2.7 Joins
Single-table queries quickly pale as interesting tuning problems. Choices are few enough that even trial and error will quickly lead you to the best execution plan. Multitable queries yield much more interesting problems. To tune multitable queries, you need to understand the different join types and the tradeoffs between the different join execution methods.
2.7.1 Join Types
Let's begin by trying to understand clearly what a multitable query means. First, consider how databases interpret joins, the operations that combine rows from multiple tables into the result a query demands. Let's begin with the simplest imaginable multitable query:
SELECT ... FROM Orders, Order_Details;
With no WHERE clause at all, the database has no instructions on how to combine rows from these two large tables, and it does the logically simplest thing: it returns every possible combination of rows from the tables. If you had 1,000,000 orders and 5,000,000 order details, you would get (if you could wait long enough) 5,000,000,000,000 rows back from the query! This is the rarely used and even more rarely useful Cartesian join. The result, every combination of elements from two or more sets, is known as the Cartesian product. From a business perspective, you would have no interest in combining data from orders and order details that had no relationship to each other. When you find Cartesian joins, they are almost always a mistake.
|

2.7.1.1 Inner joins
Any given order-processing application would surely need details pertaining to given orders, so you aren't too likely to see a Cartesian join. Instead, you would more likely see a join condition that tells the database how the tables relate:
SELECT ... FROM Orders O, Order_Details D WHERE O.Order_ID=D.Order_ID;
Or, shown in the newer-style notation:
SELECT ... FROM Orders O
INNER JOIN Order_Details D ON O.Order_ID=D.Order_ID;
Logically, you can still think of this as a Cartesian product with a filtered result: "Give me all the combinations of orders and order details, but discard those combinations that fail to share the same order ID." Such a join is referred to as an inner join. Even in the worst cases, databases virtually always come up with a better way to find the requested rows than this brute-force method of Cartesian product first, followed by discards based on unmet join conditions. This is fortunate indeed, since a many-way Cartesian join between several large tables could take years or even eons to complete. Most joins, like the one shown, consist of an equality between a foreign key in some detail table matched to a primary (unique) key in some master table, but any condition at all that mentions two or (rarely) more tables is a join condition.
From a procedural perspective, the database has several choices for how best to join the tables in the preceding queries:
Start with the master table and find the matching details.
Start with the detail table and look up the matching master rows.
Go to both sets of rows independently (but not with a Cartesian product) and somehow merge those rows that match up on the joined column values.
While they yield identical functional results, these alternatives often yield radically different performance, so this book will explain at length how to choose the best alternative.
2.7.1.2 Outer joins
A common alternative to the inner join is the outer join. An outer join is easiest to describe in procedural terms: start with rows from a driving table and find matching rows, where possible, from an outer-joined table, but create an artificial all-nulls matching row from the outer-joined table whenever the database finds no physical matching row. For example, consider the old-style Oracle query:
SELECT ..., D.Department_Name FROM Employees E, Departments D
WHERE E.Department_ID=D.Department_ID(+);
In the newer style notation, on any database, you query the same result with:
SELECT ..., D.Department_Name
FROM Employees E
LEFT OUTER JOIN Departments D
ON E.Department_ID=D.Department_ID;
These queries return data about all employees, including data about their departments. However, when employees have no matching department, the query returns the employee data anyway, filling in inapplicable selected fields, such as D.Department_Name, with nulls in the returned result. From the perspective of tuning, the main implication of an outer join is that it eliminates a path to the data that drives from the outer-joined table to the other table. For the example, the database cannot start from the Departments table and find the matching rows in the Employees table, since the database needs data for all employees, not just the ones with matching departments. Later, I will show that this restriction on outer joins, limiting the join order, is not normally important, because you would not normally want to join in the forbidden order.
2.7.2 Join Execution Methods
The join types determine which results a query requires but do not specify how a database should execute those queries. When tuning SQL, you usually take as a given which results a query requires, but you should control the execution method to force good performance. To choose execution methods well, you need to understand how they work.
2.7.2.1 Nested-loops joins
The simplest method of performing an efficient join between two or more tables is the nested-loops join, illustrated in Figure 2-7.
Figure 2-7. Nested-loops joins
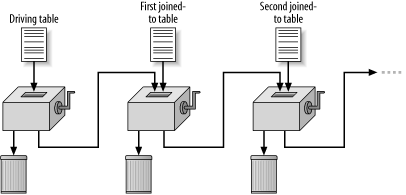
The query execution begins with what amounts to a single-table query of the driving table (the first table the database reads), using only the conditions that refer solely to that table. Think of the leftmost box in Figure 2-7, with the attached crank, as a machine to perform this single-table query. It separates uninteresting rows (destined for the wastebasket at lower left) from interesting rows (rows that satisfy the single-table query conditions) from the driving table. Since the query is a join, the database does not stop here. Instead, it passes the result rows from that first box to the next box. The job of the second box is to take rows from the first box, one at a time, find matching rows from the first joined-to table, then again discard rows that do not meet query conditions on tables so far touched, while passing on rows that meet these conditions. The database usually performs this matching step in a nested-loops join by indexed lookups on the join key, repeated for each row from the driving table.
When the join is an inner join, the database discards rows from the earlier step that fail to find matches in the joined-to table. When the join is an outer join, the database fills in joined-to table values with nulls when it fails to find a match, retaining all rows from the earlier step. This process continues with further boxes to join each of the rest of the tables in the same way until the query is finished, leaving a fully joined result that satisfies all query conditions and joins.
Internally, the database implements this execution plan as a nested series of loopsthe outermost loop reads rows off the driving table, the next loop finds matching rows in the first joined table, and so onwhich is why these are called nested-loops joins. Each point in the process needs to know only where it is at that moment and the contents of the single result row it is building, so this process requires little memory to execute and no scratch space on disk. This is one of the reasons that nested-loops plans are robust: they can deliver huge result sets from huge tables without ever running out of memory or disk scratch space, as long as you can wait long enough for the result. As long as you choose the right join order, nested loops work well for most sensible business queries. They either deliver the best performance of all join methods, or they are close enough to the best performance that the robustness advantage of this join method weighs in its favor, in spite of a minor performance disadvantage.
|
2.7.2.2 Hash joins
Sometimes, the database should access the joined tables independently and then match rows where it can and discard unmatchable rows. The database has two ways to do this: hash joins, which I discuss in this section, and sort-merge joins, which I discuss next. Figure 2-8 illustrates a hash join.
Figure 2-8. A hash join
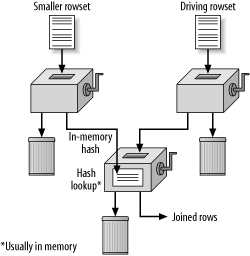
In Figure 2-8, each of the top two boxes with cranks acts like an independently optimized single-table query. Based on table and index statistics, the cost-based optimizer[6] estimates which of these two independent tables will return fewer rows after discarding filtered rows. It chooses to hash the complete result from that single-table query. In other words, it performs some randomizing mathematical function on the join key and uses the result of that function to assign each row to a hash bucket. The ideal hash algorithm spreads the rows fairly evenly between a number of buckets approximating the number of rows.
[6] Oracle's rule-based optimizer will never choose a hash join, but its cost-based optimizer often will. The other database vendors do not offer rule-based optimizers.
Since the hash buckets are based on the smaller result set, you can hope those hash buckets fit entirely in memory, but, if necessary, the database temporarily dedicates scratch disk space to hold the buckets. It then executes the larger query (as shown in the upper-right box in Figure 2-8), returning the driving rowset. As each row exits this step, the database executes the same hash function in its join key and uses the hash-function result to go directly to the corresponding hash bucket for the other rowset. When it reaches the right hash bucket, the database searches the tiny list of rows in that bucket to find matches.
Note that there may not be any matches. When the database finds a match (illustrated in the lower-middle box with a crank), it returns the result immediately or sends the result on to the next join, if any. When the database fails to find a match, the database discards that driving row.
For the driving rowset, a hash join looks much like a nested-loops join; both require that the database hold just the current row in memory as it makes a single pass through the rowset. For the smaller, prehashed rowset, however, the hash join approach is less robust if the prehashed rowset turns out to be much larger than expected. A large prehashed rowset could require unexpected disk scratch space, performing poorly and possibly even running out of space. When you are fully confident that the smaller rowset is and always will be small enough to fit in memory, you should sometimes favor the hash join over a nested-loops join.
2.7.2.3 Sort-merge joins
The sort-merge join, shown in Figure 2-9, also reads the two tables independently, but, instead of matching rows by hashing, it presorts both rowsets on the join key and merges the sorted lists. In the simplest implementation, you can imagine listing the rowsets side-by-side, sorted by the join keys. The database alternately walks down the two lists, in a single pass down each list, comparing top rows, discarding rows that fall earlier in the sort order than the top of the other list, and returning matching rows. Once the two lists are sorted, the matching process is fast, but presorting both lists is expensive and nonrobust, unless you can guarantee that both rowsets are small enough to fit well within memory.
Figure 2-9. A sort-merge join
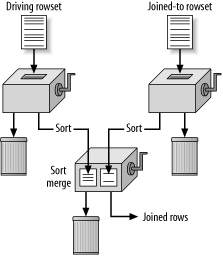
When you compare a sort-merge join with a nested-loops alternative, the sort-merge join has roughly the same potential advantages that hash joins sometimes have. However, when you compare a sort-merge join with a hash join, the hash join has all the advantages: it avoids placing the larger rowset into memory or scratch disk space, with essentially no downside cost. Therefore, when you have a choice between a sort-merge join and a hash join, never choose a sort-merge join.
2.7.2.4 Join methods summary
In summary, you should usually choose nested loops for both performance and robustness. You will occasionally benefit by choosing hash joins, when independent access of the two tables saves significantly on performance while carrying a small enough robustness risk. Never choose sort-merge joins, unless you would prefer a hash join but find that method unavailable (for example, as with Oracle's rule-based optimizer). In later chapters, I will treat nested-loops joins as the default choice. The rules that cover when you can benefit by overriding that default are complex and depend on the material in the later chapters. The main purpose of this section was to explain the internal database operations behind that later discussion.






