Database-Design Methods
Traditional Design Methods
In general, traditional methods of database design incorporate three phases: requirements analysis, data modeling, and normalization.
The requirements-analysis phase involves an examination of the business being modeled, interviews with users and management to assess the current system and to analyze future needs, and an assessment of information requirements for the business as a whole. This process is relatively straightforward, and, indeed, the design process presented in this book follows the same line of thinking.
The data-modeling phase involves modeling the database structure using a data-modeling method, such as entity-relationship (ER) diagramming, semantic-object modeling, or object-role modeling. Each of these modeling methods provides a means of visually representing various aspects of the database structure, such as the tables, table relationships, and relationship characteristics. In fact, the modeling method used in this book is a basic version of ER diagramming. Figure 2.1 shows an example of a basic ER diagram.
Figure 2.1. An example of a basic ER diagram.

Note
I've incorporated the data-modeling method I use in this book into the design process itself rather than treating it separately. I'll introduce and explain each modeling technique as appropriate throughout the process.
Each data-modeling method incorporates a set of diagramming symbols used to represent a database's structure and characteristics. For example, the diagram in Figure 2.1 provides information on several aspects of the database.
The rectangles represent two tables called AGENTS and CLIENTS.
The diamond represents a relationship between these two tables, and the "1:N" within the diamond indicates that it is a one-to-many relationship.
The vertical line next to the AGENTS table indicates that a client must be associated with an agent, and the circle next to the CLIENTS table indicates that an agent doesn't necessarily have to be associated with a client.
Fields are also defined and associated with the appropriate tables during the data-modeling phase. Each table is assigned a primary key, various levels of data integrity are identified and implemented, and relationships are established via foreign keys. Once the initial table structures are complete and the relationships have been established according to the data model, the database is ready to go through the normalization phase.
Normalization is the process of decomposing large tables into smaller ones in order to eliminate redundant data and duplicate data and to avoid problems with inserting, updating, or deleting data. During the normalization process, table structures are tested against normal forms and then modified if any of the aforementioned problems are found. A normal form is a specific set of rules that can be used to test a table structure to ensure that it is sound and free of problems. There are a number of normal forms, and each one is used to test for a particular set of problems. The normal forms currently in use are First Normal Form, Second Normal Form, Third Normal Form, Fourth Normal Form, Fifth Normal Form, Boyce-Codd Normal Form, and Domain/Key Normal Form.
The Design Method Presented in This Book
The design method that I use in this book is one that I've developed over the years. It incorporates a requirements analysis and a simple ER-diagramming method to diagram the database structure. However, it does not incorporate the traditional normalization process or involve the use of normal forms. The reason is simple: Normal forms can be confusing to anyone who has not taken the time to study formal relational database theory. For example, examine the following definition of Third Normal Form:
A relvar is in 3NF if and only if it is in 2NF and every non-key attribute is nontransitively dependent on the primary key.[1]
[1] C. J. Date, An Introduction to Database Systems, 7th ed. (Boston, MA: Addison-Wesley, 2000), 362; emphasis added.
This description is relatively meaningless to a reader who is unfamiliar with the terms relvar, 3NF, 2NF, non-key attribute, transitively dependent, and primary key.
The process of designing a database is not and should not be hard to understand. As long as the process is presented in a straightforward manner and each concept or technique is clearly explained, anyone should be able to design a database properly. For example, the following definition is derived from the results of using Third Normal Form against a table structure, and I believe most people will find it clear and easy to understand:
A table should have a field that uniquely identifies each of its records, and each field in the table should describe the subject that the table represents.
The process I used to formulate this definition is the same one I used to develop my entire design methodology.
Back in the late 1980s, it occurred to me that the relational model had been in existence for almost 20 years and that people had been designing databases using the same basic methodology for about 12 years. I was using the traditional design methodology at that time, but I occasionally found it difficult to employ. The two things that bothered me the most about it were the normalization process (as a whole) and the seemingly endless iterations it took to arrive at a proper design. Of course, these seemed to be sore points with most of the other database developers that I knew, so I certainly wasn't alone in my frustrations. I thought about these problems for quite some time, and then I came up with a solution.
I already knew that the purpose of normalization is to take an improperly or poorly designed table and transform it into a table with a sound structure. I also understood the process: Take a given table and test it against the normal forms to determine whether it is properly designed. If it isn't designed properly, make the appropriate modifications, retest it, and repeat the entire process until the table structure is sound. Figure 2.2 shows how I visualized the process at this point.
Figure 2.2. A graphic representation of the general normalization process.
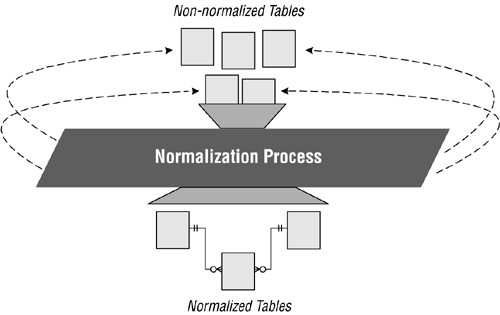
I kept these facts in mind and then posed the following questions:
If we assume that a thoroughly normalized table is properly and efficiently designed, couldn't we identify the specific characteristics of such a table and state these to be the attributes of an ideal table structure?
Couldn't we then use that ideal table as a model for all tables we create for the database throughout the design process?
The answer to both questions, of course, is yes, so I began in earnest to develop the basis for my "new" design methodology. I first compiled distinct sets of guidelines for creating sound structures by identifying the final characteristics of a well-defined database that successfully passed the tests of each normal form. I then conducted a few tests, using the new guidelines to create table structures for a new database and to correct flaws in the table structures of an existing database. These tests went very well, so I decided to apply this technique to the entire traditional design methodology. I formulated guidelines to address other issues associated with the traditional design method, such as domains, subtypes, relationships, and referential integrity. After I completed the new guidelines, I performed more tests and found that my methodology worked quite well.
The main advantage of my design methodology is that it removes many aspects of the traditional design methodology that new database developers find intimidating. For example, normalization, in the traditional sense, is now transparent to the developer because it has been incorporated (via the new guidelines) throughout the design process. Another major advantage is that the methodology is clear and easy to implement. I believe much of this is due to the fact that I've written all the guidelines in plain English, making them easy for most anyone to understand.
It's important for you to understand that this design methodology will yield a fully normalized database structure only if you follow it as faithfully as you would any other design methodology. You cannot shortcut, circumvent, de-emphasize, or omit any part of this methodology (or any design methodology, for that matter) and expect to develop a sound structure. You must go through the process diligently, methodically, and completely in order reap the expected rewards.
There are a few basic terms you'll have to learn before you delve into the design process, and we'll cover them in the next chapter.
| Top |







