Structure-Related Terms
Table
According to the relational model, data in a relational database is stored in relations, which are perceived by the user as tables. Each relation is composed of tuples (records) and attributes (fields). Figure 3.6 shows a typical table structure.
Figure 3.6. A typical table structure.
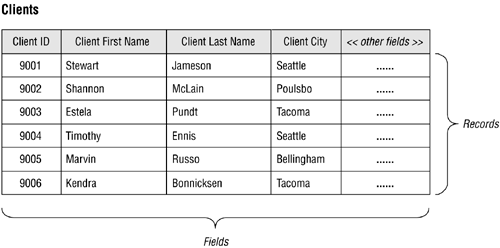
Tables are the chief structures in the database and each table always represents a single, specific subject. The logical order of records and fields within a table is of absolutely no importance, and every table contains at least one fieldknown as a primary keythat uniquely identifies each of its records. (In Figure 3.6, for example, CLIENT ID is the primary key of the CLIENTS table.) In fact, data in a relational database can exist independently of the way it is physically stored in the computer because of these last two table characteristics. This is great news for the user because he or she isn't required to know the physical location of a record in order to retrieve its data.
The subject that a given table represents can either be an object or event. When the subject is an object, it means that the table represents something that is tangible, such as a person, place, or thing. Regardless of its type, every object has characteristics that can be stored as data. This data can then be processed in an almost infinite number of ways. Pilots, products, machines, students, buildings, and equipment are all examples of objects that can be represented by a table, and Figure 3.6 illustrates one of the most common examples of this type of table.
When the subject of a table is an event, it means that the table represents something that occurs at a given point in time having characteristics you wish to record. These characteristics can be stored as data and then processed as information in exactly the same manner as a table that represents some specific object. Examples of events you may need to record include judicial hearings, distributions of funds, lab test results, and geological surveys. Figure 3.7 shows an example of a table representing an event that we all have experienced at one time or anothera doctor's appointment.
Figure 3.7. A table representing an event.
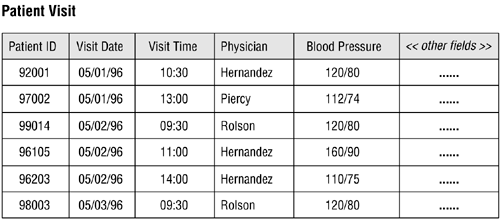
A table that stores data used to supply information is called a data table, and it is the most common type of table in a relational database. Data in this type of table is dynamic because you can manipulate it (modify, delete, and so forth) and process it into information in some form or fashion. You'll constantly interact with these types of tables as you work with your database.
A validation table (also known as a lookup table), on the other hand, stores data that you specifically use to implement data integrity. A validation table usually represents subjects, such as city names, skill categories, product codes, and project identification numbers. Data in this type of table is static because it will very rarely change at all. Although you have very little direct interaction with these tables, you'll frequently use them indirectly to validate values that you enter into a data table. Figure 3.8 shows an example of a validation table.
Figure 3.8. An example of a validation table.
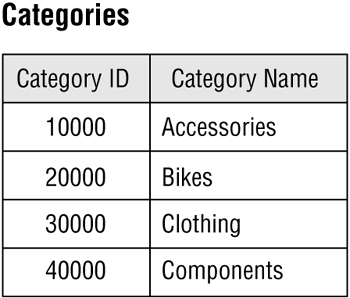
I'll discuss validation tables in more detail in Chapter 11.
Field
A field (known as an attribute in relational database theory) is the smallest structure in the database and it represents a characteristic of the subject of the table to which it belongs. Fields are the structures that actually store data. The data in these fields can then be retrieved and presented as information in almost any configuration that you can imagine. The quality of the information you get from your data is in direct proportion to the amount of time you've dedicated to ensuring the structural integrity and data integrity of the fields themselves. There is just no way to underestimate the importance of fields.
Every field in a properly designed database contains one and only one value, and its name will identify the type of value it holds. This makes entering data into a field very intuitive. If you see fields with names such as FIRSTNAME, LASTNAME, CITY, STATE, and ZIPCODE, you know exactly what type of values go into each field. You'll also find it very easy to sort the data by state or look for everyone whose last name is "Hernandez."
You'll typically encounter three other types of fields in an improperly or poorly designed database.
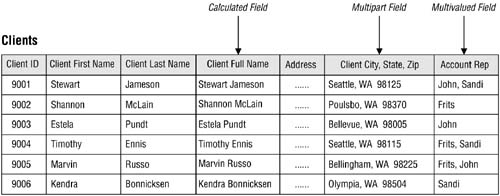
A multipart field (also known as a composite field), which contains two or more distinct items within its value.
A multivalued field, which contains multiple instances of the same type of value.
A calculated field, which contains a concatenated text value or the result of a mathematical expression.
Figure 3.9 shows a table with an example of each of these types of fields.
Figure 3.9. A table containing regular, calculated, multipart, and multivalued fields.
I'll cover calculated, multipart, and multivalued fields in greater detail in Chapter 7.
Record
A record (known as a tuple in relational database theory) represents a unique instance of the subject of a table. It is composed of the entire set of fields in a table, regardless of whether or not the fields contain values. Because of the manner in which a table is defined, each record is identified throughout the database by a unique value in the primary key field of that record.
In Figure 3.9, each record represents a unique client within the table, and the CLIENT ID field is used to identify a given client throughout the database. In turn, each record includes all of the fields within the table, and each field describes some aspect of the client represented by the record. Consider the record for Timothy Ennis, for example. His record represents a unique instance of the table's subject ("Clients") and includes the total collection of fields in the table, treated as a unit. The values of those fields represent relevant facts about Mr. Ennis that are important to someone in the organization.
Records are a key factor in understanding table relationships because you'll need to know how a record in one table relates to other records in another table.
View
A view is a "virtual" table composed of fields from one or more tables in the database; the tables that comprise the view are known as base tables. The relational model refers to a view as "virtual" because it draws data from base tables rather than storing data on its own. In fact, the only information about a view that is stored in the database is its structure. Many major RDBMS programs support views, but some (such as Microsoft Access) refer to them as saved queries. Your specific RDBMS program will determine whether you refer to this object as a query or a view.
Views enable you to see the information in your database from many different aspects, providing you with a great amount of flexibility when you work with your data. You can create views in a variety of ways and they are especially useful when you base them on multiple related tables. In a school scheduling database, for example, you could create a view that consolidates data from the STUDENTS, CLASSES, and CLASS SCHEDULES tables.
Figure 3.10 shows a view called INSTRUMENT ASSIGNMENTS that is composed of fields taken from the STUDENTS, INSTRUMENTS, and STUDENT INSTRUMENTS tables. The view displays data that it draws from all of these tables simultaneously, based on matching values between the STUDENT ID fields in the STUDENTS and STUDENT INSTRUMENTS tables, and the INSTRUMENT ID fields in the INSTRUMENTS and STUDENT INSTRUMENTS tables.
Figure 3.10. An example of a typical view.
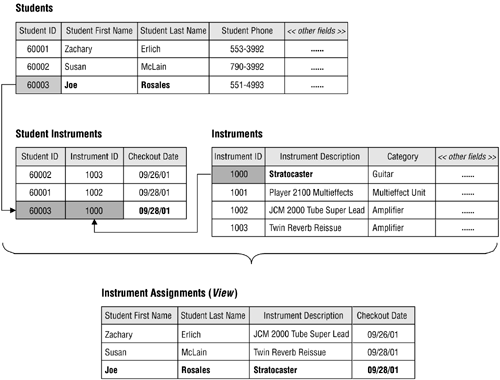
There are three major reasons that views are important.
They allow you to work with data from multiple tables simultaneously. (In order for a view to do this, the tables must have connections, or relationships, to each other.)
They enable you to prevent certain users from viewing or manipulating specific fields within a table or group of tables. This capability can be very advantageous in terms of security.
You can use them to implement data integrity. A view you use for this purpose is known as a validation view.
You'll learn more about designing and using views in Chapter 12.
Note
Although every major database vendor supports the type of view I've described in this section, several vendors are now supporting what is known as an indexed (or materialized) view. An indexed view is different from a "regular" view in that it does store data, and its fields can be indexed to improve the speed at which the RDBMS processes the view's data. A full discussion of indexed views is beyond the scope of this book because it is a vendor-specific implementation issue. However, you should research this topic further if you are working with a client/server or mainframe RDBMS program.
Keys
Keys are special fields that play very specific roles within a table, and the type of key determines its purpose within the table. There are several types of keys a table may contain, but the two most significant ones are the primary key and the foreign key.
A primary key is a field or group of fields that uniquely identifies each record within a table; if a primary key is composed of two or more fields, it is known as a composite primary key. The primary key is absolutely the most important key in the entire table.
A primary key value identifies a specific record throughout the entire database,
The primary key field identifies a given table throughout the entire database.
The primary key enforces table-level integrity and helps establish relationships with other tables in the database. (You'll learn more about relationships in the next section.)
Every table in your database should have a primary key!
The AGENT ID field in Figure 3.11 is a good example of a primary key. It uniquely identifies each agent within the AGENTS table and helps to guarantee table-level integrity by ensuring nonduplicate records. It can also be used to establish relationships between the AGENTS table and other tables in the database, such as the ENTERTAINERS table shown in the example.
Figure 3.11. An example of primary and foreign key fields.
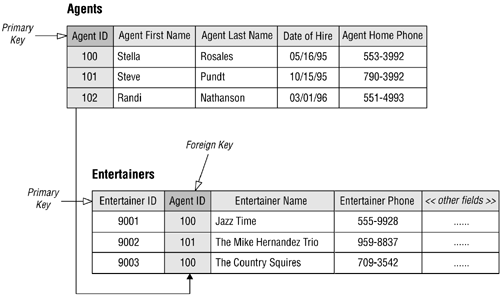
When you determine that two tables bear a relationship to each other, you typically establish the relationship by taking a copy of the primary key from the first table and incorporating it into the structure of the second table, where it becomes a foreign key. The name "foreign key" is derived from the fact that the second table already has a primary key of its own, and the primary key you are introducing from the first table is "foreign" to the second table.
Figure 3.11 also shows a good example of a foreign key. Note that AGENT ID is the primary key of the AGENTS table and a foreign key in the ENTERTAINERS table. AGENT ID assumes this role because the ENTERTAINERS table already has a primary keyENTERTAINER ID. As such, AGENT ID establishes the relationship between both of the tables.
Besides helping to establish relationships between pairs of tables, foreign keys also help implement and ensure relationship-level integrity. This means that the records in both tables will always be properly related because the values of a foreign key must match existing values of the primary key to which it refers. Relationship-level integrity also helps you avoid the dreaded "orphaned" record, a classic example of which is an order record without an associated customer. If you don't know who made the order, you can't process it, and you obviously can't invoice it. That'll throw your quarterly sales off !
Key fields play an important part in a relational database, and you must learn how to create and use them. You'll learn more about primary keys in Chapters 8 and 10.
Index
An index is a structure an RDBMS provides to improve data processing. Your particular RDBMS program will determine how the index works and how you use it. However, an index has absolutely nothing to do with the logical database structure! The only reason I include the term index in this chapter is that people often confuse it with the term key.
Index and key are just two more terms that are widely and frequently misused throughout the database industry and in numerous database-related publications. (Remember my comments on data and information?) You'll always know the difference between the two if you remember that keys are logical structures you use to identify records within a table, and indexes are physical structures you use to optimize data processing.
| Top |








