Refining the Fields
Now that you've assigned fields to each table, you'll refine the fields by improving the field names and resolving any structural problems that may exist. Then you'll refine the tables further by establishing that you've assigned the appropriate fields to each table and that the table structures are sound.
Improving the Field Names
As you know, a field represents a characteristic of the subject of the table to which it belongs. You can easily identify the characteristic a field is supposed to represent when that field has an appropriate name. A field name that is ambiguous, vague, or unclear is a sure sign of trouble and suggests that you have not thoroughly identified the purpose of the field.
Earlier in this chapter, you learned a set of guidelines for naming a table. Now you'll learn another set of guidelines that you'll apply to field names. Fortunately, many of them are similar to the guidelines governing table names, so you're already familiar with most of the concepts.
Guidelines for Creating Field Names
Create a unique, descriptive name that is meaningful to the entire organization. A given field name should appear only once in the entire database; the only exception to this rule occurs when the field serves to establish a relationship between two tables. Make certain the name is descriptive enough to convey its meaning accurately to everyone who sees it. (Chapter 10 covers this issue in greater detail.)
Create a name that accurately, clearly, and unambiguously identifies the characteristic a field represents. "Phone Number" is a good example of an inaccurate, ambiguous field name. What kind of phone number does it represent? A home phone? An office phone? A cellular phone? Learn to be specific. If you need to record each of these types of phone numbers, then create "Home Phone," "Work Phone," and "Cellular Phone" fields.
In Chapter 6, you learned how to resolve generic field names, such as "Address," "City," and "State" by using the table name as a prefix for the field name. This produces names such as "Employee Address," "Customer Address," and "Supplier Address." When you have field names such as these, you can abbreviate the prefix (for brevity's sake) by using the first three or four letters of the table name as the revised prefix. This allows you to transform the previous field names into "EmpAddress," "CustAddress," and "SuppAddress." This technique helps you fulfill not only this guideline, but the previous one as well.
Note
The degree to which you use prefixes within a table is a matter of style. When a table contains generic field names, some database designers will choose to prefix the generic names only, while others elect to prefix all of the field names within the table. Regardless of the prefix method you choose to use, it is very important that you use it consistently throughout the database structure.
I personally prefer to prefix the generic field names only, and I'll follow this preference throughout the remainder of the book.
Use the minimum number of words necessary to convey the meaning of the characteristic the field represents. You want to avoid lengthy field names, but at the same time, you also want to avoid using a single word as a field name if that word is inappropriate. For example, if you're trying to record the date a particular employee joined the organization, "Hired" is too short (and slightly vague) and "Date That the Employee Was Hired" is too long! "Date Hired," however, is a more appropriate name and accurately represents the characteristic the field represents.
Do not use acronyms, and use abbreviations judiciously. Acronyms can be hard to decipher and often lead to misunderstanding. Imagine a field named "CAD_SW." How would you determine what the field represents? On the other hand, you can use abbreviations so long as you use them sparingly and handle them with care. Only use an abbreviation if it supplements or enhances the field name in a positive manner. An abbreviation shouldn't make a field name ambiguous or diminish its meaning.
Do not use words that could confuse the meaning of the field name. A field name that contains redundant words or synonyms can make the name's meaning unclear and subject to misinterpretation. For instance, consider the name "Digital Identification Code Number." "Digital" and "number" are redundant, so you can eliminate either one without diminishing the field name's meaning. Let's assume that you decide to eliminate "digital." You can split the remaining name into two smaller names: "Identification Code" and "Identification Number." These names are often synonymous, and you can easily use either as the final field name. In this situation, just use the name that is most meaningful within the organization.
Do not use names that implicitly or explicitly identify more than one characteristic. These types of names are easy to spot because they typically use the words "and" or "or." Field names that contain a slash (\) or an ampersand (&) are dead giveaways as well. When you encounter a field with a name such as "Area or Location" or "Phone\Fax," identify each characteristic that the name implies, and create a new field for the characteristic. Then test the new field name against these guidelines to ensure that the name is sound.
Use the singular form of the name. A field with a plural name, such as "Skills," implies that it may contain two or more values for a given record, which is not a good idea. (You'll learn more about this later in the chapter.) A field name is singular because it represents a single characteristic of the subject of the table to which it belongs. A table name, on the other hand, is plural because it represents a collection of similar objects or events. You can distinguish table names from field names quite easily when you use this naming convention.
With these guidelines in mind, review each table and determine whether you can make improvements to any of the field names. When you're finished, you're ready to identify and resolve any problems with the fields. Figure 7.12 shows revisions to the field names of the table structures in Figure 7.11.
Figure 7.12. Revised field names.
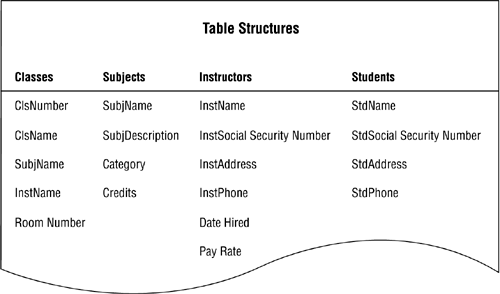
In Figure 7.12, "Classes" is shortened to "Cls," "Subjects" is shortened to "Subj," "Instructors" is shortened to "Inst," "Student" is shortened to "Std," and "Social Security Number" replaces "SSN." Remember that abbreviations can be very useful so long as they are meaningful and understood by everyone in the organization. Using proper and appropriate abbreviations will not detract from the meaning of the field name.
Note
Throughout the remainder of the chapter and the rest of the book, table names within the text appear in all capital letters (such as VENDORS) and field names within the text appear in small capital letters (such as VENDOR ID NUMBER).
Using an Ideal Field to Resolve Anomalies
Although you've carefully identified the fields on your preliminary field list, you may have created a few fields that could prove problematic to the table structure. Poorly defined fields can cause duplicate data and redundant data, and they can be difficult to use. You might find it difficult to determine whether any of the fields in a table is going to cause problems unless you know the warning signs. The best way to identify potentially troublesome fields is to determine whether they comply with the Elements of the Ideal Field. These elements constitute a set of guidelines you can use to create sound field structures and to spot poorly designed fields easily.
Elements of the Ideal Field
It represents a distinct characteristic of the subject of the table. As you know, a table represents a specific subject, which can be an object or event. The ideal field represents a distinct characteristic of that object or event.
It contains only a single value. A field that can potentially store two or more occurrences of the same value is known as a multivalued field. A multivalued field causes data-redundancy problems (quite obviously) and is difficult to use when you try to edit, delete, or sort the data within it. The ideal field is free of these problems because it contains only a single value.
It cannot be deconstructed into smaller components. A field that can potentially store two or more distinct items within a value is known as a multipart (or composite) field. Like the multivalued field, this type of field causes problems when you try to edit, delete, or sort the data within it. These problems don't occur with an ideal field because it represents a single, distinct characteristic of the subject of the table to which it belongs. (You'll learn more about multivalued and multipart fields in just a moment.)
It does not contain a calculated or concatenated value. The values of the fields in a table should be mutually independent; a particular field should not have to depend on the values of other fields for its own value. A calculated field, however, does depend on the values of other fields for its own value, and therein lies the problem. The calculated field's value is not updated when the value of any field participating in the calculation changes. It then becomes the responsibility (and an undesirable burden) of the user or the database application program to update the calculated field when this type of change takes place. This is precisely why you deal with calculated fields separately.
It is unique within the entire database structure. The only duplicate fields that appear in a properly designed database are those that establish relationships between tables. If duplicate fields other than these exist in a table, it is very likely that the table will accumulate unnecessary redundant data and that the data within the duplicate fields will inevitably become inconsistent.
Note
Remember that you're dealing strictly with the logical database structure at this point. You might have cause to duplicate specific fields when you physically implement the database in an RDBMS program. During that process, however, you're making a conscious decision to duplicate the fields, and you're prepared to deal with the consequences of that decision.
It retains a majority of its properties when it appears in more than one table. A field that establishes a relationship between two tables is a structural component of each table. A majority of the field's properties remain constant in each occurrence of the field. (Chapters 9 and 10 cover this matter in greater detail.)
Although you now know the specific elements of an ideal field, you'll still find it difficult in many instances to identify problematic fields just by looking at their names. Figure 7.13 shows a table structure that helps to illustrate this point. Take a moment and try to determine whether each field complies with the Elements of the Ideal Field or needs to be modified.
Figure 7.13. A table containing fields with questionable structures.
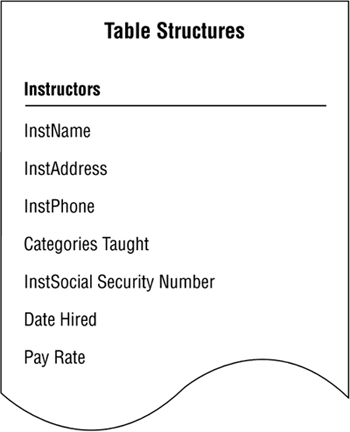
Each field on the list seems to conform to the Elements of the Ideal Field. Examine the list carefully, however, and you'll see that some fields don't really comply with the second and third elements. Three fields have anomalies that will cause problems unless you resolve them: INSTNAME, INSTADDRESS, and CATEGORIES TAUGHT. If you doubt this assertion, you can test it by "loading" the table with sample data. This will quickly reveal anomalies, if any exist, and is the best way to confirm whether a field complies with all of the Elements of the Ideal Field.
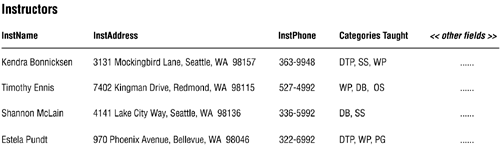
You don't have to create a table physically to perform this test. Take a sheet of legal paper and lay it in front of you lengthwise from left to right. Write the name of each field across the top of the paper, starting from the left-hand side; leave enough space between the field names to allow room for the values you're going to place underneath them. Then enter records into the table by filling in each field with some sample data; be sure the sample data represents the data you're actually going to enter into the database. You need only a few records for the test to work properly. Your sheet of paper should look similar to the one in Figure 7.14.
Figure 7.14. Testing a table with sample data.
Note
As I mentioned in Chapter 3, I show only those fields that are most relevant to the discussion at hand and use <<other fields>> to represent fields that are inessential to the example.
Now you can easily identify which fields are going to be troublesome unless they are resolved. As you can see, INSTNAME and INSTADDRESS are both multipart fields, and CATEGORIES TAUGHT is a multivalued field. You must resolve these fields before you can refine the table structure.
Resolving Multipart Fields
Working with a multipart field is difficult because its value contains two or more distinct items. It's hard to retrieve information from a multipart field, and it's hard to sort or group the records in the table by the field's value. The INSTADDRESS field in Figure 7.14 illustrates these difficulties; you'd certainly have a problem retrieving information for the city of Seattle or sorting information by zip code.
You resolve a multipart field by identifying the distinct items within the field's value and treating each item as an individual field. Accomplish this task by asking yourself a simple question: "What specific items does this field's value represent?" Once you've answered the question and identified the items (as best you can), transform each item into a new field.
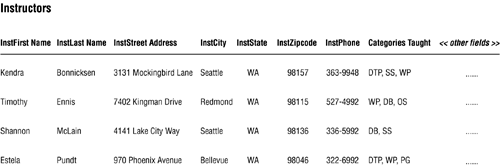
In Figure 7.14, the value of the field INSTNAME represents two items: the first name and the last name of an instructor. You resolve this field by creating a new INSTFIRST NAME field and a new INSTLAST NAME field. The value of INSTADDRESS represents four items: the street address, city, state, and zip code of an instructor. You transform these items into fields as well; they will appear in the table as INSTSTREET ADDRESS, INSTCITY, INSTSTATE, and INSTZIPCODE. Figure 7.15 shows the newly revised INSTRUCTORS table.
Figure 7.15. Resolving the multipart fields in the INSTRUCTORS table.
Some multipart fields are hard to recognize. Take a look at the INSTRUMENTS table in Figure 7.16. At first glance, the table doesn't seem to contain multipart fields. When you examine the data in the table more closely, however, you'll see that INSTRUMENT ID is actually a multipart field. This field's value represents two distinct items: the category to which the instrument belongsAMP (amplifier), GUIT (guitar), MFX (multieffects unit), SFX (single-effect unit)and the instrument's identification number. Clearly, you should deconstruct INSTRUMENT ID into two smaller fields in accordance with the third element of an ideal field. Imagine how difficult it would be for you to update the field's value if the MFX category changed to MFU if you don't do this. You would have to write programming code to parse the value, test for the existence of MFX, and then replace it with MFU if it existed within the parsed value. It's not so much that you can't do this, but you would definitely be working harder than necessary, and you shouldn't have to go through this at all if you have a properly designed database.
Figure 7.16. An example of a "hidden" multipart field.

Resolving Multivalued Fields
As you know, a multivalued field can potentially store two or more occurrences of the same value. Fortunately, you'll recognize a multivalued field when you see one. The field's name is often plural and its value almost invariably contains a number of commas, which serve to separate the various occurrences that exist within the value itself.
Resolving multipart fields is not very hard at all, but resolving multivalued fields can be a little more difficult and will take some work. A multivalued field has the same fundamental set of problems as a multipart field, as the CATEGORIES TAUGHT field in Figure 7.17 clearly illustrates. For example, you'll have difficultly retrieving information for everyone who teaches a specific category (such as WP), you can't sort the data in any meaningful fashion, and, most important, you don't have room to enter more than four categories. What happens when one or more instructors teach five categories? The only option you'll have is to make the field larger every time you need to enter more values than it will currently allow.
Figure 7.17. Identifying a multivalued field.

So how would you resolve this multivalued field? Your first thought may be to create a new field for each value, thus "flattening" the multivalued field into several single-valued fields. Figure 7.18 shows what will happen if you follow through with this idea.
Figure 7.18. The result of "flattening" the CATEGORIES TAUGHT field.

Unfortunately, this is not much of an improvement at all. There are three specific problems that arise from this type of structure:
Retrieving category information will be tedious at best. A user attempting to find all instructors who teach the WP category must be sure to search for this value within each of the category fieldsthere is no guarantee that WP is consistently stored in the same field. Failure to do so means that the user runs the risk of overlooking a qualified instructor.
There is no way for the RDBMS program to sort the category data in a meaningful fashion.
This structure is inherently volatile. In its current state, the table unnecessarily restricts the number of categories an instructor can teach; you must create additional category fields when you have instructors who teach more than three categories. Adding more category fields just compounds the first two problems.
Realizing that flattening the CATEGORIES TAUGHT field won't solve your problem, your next thought is to bring the field into compliance with the second element of an ideal field and declare that it will contain only a single value. Although this is a good impulse and a step in the right direction, it will not resolve the matter completely because it will introduce yet another problem: data redundancy. Figure 7.19 illustrates what happens when you follow through with this particular idea. Note that there is now a single value in the CATEGORIES TAUGHT field for each record in the table.
Figure 7.19. The result of bringing CATEGORIES TAUGHT into compliance with the second element of an ideal field.
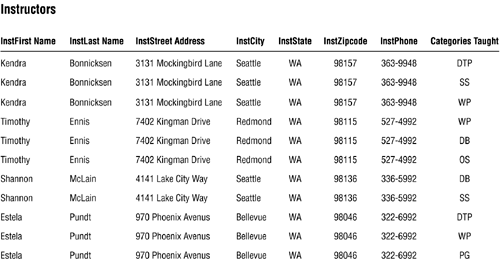
The values in CATEGORIES TAUGHT cause redundant data because you must duplicate a given instructor record for each category that the instructor teaches. This redundancy is obviously unacceptable, so you'll have to resolve this problem in some manner.
You can avoid this situation entirely by using these steps to resolve a multivalued field:
Remove the field from the table and use it as the basis for a new table. If necessary, rename the field in accordance with the field name guidelines that you learned earlier in this chapter.
Use a field (or set of fields) from the original table to relate the original table to the new table; try to select fields that represent the subject of the table as closely as possible. The field(s) you choose will appear in both tables. (You'll learn more about relating tables in Chapter 10.)
Assign an appropriate name, type, and description to the new table and add it to the final table list.
These steps form a generic procedure that you can use to resolve any multivalued field you encounter in a table. Now, apply these steps to the CATEGORIES TAUGHT field.
Remove the field from the INSTRUCTORS table and use it as the basis of a new table. Because this will now be a single-valued field, rename the field CATEGORY TAUGHT.
Use INSTFIRST NAME and INSTLAST NAME as the connecting fields that will relate the INSTRUCTORS table to the new table, and add them to the structure of the new table.
Give the new table a proper name, compose a suitable description, and add the table to the final table list. (Indicate the table's type as "Data.") Here's one possible name and description you might use for the new table.
Instructor Categories the categories of software programs that an instructor is qualified to teach. The information this table provides allows us to make certain that there is an adequate number of instructors for each software category.
Figure 7.20 shows the revised INSTRUCTORS table and the new INSTRUCTOR CATEGORIES table.
Figure 7.20. Resolving the multivalued field in the INSTRUCTORS table.
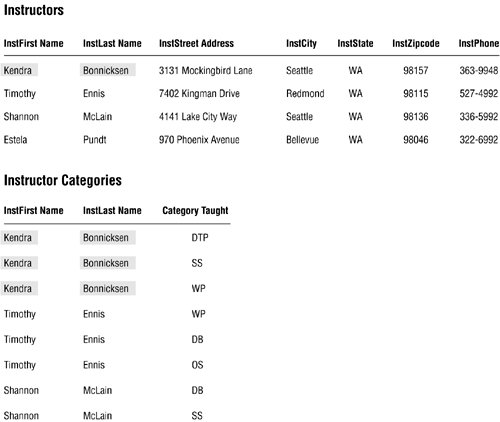
Note that the new INSTRUCTOR CATEGORIES table is free from the problems typically associated with multivalued fields because CATEGORY TAUGHT is a single-value field. You can easily retrieve information for a particular instructor or category, and you can sort the records in a meaningful manner. Also note that the INSTFIRST NAME and INSTLAST NAME fields retain their names in the new table, making them compliant with the fifth element of an ideal field.
Although the new table contains redundant data, the redundancy is acceptable because it is minimal. It's a fact of life that a relational data base will always contain some amount of redundant data. Your goal as the database architect is to make certain that it has only an absolute minimum amount of redundant data.
Figure 7.21 shows a version of the INSTRUCTORS table that contains three multivalued fields:
CATEGORIES TAUGHT This indicates the categories of classes that an instructor can teach.
MAXIMUM LEVEL TAUGHT This indicates the maximum skill level that the instructor can teach for a given category.
LANGUAGES SPOKEN This indicates the foreign languages that an instructor can speak.
Figure 7.21. A version of the INSTRUCTORS table containing three multivalued fields.
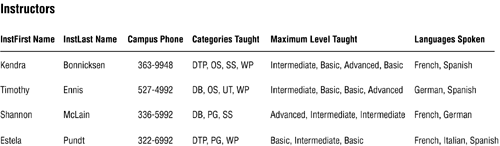
Your task here seems relatively clearyou're going to use the procedure you've just learned to resolve these multivalued fields. You then notice one small, relatively obscure problem: There is a distinct one-to-one association between values in CATEGORIES TAUGHT and the values in MAXIMUM LEVEL TAUGHT for any given record. You probably wouldn't have noticed this anomaly had you not carefully examined the sample data within these fields. Don't worry; you'll still use the same procedure, but with one minor modification.
You'll occasionally encounter a situation such as this, where some given field (whether single- or multivalued) depends on a particular multivalued field. You can easily fix this problem by including the dependent field in the structure of the new table you build to resolve the multivalued field. Figure 7.22 shows the results of consolidating this technique with the previous one to resolve CATEGORIES TAUGHT. (It shows the resolution of LANGUAGES SPOKEN as well.)
Figure 7.22. Resolving the multipart fields in the INSTRUCTORS table.
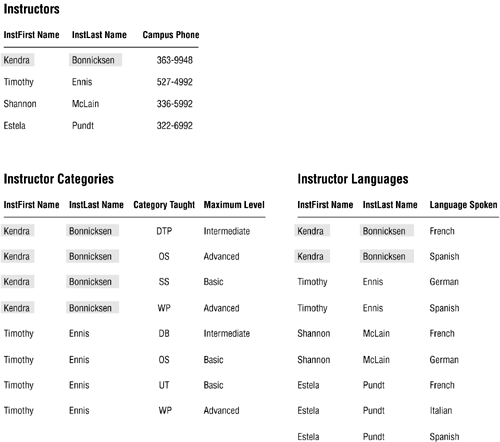
The redundancy in the new tables is acceptable because, once again, it is minimal. In Chapter 10, you'll learn how to reduce this type of redundancy even further by relating the tables with primary keys and foreign keys.
| Top |







