Introducing InterBase
Introducing InterBase
Although it has a limited market share, InterBase is a powerful RDBMS. In this section, I'll introduce the key technical features of InterBase without getting into too much detail (because this is a book about Delphi programming). Unfortunately, little is currently published about InterBase. Most of the available material is either in the documentation that accompanies the product or on a few websites devoted to it (your starting points for a search can be www.borland.com/interbase and www.ibphoenix.com).
InterBase was built from the beginning with a modern and robust architecture. Its original author, Jim Starkey, invented an architecture for handling concurrency and transactions without imposing physical locks on portions of the tables, something other well-known database servers can barely do even today. The InterBase architecture is called Multi-Generational Architecture (MGA); it handles concurrent access to the same data by multiple users, who can modify records without affecting what other concurrent users see in the database.
This approach naturally maps to the Repeatable Read transaction isolation mode, in which a user within a transaction keeps seeing the same data regardless of changes made and committed by other users. Technically, the server handles this situation by maintaining a different version of each accessed record for each open transaction. Even though this approach (also called versioning) can lead to larger memory consumption, it avoids most physical locks on the tables and makes the system much more robust in case of a crash. MGA also pushes toward a clear programming model—Repeatable Read—which other well-known SQL servers don't support without losing most of their performance.
In addition to the MGA at the heart of InterBase, the server has many other technical advantages:
-
A limited footprint, which makes InterBase the ideal candidate for running directly on client computers, including portables. The disk space required by InterBase for a minimal installation is well below 10 MB, and its memory requirements are also incredibly limited.
-
Good performance on large amounts of data.
-
Availability on many different platforms (including 32-bit Windows, Solaris, and Linux), with totally compatible versions. Thus the server is scalable from very small to huge systems without notable differences.
-
A very good track record, because InterBase has been in use for 15 years with few problems.
-
A language complaint with the ANSI SQL standard.
-
Advanced programming capabilities, including positional triggers, selectable stored procedures, updateable views, exceptions, events, generators, and more.
-
Simple installation and management, with limited administrative headaches.
Jim Starkey wrote InterBase for his Groton Database Systems company (hence the .gds extension still used for InterBase files). The company was later bought by Ashton-Tate, which was then acquired by Borland. Borland handled InterBase directly for a while and then created an InterBase subsidiary, which was later re-absorbed into the parent company.
Beginning with Delphi 1, an evaluation copy of InterBase has been distributed with the development tool, spreading the database server among developers. Although it doesn't have a large piece of the RDBMS market, which is dominated by a handful of players, InterBase has been chosen by a few relevant organizations, from Ericsson to the U.S. Department of Defense, from stock exchanges to home banking systems.
More recent events include the announcement of InterBase 6 as an open-source database (December 1999), the effective release of source code to the community (July 2000), and the release of the officially certified version of InterBase 6 by Borland (March 2001). Between these events came announcements of the spin-off of a separate company to run the consulting and support business in addition to the open-source database. A group of former InterBase developers and managers (who had left Borland) formed IBPhoenix (www.ibphoenix.com) with the plan of supporting InterBase users.
At the same time, independent groups of InterBase experts started the Firebird open-source project to further extend InterBase. The project is hosted on SourceForge at the address sourceforge.net/projects/ firebird/. For some time, SourceForge also hosted a Borland open-source project, but later the company announced it would continue to support only its proprietary version, dropping its open-source effort. So, the picture is now clearer. If you want a version with a traditional license (costing a fraction of most competing professional SQL servers), stick with Borland; but if you prefer an open-source, totally free model, go with the Firebird project (and eventually buy professional support from IBPhoenix).
Using IBConsole
In past versions of InterBase, you could use two primary tools to interact directly with the program: the Server Manager application, which could be used to administer both a local and a remote server; and Windows Interactive SQL (WISQL). Version 6 includes a much more powerful front-end application, called IBConsole. This full-fledged Windows program (built with Delphi) allows you to administer, configure, test, and query an InterBase server, whether local or remote.
IBConsole is a simple and complete system for managing InterBase servers and their databases. You can use it to look into the details of the database structure, modify it, query the data (which can be useful to develop the queries you want to embed in your program), back up and restore the database, and perform any other administrative tasks.
As you can see in Figure 14.1, IBConsole allows you to manage multiple servers and databases, all listed in a single configuration tree. You can ask for general information about the database and list its entities (tables, domains, stored procedures, triggers, and everything else), accessing the details of each. You can also create new databases and configure them, back up the files, update the definitions, check what's going on and who is currently connected, and so on.
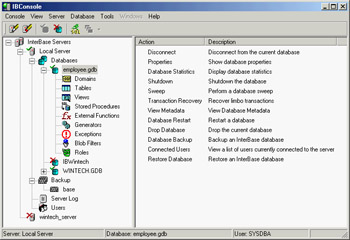 Figure 14.1: IBConsole lets you manage, from a single computer, InterBase databases hosted by multiple servers.
Figure 14.1: IBConsole lets you manage, from a single computer, InterBase databases hosted by multiple servers.
The IBConsole application allows you to open multiple windows to look at detailed information, such as the tables window shown in Figure 14.2. In this window, you can see lists of the key properties of each table (columns, triggers, constraints, and indexes), see the raw metadata (the SQL definition of the table), access permissions, look at the data, modify the data, and study the table's dependencies. Similar windows are available for each of the other entities you can define in a database.
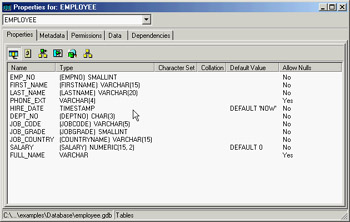
Figure 14.2: IBConsole can open separate windows to show you the details of each entity—in this case, a table.
IBConsole embeds an improved version of the original Windows Interactive SQL application (see Figure 14.3). You can type a SQL statement in the upper portion of the window (without any help from the tool, unfortunately) and then execute the SQL query. As a result, you'll see the data, but also the access plan used by the database (which an expert can use to determine the efficiency of the query) and statistics about the operation performed by the server.
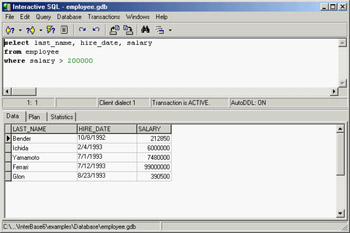
Figure 14.3: IBConsole's Interactive SQL window lets you try in advance the queries you plan to include in your Delphi programs.
This has been a minimal description of IBConsole, which is a powerful tool (and the only one Borland includes with the server other than command-line tools). IBConsole is not the most complete tool in its category, though. Quite a few third-party InterBase management applications are more powerful, although they are not all stable or user-friendly. Some InterBase tools are shareware programs, and others are free. Two examples out of many are InterBase Workbench (www.upscene.com) and IB_WISQL (done with and part of InterBase Objects, www.ibobjects.com).
InterBase Server-Side Programming
At the beginning of this chapter, I underlined the fact that one of the objectives of client/ server programming—and one of its problems—is the division of the workload between the computers involved. When you activate SQL statements from the client, the burden falls on the server to do most of the work. However, you should try to use select statements that return a large result set, to avoid jamming the network.
In addition to accepting DDL (Data Definition Language) and DML (Data Manipulation Language), most RDBMS servers allow you to create routines directly on the server using the standard SQL commands plus their own server-specific extensions (which generally are not portable). These routines typically come in two forms: stored procedures and triggers.
Stored Procedures
Stored procedures are like the global functions of a Delphi unit and must be explicitly called by the client side. Stored procedures are generally used to define routines for data maintenance, to group sequences of operations you need in different circumstances, or to hold complex select statements.
Like Delphi procedures, stored procedures can have one or more typed parameters. Unlike Delphi procedures, they can have more than one return value. As an alternative to returning a value, a stored procedure can also return a result set—the result of an internal select statement or a custom fabricated one.
The following is a stored procedure written for InterBase; it receives a date as input and computes the highest salary among the employees hired on that date:
create procedure MaxSalOfTheDay (ofday date) returns (maxsal decimal(8,2)) as begin select max(salary) from employee where hiredate = :ofday into :maxsal; end
Notice the use of the into clause, which tells the server to store the result of the select statement in the maxsal return value. To modify or delete a stored procedure, you can later use the alter procedure and drop procedure commands.
Looking at this stored procedure, you might wonder what its advantage is compared to the execution of a similar query activated from the client. The difference between the two approaches is not in the result you obtain but in its speed. A stored procedure is compiled on the server in an intermediate and faster notation when it is created, and the server determines at that time the strategy it will use to access the data. By contrast, a query is compiled every time the request is sent to the server. For this reason, a stored procedure can replace a very complex query, provided it doesn't change too often.
From Delphi, you can activate a stored procedure with the following SQL code:
select *
from MaxSalOfTheDay ('01/01/2003')
Triggers (and Generators)
Triggers behave more or less like Delphi events and are automatically activated when a given event occurs. Triggers can have specific code or call stored procedures; in both cases, the execution is done completely on the server. Triggers are used to keep data consistent, checking new data in more complex ways than a check constraint allows, and to automate the side effects of some input operations (such as creating a log of previous salary changes when the current salary is modified).
Triggers can be fired by the three basic data update operations: insert, update, and delete. When you create a trigger, you indicate whether it should fire before or after one of these three actions.
As an example of a trigger, you can use a generator to create a unique index in a table. Many tables use a unique index as a primary key. InterBase doesn't have an AutoInc field. Because multiple clients cannot generate unique identifiers, you can rely on the server to do this. Almost all SQL servers offer a counter you can call to ask for a new ID, which you should later use for the table. InterBase calls these automatic counters generators, and Oracle calls them sequences. Here is the sample InterBase code:
create generator cust_no_gen; ... gen_id (cust_no_gen, 1);
The gen_id function extracts the new unique value of the generator passed as the first parameter; the second parameter indicates how much to increase (in this case, by one).
At this point you can add a trigger to a table (an automatic handler for one of the table's events). A trigger is similar to the event handler of the Table component, but you write it in SQL and execute it on the server, not on the client. Here is an example:
create trigger set_cust_no for customers before insert position 0 as begin new.cust_no = gen_id (cust_no_gen, 1); end
This trigger is defined for the customers table and is activated each time a new record is inserted. The new symbol indicates the new record you are inserting. The position option indicates the order of execution of multiple triggers connected to the same event. (Triggers with the lowest values are executed first.)
Inside a trigger, you can write DML statements that also update other tables, but watch out for updates that end up reactivating the trigger and create endless recursion. You can later modify or disable a trigger by calling the alter trigger or drop trigger statement.
Triggers fire automatically for specified events. If you have to make many changes in the database using batch operations, the presence of a trigger can slow the process. If the input data has already been checked for consistency, you can temporarily deactivate the trigger. These batch operations are often coded in stored procedures, but stored procedures generally cannot issue DDL statements like those required for deactivating and reactivating the trigger. In this situation, you can define a view based on a select * from table command, thus creating an alias for the table. Then you can let the stored procedure do the batch processing on the table and apply the trigger to the view (which should also be used by the client program).







