5.3 Interpreting Query Diagrams
Before I go further, take some time just to understand the content of the query diagram, so that you see more than just a confusing, abstract picture when you look at one. Given a few rules of thumb, interpreting a query diagram is simple. You might already be familiar with entity-relationship diagrams. There is a helpful, straightforward mapping between entity-relationship diagrams and the skeletons of query diagrams. Figure 5-6 shows the query skeleton for Example 5-1, alongside the corresponding subset of the entity-relationship diagram.
Figure 5-6. The query skeleton compared to an entity-relationship diagram
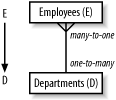
The entity-relationship diagram encodes the database design, which is independent of the query. Therefore, the query skeleton that encodes the same many-to-one relationship (with the arrow pointing to the one) also comes from the database design, not from the query. The query skeleton simply designates which subset of the database design is immediately relevant, so you restrict attention to just that subset encoded in the query skeleton. When the same table appears under multiple aliases, the query diagram also, in a sense, explodes the entity-relationship diagram, showing multiple joins to the same table as if they were joins to clones of that table; this clarifies the tuning problem these multiple joins involve.
With join ratios on the query skeleton, you encode quantitative data about the actual data, in place of the qualitative many indications in the entity-relationship diagram. With the join ratios, you say, on average, how many for many-to-one relationships (with the detail join ratio) and how-often-zero with the master join ratio, when you find many-to-zero-or-one relationships. This too is a function of the underlying data, though not of the database design, and it is independent of the query. These join ratios can vary across multiple database instances that run the same application with different detailed data, but within an instance, the join ratios are fixed across all queries that perform the same joins.
|

Only when you add filter ratios do you really pick up data that is specific to a given query (combined with data-distribution data), because filter conditions come from the query, not from the underlying data. This data shows the relative size of each subset of each table the query requires.
Query diagrams for correctly written queries (as I will show later) almost always have a single detail table at the top of the tree, with arrows pointing down to master (or lookup) tables below and further arrows (potentially) branching down from those. When you find this normal form for a query diagram, the query turns out to have a simple, natural interpretation:
A query is a question asked about the detail entities that map to that top detail table, with one or more joins to master tables below to find further data about those entities stored elsewhere for correct normalization.
For example, a query joining Employees and Departments is really just a question about employees, where the database must go to the Departments table for employee information, like Department_Name, that you store in the Departments table for correct normalization.
|
Questions about business entities that are important enough to have tables are natural in a business application, and these questions frequently require several levels of joins to find inherited data stored in master tables. Questions about strange, unnatural combinations of entities are not natural to a business, and when you examine query diagrams that fail to match the normal form, you will frequently find that these return useless results, results other than what the application requires, in at least some corner cases.
Following are the rules for query diagrams that match the normal form. The queries behind these normal-form diagrams are easy to interpret as sensible business questions about a single set of entities that map to the top table:
The query maps to one tree.
The tree has one root, exactly one table with no join to its primary key. All nodes other than the root node have a single downward-pointing arrow linking them to a detail node above, but any node can be at the top end of any number of downward-pointing arrows.
All joins have downward-pointing arrows (joins that are unique on at least one end).
Outer joins are unfiltered, pointing down, with only outer joins below outer joins.
The question that the query answers is basically a question about the entity represented at the top (root) of the tree (or about aggregations of that entity).
The other tables just provide reference data stored elsewhere for normalization.






