2.5 Single-Table Access Paths
The most basic query requests some subset of a single table. Such queries are rarely interesting from a tuning perspective, but even the most complex query, joining many tables, starts with a single driving table. You should choose the access path to the driving table in a multitable query, just as you would for the single-table query that would result if you stripped the multitable query down, removing the joins, the nondriving tables, and the conditions on the nondriving tables. Every query optimization problem therefore includes the choice of an optimum single-table access path to the driving table. The table implementations and table-access methods differ slightly between the database vendors. To be both accurate and concrete, in this section I will describe table access on Oracle for illustration purposes, but the differences between Oracle and other database brands are not important to SQL tuning.
2.5.1 Full Table Scans
The most basic access path to a table is the full table scan, reading the whole table without an index. Figure 2-4 illustrates this method, as applied to a typical Oracle table.
Figure 2-4. A full table scan
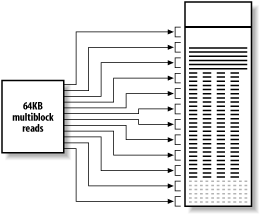
Oracle recognizes that, since it is going to read the entire table, it ought to request physical I/O in parts larger than the block sizein this case, reading 64KB at a time. This results in fewer but larger physical reads, which are faster than many small physical reads covering the same blocks. Not all database vendors follow this method, but it turns out to matter less that you might expect, because disk subsystems and operating systems usually read larger segments, even when the database requests a single block. The database might issue many small read requests, but these translate, in the lower system layers, into a few large read requests, with many smaller requests satisfied out of the disk subsystem cache. The reads continue from the first block to the high-water mark, including empty blocks along the way. Caching only allows the database to avoid a physical multiblock I/O when every block in the 64KB multiblock set of blocks is already in cache. The database reads the blocks of small to medium-sized tables into cache in the usual way, and they expire in the usual few minutes if no other query touches them. Caching entire small or medium-sized tables is often useful, and they end up remaining in cache if the database sees frequent full table scans of such tables.
Large tables present a danger to the caching strategy: the average block in a large table is unlikely to be needed often. If the database followed the usual caching strategy, a large table scan could flush most of the more interesting blocks (from indexes and other tables) out of the cache, harming the performance of most other queries. Fortunately, this is not usually a problem, because blocks from a large full table scan generally go straight to the tail of the cache, where they stay only long enough to satisfy the ongoing query, usually getting replaced by the next group of blocks from the same scan. (This behavior of large full table scans is one of the exceptions to the LRU caching behavior I described earlier.)
2.5.2 Indexed Table Access
The most important costs of a full table scan usually come in the CPU: the cost of examining every block below the high-water mark and the cost of examining every row within those blocks.
Unless you are reading a tiny table (in which case, any access method is likely fine) or reading a large fraction of a larger table, you should ensure that your queries reach the rows you need through an index. Figure 2-5 illustrates an index-based table-access method.
Figure 2-5. Indexed table access
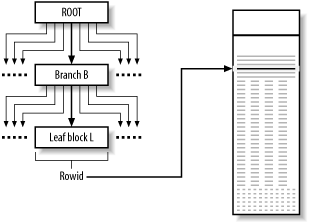
The database begins with some indexed value that defines the beginning of a range of indexed values that meet some query criteria. Starting at the root block, it finds ranges and subranges that lead it down the index tree to the leaf block or blocks that store indexed values that satisfy the query criteria. The database finds the rowids that go with these values and follows them to the precise table blocks, and rows within those blocks, that satisfy the query.
Let's compare the indexed and full table scan access methods with a concrete example. Figure 2-6 shows two paths to read five rows, shown in black, from a 40-block table, which would typically contain around 3,200 rows.
Figure 2-6. Indexed access versus a full table scan
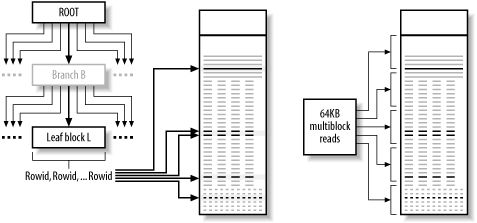
In this example, the table is too small for its index to likely have more than two levels, so the database goes straight from the index root block to the leaf block that holds the start of the five-row range that the query requires. (The middle branch level, nonexistent for such a mid-sized table, is shown in gray.) Probably, the database finds all five index entries in the same leaf block, but it might need to hop to the next leaf block to complete the range if the range started right at the block boundary. Armed with the five rowids, the database goes to the table blocks that hold the five rows. In one case in the example, the database performs two sequential logical I/Os to the same table block, because the rows happen to be close together, but the second logical I/O will surely be cached. (This is an example of the benefit of interesting rows that happen to cluster together in a physical table.)
In the full-table-scan alternative, if the table blocks are not in cache to begin with, the database performs five 64KB reads, covering the whole table up to the high-water mark. Then, in CPU, the database steps through all 40 blocks and all 3,200 rows, discarding all but the 5 rows that match the query condition. If the database had no cache and you cared only about the time to move read heads to perform physical I/O, you would count seven physical I/O operations for the indexed plan and five for the full table scan and choose the full table scan. However, a small table and a smaller index, such as these, are likely completely cached, and 7 logical I/Os, which are to individual table blocks, are cheaper than 40 logical I/Os, even for a full table scan. Apart from logical-I/O costs, the indexed plan avoids CPU costs of looking at over 3,000 rows you do not need.
Both plans, you might suspect, would be fast enough that the difference would not matter,[4] since efficiency against small tables is not that important in single-table reads. Expanding this example to larger-sized tables, though, the questions become more interesting, mixing physical and logical I/O with runtime differences that are long enough to matter.
[4] I am not trying to waste your time with an unimportant example. The difference would matter if I scaled the example up to larger tables and indexes, but such an example would be impossible to illustrate in the detail shown in Figure 2-6. I use this smaller example to get the general point across.
2.5.3 Choosing Between a Full Table Scan and Indexed Access
A superficial analysis often favors full table scans. However, a more careful analysis requires you to take into account several considerations that commonly make indexed reads more favorable than they appear superficially:
Index reads are almost always cached.
Table blocks reached by an index tend to be hotter and are more likely to be cached, because indexed reads are specific to rows you (and others, too, probably) really want, while full table scans treat all rows equally.
A single block is more likely to be cached than a multiblock group, so the effective cache-hit ratio on a table is better for an indexed read. For example, if a randomly scattered half of the blocks in a table are cached, the hit ratio for single-block reads to the table is 50%, but the probability of finding all eight blocks of a multiblock read already cached is just 0.5 to the eighth power, or about 0.4%. To reach a 50% effective hit ratio for eight-block reads, you would need a 91.7% hit ratio on randomly cached individual blocks.
Disk subsystems usually make single-block reads effectively multiblock, converting nearby single-block reads into virtual I/O, so the seeming advantage of multiblock reads for full table scans is less than it would seem.
Indexed reads examine only a small part of each block, the rows you want, instead of every row in the block, saving CPU time.
Indexed reads usually scale better as a table grows, giving stable performance, whereas a full table scan becomes steadily worse, even while it might start out a little better than the indexed plan.
The choice to favor indexed access or a full table scan depends on the fraction of the table that the single-table query will read. The database's optimizer will make this choice for you, but not always correctly. If SQL is slow enough to merit tuning, you need to decide for yourself. Here are some general fraction-read ranges to use in choosing your best strategy:
- >20% of the rows
-
Favor full table scans.
- <0.5% of the rows
-
Favor indexed access.
- 0.5%-20% of the rows
-
It depends.
The 0.5%-20% range is awkward to handle. Conditions should especially favor indexed access for you to prefer an index at the 20% end of this range. Likewise, don't consider a full table scan at the 0.5% end of the range unless conditions strongly favor a table scan. Here are some factors pertaining to particular queries that tend to favor indexed access toward the higher end of the 0.5%-20% range:
The table is well-clustered on the indexed column, resulting in self-caching over the range. Multiple logical I/Os will hit the same blocks, and the later reads of those blocks will likely remain in cache after the earlier reads put them there (if necessary).
The query accesses hotter-than-average rows, resulting in better caching over the indexed range than the full table scan will see over the whole table.
The query goes in on one value only, reaching rows in rowid order. Where you have exact equality conditions on the fully indexed key, reading rowids for that single key value, the index scan returns those rowids in sorted order. Where the database requires physical I/O, this results in an access pattern much like the full table scan, with the read head moving smoothly from the beginning of the range to the end. Since close-together rows get read sequentially, self-caching is particularly likely, both in the database's cache and in the disk I/O subsystem's cache, when that subsystem does read-ahead.
On the other hand, if you access a range of values, such as Retirement_Date BETWEEN '2002/01/01' and '2003/01/01', you will find a whole series of sorted rowid lists for each date in that range. The read-head movement will look much more random and therefore will be less efficient. Self-caching might not even work in this case if the runtime of the query exceeds the life of the blocks in the cache. Even if you drive off an equality, you can get this less efficient alternative if you have a multicolumn index. For example, Last_Name='Smith' is really a range condition on an index of (Last_Name, First_Name), since this full pair has many values that satisfy the single-column condition.
The precise formulas that control the tradeoff between full table-scan performance and range-scan performance are complex and not very useful, because you'd only be able to guess at the inputs (such as the relative hit ratios between blocks reached by the range scan and other table blocks). All this sounds hideously complex, I know, if you happen to be in that awkward 0.5%-20% range, but, in practice, the problem of handling this middle range turns out to be pretty simple:
If a table is big enough for the difference between a full table scan and indexed table access to matter, you better have a condition that is selective enough to use an index; otherwise, you are likely returning more rows than are useful! I will later describe in more detail why few well-designed queries need to return a significant fraction (even 1%) of a large table. Real-world applications exist mostly to give end users convenient access to data. When end users work with data online, they find it inconvenient to handle large data volumes. End users are somewhat more tolerant of large data volumes in reports, but even then a report that provides more data than an end user can digest is not well designed. In Chapter 10, I will discuss at length fixing queries that return far too many rows.
If you're in doubt about whether to use a full table scan or indexed access, just time both alternatives; trial and error works fine when you have only a couple of choices. Keep in mind, though, that whichever alternative you test first will have an unfair disadvantage if you run the experiments close together, since the second experiment will find blocks cached by the first experiment. I usually run each alternative twice, in close succession, and use the second runtime for each, which generally finds perfect caching. If the runtimes come out close, I might repeat experiments 10 minutes or more apart to measure more realistic physical I/O costs, repeating the first experiment 10 minutes after the second, to observe for reproducibility.
Do not look for small improvements. If the two alternatives are close to the same, just stick with the execution plan you already have. Changing a single statement to squeeze a few percent improvement is not likely worth the effort. You should usually look for twofold or better improvements in runtimes when tuningthese are possible surprisingly oftenwhen the performance is slow enough for such improvements to matter.






