-referencing one-to-many relationship.
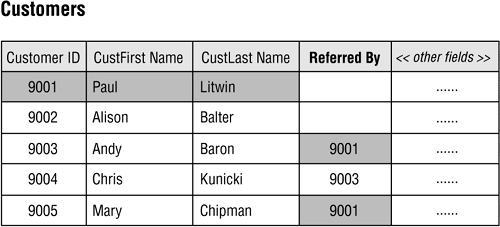
Figure 10.23 shows how you diagram a self-referencing one-to-many relationship.
Figure 10.23. Diagramming a self-referencing one-to-many relationship.
Many-to-Many
A self-referencing many-to-many relationship exists when a given record in the table can be related to one or more other records within the table and one or more records can themselves be related to the given record. This may sound somewhat confusing at first, but the example in Figure 10.24 should help clarify the matter.
Figure 10.24. Example of a self-referencing many-to-many relationship.
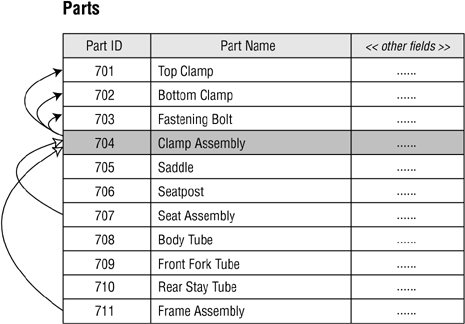
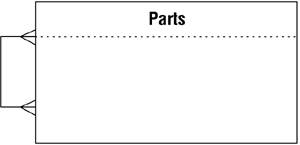
In this case, a particular part can comprise several different component parts, and it can itself be a component of other parts. For example, a clamp assembly (Part ID 704) is composed of a fastening bolt (Part ID 703), a bottom clamp (Part ID 702), and a top clamp (Part ID 701). Additionally, the clamp assembly is itself a component of a seat assembly (Part ID 707) and a frame assembly (Part ID 711). Figure 10.25 shows how you diagram this type of relationship.
Figure 10.25. Diagramming a self-referencing many-to-many relationship.
Note
Before you begin to work through the examples in the remainder of the chapter, now is a good time to remember a principle I presented in the introduction:
Focus on the concept or technique and its intended results, not on the example used to illustrate it.
There are, without a doubt, any number of ways in which you can relate the tables in these examples (and in the case study as well), depending on each table's role within a given database. The manner in which I use the examples here is not important; what is important are the techniques I use to identify and establish relationships between tables. Once you learn these techniques, you can identify and establish relationships for any pair of tables within any context you may encounter.
Now that you've learned about the various types of table relationships, your next task is to identify the relationships that currently exist among the tables in the database.
| Top |







