2.3 Indexes
Indexes are less fundamental, functionally, than tables. Indexes are really just a means to reach table rows quickly. They are essential to performance, but not functionally necessary.
2.3.1 B-Tree Indexes
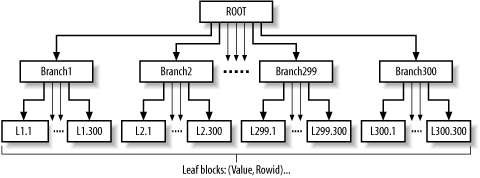
The most common and most important type of index, by far, is the B-tree index, which reflects a tree structure that is balanced (hence the B) to a constant depth from the root to the leaf blocks along every branch. Figure 2-3 shows a three-deep B-tree, likely reflecting an index pointing to 90,000-27,000,000 rows in a table, the typical size range for three-deep B-trees.
Figure 2-3. A three-level B-tree index
Like an index in a book, a database index helps the database quickly find references to some value or range of values that you need from a table. For example, indexing Last_Name in a Persons table allows rapid access to the list of table rows where Last_Name='SMITH' or where Last_Name>='X' AND Last_Name<'Y'. Unlike indexes in a book, however, database indexes are almost effortless to use; the database is responsible for walking through the indexes it chooses to use, to find the rows a query requires, and it usually finds the right indexes to use without being told. Databases don't always make the right choice, however, and the material in this book exists largely to address such problems.
Every index has a natural sort order, usually ascending in the order that is natural to the type of the indexed column. For example, the number 11 falls between 10 and 12, but the character string '11' falls between '1' and '2'. Indexes often cover multiple columns, but you can think of such indexes as having a single sort key made up of the concatenation of the multiple column values, with suitable padding to cause sorting on the second column to begin only after completing the sort on the first column.
Index access always begins at the single root block, which holds up to about 300 ranges of index values covered by data in the table. These ranges usually carry pointers to branch blocks for each range, when the index as a whole covers more than about 300 rows (the actual number depending on block and column sizes, mostly).[3] An index on a table with fewer than 300 rows typically has only the root block, which contains the pointers that lead directly to the indexed rows in the table. Each of these pointers takes the form of a block address and a row number within the block, for each indexed row. In any case, no matter how large the table, you can assume that the root block is perfectly cached, since every use of the index goes through that single block.
[3] I speak here of indexed rows, as opposed to table rows, because not all indexes point to all rows of a table. Most notably, Oracle indexes do not contain entries that point to rows with null values on all the indexed columns, so an index on a mostly null column can be very small, even on a very large table, if few rows have non-null values for that column.
|

Assuming a table has more than about 300 indexed rows, the database follows a pointer in the root block to a branch block that covers the beginning of the range of values you requested in your query. If the table has more than about 90,000 indexed rows, the branch block, in turn, contains subranges with pointers to blocks in the next lower level. Finally (at the first branch level, with a table in the 300-90,000 indexed-row range), the database arrives at a leaf block with an exact value that matches the beginning of the range you want (assuming the range you queried has any rows at all) and a rowid for the first row in the range.
If the condition that drives access to the index potentially points to a range of multiple rows, the database performs an index range scan over the leaf blocks. An index range scan is the operation of reading (usually with logical I/O from cache) an index range over as many leaf blocks as necessary. The leaf blocks consist of value/rowid pairs in a list sorted by indexed value. The database sorts entries that repeat a value according to the order of the rowids, reflecting the natural order in which the database stores rows in the physical table. At the end of each leaf-block list, a pointer identifies the next leaf block, where the sorted list continues. If the table has multiple rows that satisfy the index range condition, the database follows a pointer from the first row to the next index entry in the range (over 99% of the time, the next index entry is within the same index leaf block), and so on, until it reaches the end of the range. Thus, each read of a range of sorted values requires one walk down the index tree, followed by one walk across the sorted leaf-block values.
|
With a ballpark number of 300 entries per index block, you will find about 300 branch blocks on the first level. This is still a small enough number to cache well, so you can assume that reads of these index blocks are logical only, with no physical I/O. At the bottom, leaf level of the index, where the index uses three or more levels, there might be many more than 300 leaf blocks. However, even the leaf level of an index has a block count of roughly n/300, where n is the number of indexed rows, and the database can cache 1,000 or more blocks of an index efficiently, if it uses the index enough to really matter.
When the entire index is too large to cache well, you will see some physical I/O when accessing it. However, keep in mind that indexes generally cover just the entity properties that define the parts of the table that are most frequently accessed. Therefore, a database rarely needs to cache all of a large indexit needs to cache only a small subset of the index blocks that point to interesting rowsso even large indexes usually see excellent cache-hit ratios. The bottom line is this: when you compare alternative execution plans, you can ignore costs of physical I/O to indexes. When physical I/O happens at all, physical I/O to tables will almost always dominate physical I/O to indexes.
2.3.2 Index Costs
Having extra indexes around cannot hurt query performance, as long as you avoid using the wrong indexes. Indexes have their downsides, though. Optimizers choose the wrong indexes more often than you might think, so you might be surprised how many query performance problems are created by adding indexes to a database. Even if you have complete confidence that a new index will never take the place of a better index in a query execution plan, add indexes with caution and restraint.
In an ideal world, the only performance cost of adding indexes would come when you add, delete, or update rows. On quiet tables, the performance cost of indexes is never a problem, but on a busy, growing table, it can be a major cost. Inserts into an index are usually not a problem, especially on Oracle, which handles index-block locking for uncommitted work especially gracefully.
Deletes are more difficult than inserts, because B-trees do not behave reversibly when you add rows and then delete them. An index with heavy deletes ends up with nearly empty blocks that are less efficient to cache and read than the same index, pointing to the same rows, would otherwise be had all those deletes not occurred. Occasional, expensive index rebuilds are necessary to restore indexes that have experienced heavy deletes to full efficiency.
Updates are the most expensive index operation. When an update changes at least one indexed column, the database treats the update as both an insert (of the new value) and a delete (of the old value). This expensive two-part update, which is not necessary in tables, is necessary for indexes because updating index values actually changes where a row belongs in an index structure. Fortunately, indexes on primary keys are almost never updated, given correct database design, and updates of foreign keys are uncommon. The indexes that present the greatest danger to update performance are indexes on non-key columns that have real-world meanings that change with time, such as status columns on entities that frequently change status.
Some indexes exist for reasons that are independent of performancefor example, to enforce uniqueness. The need to enforce uniqueness is usually justification enough for a unique index, and, generally, unique indexes are also selective enough to be safe and useful. However, create nonunique indexes with caution; they are not free, and once you create them it is almost impossible to get rid of them without undue risk to performance, since it is very hard to prove that no important query requires any given index. When solving performance problems, I frequently advise creating new indexes. When I do so, though, I almost always have in mind at least one specific query, which runs often enough to matter and has proven unable to run fast enough without the new index.






