Refining the Table Structures
Now that you've refined the fields and made certain that each field is sound, you can begin the process of refining the table structures. Your objective in this phase of the design process is to make sure that you've assigned the appropriate fields to each table and that you've properly defined each table's structure. This process will also reveal whether the tables have anomalies that you need to resolve.
A Word About Redundant Data and Duplicate Fields
You've seen the term redundant data used quite often in this chapter. Redundant data was characterized as being unacceptable in many cases, but appropriate in others. In order for you to better understand how to determine when redundant data is acceptable, a definition of the term is in order.
Redundant data is a value that is repeated in a field as a result of the field's participation in relating two tables or as a result of some field or table anomaly. In the first instance, the redundant data is appropriate; by definition, a field used to relate one table to another will contain redundant data. (You'll learn more about this in Chapter 10.) Redundant data is entirely unacceptable in the second instance, however, because it poses problems with data consistency and data integrity; therefore, you should always strive to keep redundant data to an absolute minimum.
A duplicate field is a field that appears in two or more tables for any of these reasons:
It is used to relate a set of tables together.
It indicates multiple occurrences of a particular type of value.
There is a perceived need for supplemental information.
The only instance in which a duplicate field is necessary is when it serves to establish a relationship between two tables; it provides the sole means of associating records in the first table with records in the second table. Duplicate fields are unnecessary in all other cases, and you should avoid them because they introduce needless, redundant data.
As you refine each table structure, you'll assess whether to retain a given duplicate field in the table. If the reason for its existence in the table is valid, then you'll keep it; otherwise, you'll remove it. You'll learn how to deal effectively with both redundant data and unnecessary duplicate fields in the following sections.
Using an Ideal Table to Refine Table Structures
Despite your efforts to refine the fields in a table, the table structure itself may contain anomalies that can produce unnecessary redundant data and make it difficult to work with the data in the table. You can identify a potentially problematic table structure by determining whether it complies with the Elements of the Ideal Table. These elements constitute a set of guidelines you can use to create sound table structures and to spot poorly designed tables easily.
Elements of the Ideal Table
It represents a single subject, which can be an object or event. Yes, I know, I've said this a number of times already. The fact of the matter is that I can't overemphasize this point. As long as you guarantee that each of your tables represents a single subject, you greatly reduce the risk of potential data-integrity problems. This element validates the work you've done during the analysis and interview stages of the database-design process, as well as the work you've just recently performed.
It has a primary key. This is important for two reasons: It uniquely identifies each record within a table, and it plays a key role (no pun intended) in establishing table relationships. Additionally, it has specific characteristics that help to implement and enforce various levels of data integrity. If you fail to assign a primary key to each table, you will eventually have data-integrity problems. Chapter 8 covers primary keys in greater detail.
It does not contain multipart or multivalued fields. Theoretically, you should have resolved these issues when you refined the field structures. Nevertheless, it's still a good idea to review the fields one last time to ensure that you've completely removed each and every one of them.
It does not contain calculated fields. Although you might believe that your current table structures are free of calculated fields, you may have accidentally overlooked one or two calculated fields during the field refinement process. This is a good time to review the table structures once more and make certain you remove those calculated fields you may have missed.
It does not contain unnecessary duplicate fields. (Note that this guideline does not apply to fields used to relate a set of tables together, such as those used in the example in Figure 7.22.) One of the hallmarks of a poorly designed table is the inclusion of duplicate fields from other tables. You might feel compelled to add duplicate fields to a table for one of two reasons: to provide reference information or to indicate multiple occurrences of a particular type of value. Duplicate fields such as these raise various difficulties when you work with the data or attempt to retrieve information from the table.
It contains only an absolute minimum amount of redundant data. Remember that a relational database will never be completely free of redundant data. But you canand shouldmake certain that each table contains as little redundant data as possible.
Resolving Unnecessary Duplicate Fields
Before you make final modifications to the table structures, you must first remove all unnecessary duplicate fields from the database. You can then refine the tables so that they comply with the Elements of the Ideal Table.
Duplicate fields that serve to provide reference information (also known as reference fields) are unnecessary and easy to resolveyou just remove them from the table. Unfortunately, many people believe that a table must contain every field that will appear in the reports they generate from it, so they introduce various duplicate fields into the table as they deem necessary. They assume that the table will then be able to provide all the requisite information for their reports. But they are mistaken, and their action is both unwise and undesirable. Tables containing reference fields exhibit poor design and will have a number of problems, many of which will become increasingly clear as the database-design process unfolds. Reference fields force the user or database application program to ensure that the values in all occurrences of the field are mutually consistent, a process that carries a high risk of error. Figure 7.23 shows an example of a table containing reference fields.
Figure 7.23. Example of a table containing reference fields.
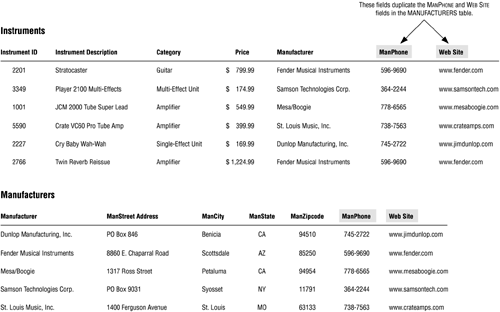
The MANPHONE and WEB SITE fields in the INSTRUMENTS table are reference fields and, by definition, are actually unnecessary duplicate fields. You certainly don't need to include them in this table because they're already part of the MANUFACTURERS table structure; therefore, you can remove them from the INSTRUMENTS table in order to resolve the unnecessary duplication problem. (MANUFACTURER is not a reference field because it currently relates the INSTRUMENTS table to the MANUFACTURERS table.) You'll learn later in Chapter 12 that you can work with fields from the INSTRUMENTS table and the MANUFACTURERS table at the same time by combining them within a view (virtual table). You can then use this view as the basis for compiling any reports you require.
Duplicate fields that serve to indicate multiple occurrences of the same type of value are unnecessary as well. For example, take a look at the version of the STUDENTS table presented in Figure 7.24.
Figure 7.24. A simple example of a table containing unnecessary duplicate fields.

INSTRUMENT 1, INSTRUMENT 2, and INSTRUMENT 3 are duplicate fields that represent multiple occurrences of the same type of value. Their purpose in the table is to enable the music department to keep track of the instruments checked out by a given student. Aside from the difficulties these fields pose in retrieving information about a particular instrument, the fields also limit the number of instruments a student can check out. What happens if several students want to check out more than three instruments?
Does this type of field structure look strangely familiar? It should! It's similar to the one back in Figure 7.18. As you've probably already guessed, it's nothing more than a flattened multivalued field. Mind you, the person who created this table probably didn't have a multivalued field in mind (and neither do most folks who create fields such as these), but that is what it truly is.
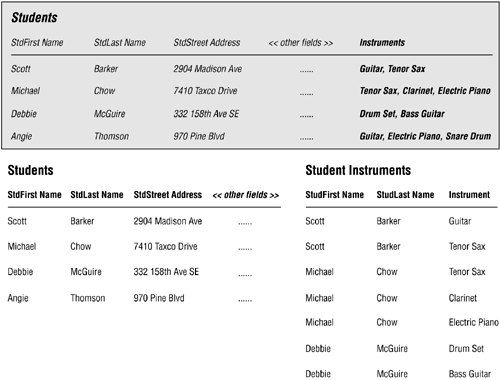
You already know how to deal with these unnecessary duplicate fields because you know how to resolve multivalued fields. You can easily fix the STUDENTS table by first visualizing the INSTRUMENT 1, INSTRUMENT 2, and INSTRUMENT 3 fields as a singular multivalued field, and then resolving it as you would any multivalued field. Figure 7.25 illustrates this process. The shaded version of the STUDENTS table shows how you visualize the instrument fields as a singular multivalued field. You then resolve the multivalued field by applying the three-step process you learned earlier, which yields the revised STUDENTS table and the new STUDENT INSTRUMENTS table. When you're finished, you'll be able to enter any number of instruments for a particular student. It will then be quite easy for you to retrieve information such as the names of the students who have checked out a guitar, a list of the instruments that are currently checked out by a particular student, and the number of students who have checked out an electric piano.
Figure 7.25. Resolving a simple set of unnecessary duplicate fields.
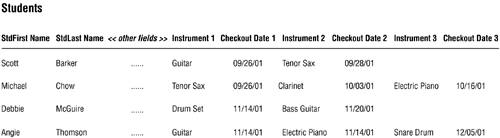
In some instances, a table can contain two or more sets of duplicate fields that represent multiple occurrences of the same type of value. Figure 7.26 shows a slightly different version of the STUDENTS table shown in Figure 7.24; this version contains two sets of duplicate fields. You may be thinking at this very moment, "Why is he saying there are two sets of duplicate fields when I clearly see three?" Contrary to what you may think, INSTRUMENT 1/CHECKOUT DATE 1, for example, does not constitute a set of duplicate fields. Quite the oppositeINSTRUMENT 1/INSTRUMENT 2/INSTRUMENT 3 constitute the first set of duplicate fields, and CHECKOUT DATE 1/CHECKOUT DATE 2/CHECKOUT DATE 3 constitute the second set of duplicate fields.
Figure 7.26. Example of a table with multiple sets of duplicate fields.
You've probably realized that these two sets of duplicate fields are actually two flattened multivalued fields and that you can resolve them in the same manner as in the previous example. The only other issue that you must be concerned with is the distinct one-to-one association between an instrument and a checkout date. This won't be a problem, however, because you've dealt with this type of scenario before. If you visualize one multivalued field called INSTRUMENTS and another called CHECKOUT DATE, you'll see that the overall table structure is quite similar to the one in Figure 7.21. (There's a one-to-one association between the CATEGORIES TAUGHT and MAXIMUM LEVEL TAUGHT fields.)
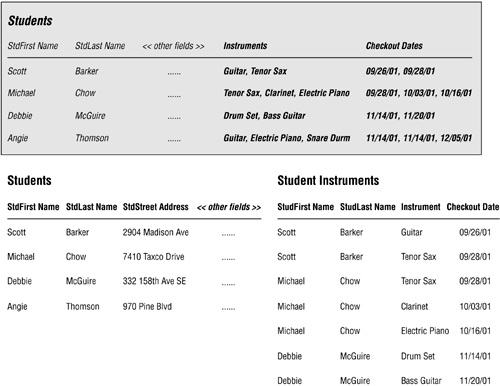
Figure 7.27 illustrates how you can fix this table. As before, the shaded version of the STUDENTS table shows how you visualize the instrument and checkout date fields as singular multivalued fields. You then resolve the multivalued fields by applying the three-step process you learned earlier, yielding the revised STUDENTS table and the new STUDENT INSTRUMENTS table.
Figure 7.27. Resolving the multiple sets of duplicate fields in the STUDENTS table.
Now that you're familiar with the Elements of the Ideal Table, review your table structures and refine them as necessary. When you're in doubt about a particular table, sketch its structure on a piece of paper and load it with sample data. You'll then be able to resolve the anomalies revealed by the data.
Establishing Subset Tables
As you refine the structures of your tables, you may find that some of the fields in a particular table do not always contain values. This situation will not affect your ability to retrieve information from the table, but it can indicate that the table might need further refinement. Consider the structure of the INVENTORY table in Figure 7.28.
Figure 7.28. Structure of an office inventory table.
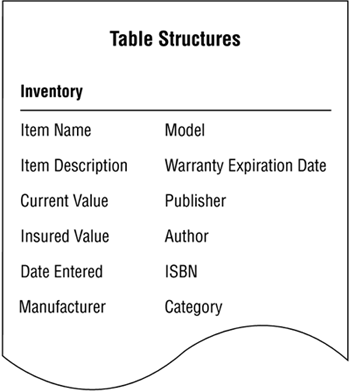
In this scenario, the table contains data about various items in a person's office, such as office furniture, office equipment (computers, faxes, and so forth), and books. It's inevitable that the values of several fields in many of the records will be blank. For example, a book will not have a MANUFACTURER, MODEL, or WARRANTY EXPIRATION DATE, and a fax machine will not have an AUTHOR, PUBLISHER, ISBN, or CATEGORY. This doesn't pose a problem from a physical viewpoint (limited hard-disk space isn't the critical issue it was in years past), but it can pose a perceptual problem. Users (and management, for that matter) get fairly nervous when they see a lot of blank values in a table. Is the data missing? Did someone forget to make entries into these fields? Has someone mistakenly deleted the data? Did the computer accidentally destroy the original values? (Yes, the urban myth, "The computer did it!" still lives on.) The more important question is this: If you were adhering to the Elements of the Ideal Table as you were creating this table, how did you arrive at this particular structure?
Fortunately, this is just another type of structural anomaly that occasionally occurs as you design various tables. Your task now is to learn how to deal with it in an appropriate manner.
The first step is to determine whether the INVENTORY table truly complies with the first element of an ideal table (i.e., "It represents a single subject"). A table that contains a large number of blank values in its fields usuallybut not alwaysrepresents more than one subject. Think about the two sets of fields in question for a moment, and you'll soon realize that they represent characteristics of two distinct aspects of the table's subject. The first set of fields describes equipment inventory, and the second set of fields describes books inventory; furthermore, both types of inventory share common characteristics, such as ITEM NAME, ITEM DESCRIPTION, and CURRENT VALUE. In essence, "Equipment" and "Books" are subjects that are dependent upon the INVENTORY table for their very existence; neither describes a completely distinct object or event. As a result, they are subordinate subjects, and you'll create a subset table for each of them.
Just as a data table represents a distinct subject, a subset table represents a subordinate subject of a particular data table. The subset table contains fields that are germane to the subordinate subject it represents, and it also includes a field (or fields) from the data table that serves to relate the data table to the subset table. It's important to note that a subset table does not contain fields that represent characteristics common to both it and the data table; these fields must remain in the data table.
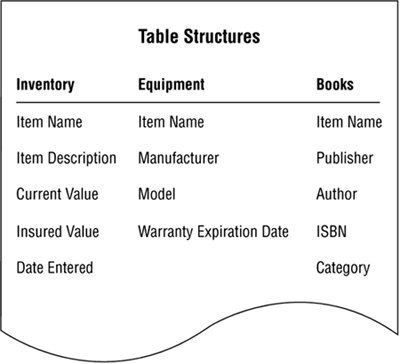
Now that you've determined that the INVENTORY table describes three subjects (it doesn't matter that two of them are subordinate subjects), you must bring it into compliance with the first element of an ideal table by removing the fields in question. You then use the fields as the basis for two new subset tables, one for each subordinate subject. Here are the steps you follow to accomplish these tasks:
Use the MANUFACTURER, MODEL, and WARRANTY EXPIRATION DATE fields to create a new subset table called EQUIPMENT.
Use the PUBLISHER, AUTHOR, ISBN, and CATEGORY fields to create a new subset table called BOOKS.
Add ITEM NAME to both tables; this field will relate each subset table to the data table.
Compose a suitable description for both subset tables and add them to the final table list. Indicate each table's type as "Subset."
Figure 7.29 shows the new subset table structures.
Figure 7.29. The new subset table structures.
Take a moment to review your table structures once more. You may discover that you've created subset tables without knowing it. Tables that have almost identical structures are commonly subset tables; there are usually only a few unique fields that distinguish one table from the other. For example, consider the two partial table structures in Figure 7.30. Each table represents a distinct aspect of the same subject.
Figure 7.30. Previously unidentified subset tables.
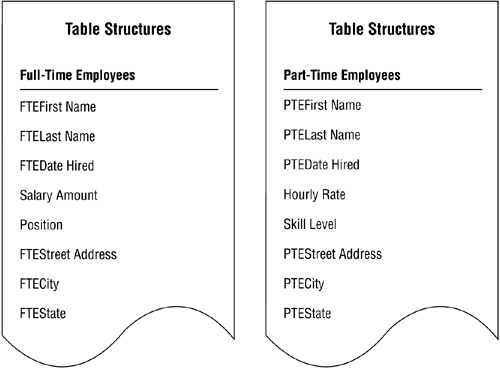
Both of these tables represent employees, but each represents a specific type of employee. Notice, however, that there are generic fields common to both tables: first name, last name, date hired, street address, city, and state. These fields are duplicated unnecessarily, so you'll need to refine the table structures to resolve this problem.
Refining Previously Unidentified Subset Tables
When you identify subset tables such as these, you can refine them using these steps:
Remove all the fields that the subset tables have in common and use them as the basis for a new data table.
Identify what subject the new data table represents, and then give the table an appropriate name.
Make sure that the subset tables represent subordinate subjects of the data table and modify the subset table names as necessary.
Compose a suitable description for the data table and then add it to the final table list. Indicate the table type as "Data."
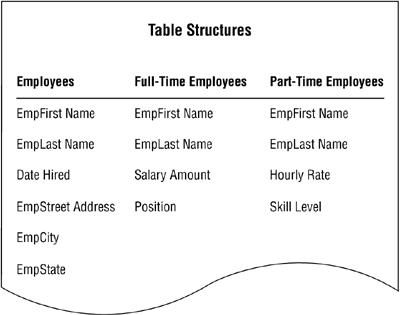
Figure 7.31 shows the results of using these steps on the FULL-TIME EMPLOYEES and PART-TIME EMPLOYEES tables.
Figure 7.31. The results of refining the subset tables.
At this point, all of your table structures should be in pretty good shape. You will need to refine them even further, however, as you learn about primary keys, foreign keys, relationships, and business rules.
CASE STUDY
You're now going to define the preliminary table list for Mike's Bikes. As you know, the first thing you need to do is review the preliminary field list to determine what subjects you can infer from the fields on the list. Figure 7.32 shows a partial sample of that list.
Figure 7.32. The preliminary field list for Mike's Bikes.
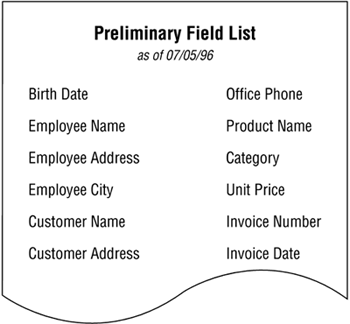
After carefully reviewing the entire preliminary field list, you determine that the fields on the list suggest these subjects: customers, employees, invoices, products, and vendors. You then compile these items into the first version of your preliminary table list.
Now you create a second version of the list by merging the current preliminary table list with the list of subjects you created during the analysis process. Keep the following steps in mind as you merge the two lists together:
Resolve items that are duplicated on both lists. Remember that a single item can appear on both lists yet represent different subjects. When you identify such items, use the appropriate techniques to resolve this problem.
Resolve items that represent the same subject but have different names. You want to ensure that only one table represents a particular subject.
Combine the remaining items together into one list. The combined list becomes the second version of the preliminary table list.
After following these steps, your preliminary table list should look similar to the one shown in Figure 7.33.
Figure 7.33. The second version of the preliminary table list.
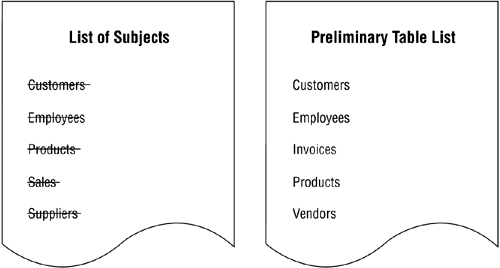
You cross out "Customers," "Employees," and "Products" on the list of subjects because they represent the same subjects as their counterparts on the preliminary table list. The SALES table has no counterpart on the preliminary table list, but it does represent the same subject as "Invoices." "Invoices" is most meaningful to Mike and his staff, however, so you use it on the preliminary table list instead of "Sales." A similar situation exists between "Suppliers" and "Vendors"; Mike selects "Vendors" as the name to appear on the preliminary table list, so you cross out "Suppliers."
Note
Selecting a name that best represents the subject of the table is an arbitrary task. A good rule to follow is to use the name that is most meaningful to everyone in the organization.
Now you'll work toward the final version of the preliminary table list. Use the mission objectives you created at the beginning of the database-design process to determine whether there are subjects you may have overlooked during the previous two procedures. Identify each subject represented in the mission objectives using the subject-identification technique. Once you've identified as many subjects as possible, you can use the steps from the second procedure to crosscheck these subjects against the subjects currently listed on the preliminary table list. When you've completed the review and have resolved any duplicate items, your final version of the preliminary table list is complete.
As it turns out, all of the subjects you've identified from the mission objectives for Mike's Bikes already appear on the preliminary table list. This is good news because it allows you to complete your crosscheck quite easily. Satisfied that you've completed the task thoroughly, you now have the final version of the preliminary table list.
Now that the preliminary table list is complete, you're ready to transform it into a final table list. Keep these steps in mind as you begin this process:
Refine the table names. Use the appropriate guidelines to ensure that each table name is clear, unambiguous, descriptive, and meaningful.
Compose a suitable description for each table. Make certain that the table description explicitly defines the table and states its importance to the organization. Use the pertinent guidelines to create each table description.
Indicate the table's type. Remember that a table can be classified in one of four waysdata, linking, subset, or validation. At this point, all of your tables are data tables.
Figure 7.34 shows a partial example of the final table list for Mike's Bikes.
Figure 7.34. A partial listing of the final table list for Mike's Bikes.
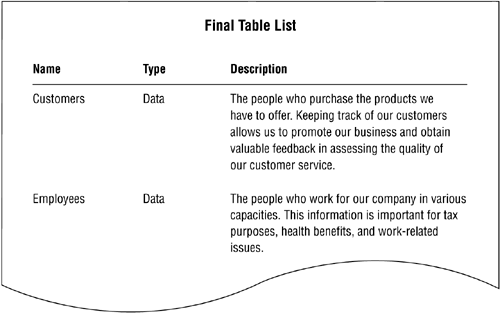
The next order of business is to associate fields from the preliminary field list with each table in the final table list. Make certain you select the fields that best represent characteristics of each table's subject; each field should define or describe a particular aspect of the subject. Figure 7.35 shows a partial example of the table structures for Mike's Bikes.
Figure 7.35. A partial listing of the table structures for Mike's Bikes.
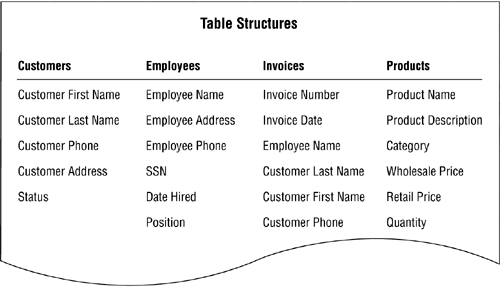
Now you refine the fields. Remember to follow these steps as you work with each field:
Improve the field name. Use the appropriate guidelines to ensure that each field name is as clear, unambiguous, and descriptive as possible.
Determine whether the field complies with the Elements of the Ideal Field. Make certain you check for multipart and multivalued fields. As you learned earlier, they can cause a number of problems within a table.
As you review the fields, you decide to abbreviate some of the field names in the CUSTOMERS, EMPLOYEES, and INVOICES tables, shortening CUSTOMER to CUST and EMPLOYEE to EMP. You also decide that the field name QUANTITY (in the PRODUCTS table) does not completely describe the characteristic it represents, so you change it to QUANTITY ON HAND. The phone fields in the CUSTOMERS and EMPLOYEES tables suffer the same problem, so you change them to CUSTHOME PHONE and EMPHOME PHONE respectively. Furthermore, you change SSN to SOCIAL SECURITY NUMBER so that the field name is absolutely unambiguous.
Further investigation of the fields reveals that almost all of them comply with the Elements of the Ideal Field. The only exceptions are the address fields in the CUSTOMERS and EMPLOYEES tables, and the EMPLOYEE NAME fields in the EMPLOYEES and INVOICES tables. After ascertaining that you can decompose each address field into four individual itemsstreet address, city, state, and zip codeyou transform these items into fields and add them to the CUSTOMERS and EMPLOYEES tables. Similarly, you notice that the EMPLOYEE NAME field represents two itemsfirst name and last nameand you make the appropriate adjustments to that field in the EMPLOYEES and INVOICES tables.
Figure 7.36 shows the result of all the changes you've made to the fields.
Figure 7.36. Refinements to the fields in the table structures.
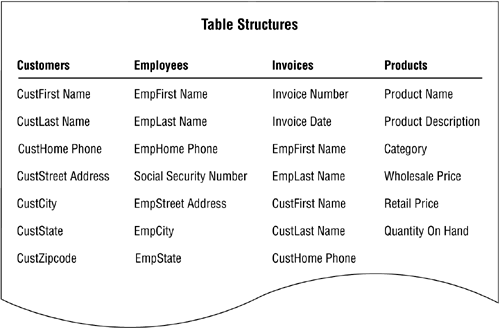
Your final task is to refine the table structures. Make certain that you have assigned the appropriate fields to each table and that you have properly defined each table. Remember to follow these steps as you work with each table:
Resolve unnecessary duplicate fields. When you create new tables as a result of resolving duplicate fields, make sure you properly identify them and add them to the final table list.
Determine whether each table complies with the Elements of the Ideal Table. Make certain you resolve all the anomalies you identify in the fields or within the table structure as a whole.
Establish subset tables as appropriate. Make certain you properly identify these tables and add them to the final table list as well.
As you complete your review of the tables, you determine that all of them conform to the Elements of the Ideal Table with the exception of the INVOICES table. The only problem with this table is that it contains an unnecessary duplicate field: CUSTHOME PHONE. You can remove this field from the table, however, because it provides only reference information.
As you work with the PRODUCTS table, you notice that there are fields you might be able to remove and then use as the basis for a subset table. So you review the table once again. Figure 7.37 shows the PRODUCTS table structure you're currently examining. (This is an expanded version of the table structure shown in Figure 7.36.)
Figure 7.37. The PRODUCTS table structure (expanded version).
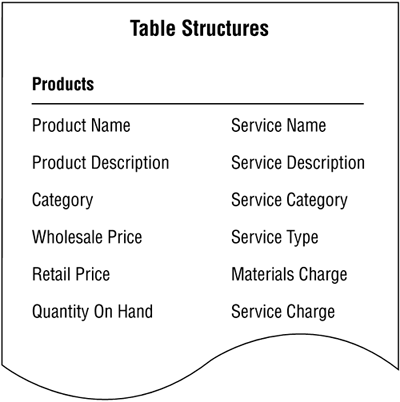
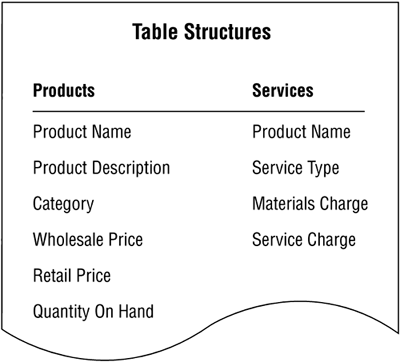
Your assumption proves correct. You determine that certain fields describe a service, and you can construe a service as being a different type of product. A service is similar to a product in that it has a name, description, and category, but it is different inasmuch as it has a type, materials charge, and service charge. With this in mind, you create a new subset table called SERVICES, make the appropriate modifications to the PRODUCTS table, and use the PRODUCT NAME field to relate the two tables to each other. You then add the suitable listing for the SERVICES table to the final table list. Figure 7.38 shows the revised PRODUCTS table and the new SERVICES subset table.
Figure 7.38. The new PRODUCTS and SERVICES tables.
| Top |







