Introducing XML
Introducing XML
Extensible Markup Language (XML) is a simplified version of SGML and is getting a lot of attention in the IT world. XML is a markup language, meaning it uses symbols to describe its own content—in this case, tags consisting of specially defined text enclosed in angle brackets. It is extensible because it allows for free markers (in contrast, for example, to HTML, which has predefined markers). The XML language is a standard promoted by the World Wide Web Consortium (W3C). The XML Recommendation is at www.w3.org/TR/REC-xml.
XML has been touted as the ASCII of the year 2000, to indicate a simple and widespread technology and also to indicate that an XML document is a plain-text file (optionally with Unicode characters instead of plain ASCII text). The important characteristic of XML is that it is descriptive, because every tag has an almost human-readable name. Here is an example, in case you've never seen an XML document:
<book> <title>Mastering Delphi 7</title> <author>Cantu</author> <publisher>Sybex</publisher> </book>
XML has a few disadvantages I want to underline from the beginning. The biggest is that without a formal description, a document is worth little. If you want to exchange documents with another company, you must agree on what each tag means and also on the semantic meaning of the content. (For example, when you have a quantity, you have to agree on the measurement system or include it in the document.) Another disadvantage is that XML documents are much larger than other formats; using strings for numbers, for example, is far from efficient, and the repeated opening and closing tags eat up a lot of space. The good news is that XML compresses well, for the same reason.
Core XML Syntax
A few technical elements of XML are worth knowing before we discuss its usage in Delphi. Here is a short summary of the key elements of the XML syntax:
-
White space (including the space character, carriage return, line feed, and tabs) is generally ignored (as in an HTML document). It is important to format an XML document to make it readable by a human being, but your programs won't care much.
-
You can add comments within <!-- and --> markers, which are basically ignored by XML processors. There are also directives and processing instructions, enclosed within <? and ?> markers.
-
There a few special or reserved characters you cannot use in the text. The only two symbols you can never use are the less-than character (or left angle bracket, <, used to delimit a marker), which is replaced by <, and the ampersand character (&), which is replaced by &. Other optional special characters are > for the greater-than symbol (right angle bracket, >), ' for the single quote ('), and " for the double quote (").
-
To add non-XML content (for example, binary information or a script), you can use a CDATA section, enclosed within <![CDATA[ and ]]>.
-
All markers are enclosed by angle brackets, < and >. Markers are case sensitive (in contrast to HTML).
-
For each opening marker, you must have a matching closing marker, denoted by an initial slash character:
<node>value</node>
-
Markers must not overlap—they must be properly nested, as in the first line here (the second line is not correct):
<node>xx <nested> yy</nested> </node> // OK <node>xx <nested> yy</node> </nested> // WRONG
-
If a marker has no content (but its presence is important), you can replace the opening and closing markers with a single marker that includes a final (trailing) slash: <node/>.
-
Markers can have attributes, using multiple attribute names followed by a value enclosed within quotes:
<node attrib1="aaa">
-
Any XML node can have multiple attributes, multiple embedded tags, and only one block of text, representing the value of the node. It is common practice for XML nodes to have either a textual value or embedded tags, and not both. Here is an example of the full syntax of a node:
<node attrib1="aaa" attrib2="bbb"> value1 <child1> value2 </child1> </node> -
A node can have multiple child nodes with the same tag (tags need not be unique). Attribute names are unique for each node.
Well-Formed XML
The elements discussed in the previous section define the syntax of an XML document, but they are not enough. An XML document is considered syntactically correct, or well formed, if it follows a few extra rules. Notice that this type of check doesn't guarantee that the content of the document is meaningful—only that the tags are properly laid out.
Each document should have a prologue indicating that it is indeed an XML document, which version of XML it complies with, and possibly the type of character encoding. Here is an example:
<?xml version="1.0" encoding="UTF-8"?>
Possible encodings include Unicode character sets (such as UTF-8, UTF-16, and UTF-32) and some ISO encodings (such as ISO-10646-xxx or ISO-8859-xxx). The prologue can also include external declarations, the schema used to validate the document, namespace declarations, an associated XSL file, and some internal entity declarations. Refer to XML documentation or books for more information about these topics.
An XML document is well formed if it has a prologue, has a proper syntax (see the rules in the previous section), and has a tree of nodes with a single root. Most tools (including Internet Explorer) check whether a document is well formed when loading it.
| Note |
XML is more formal and precise than HTML. The W3C is working on an XHTML standard that will make HTML documents XML compliant, for better processing with XML tools. This implies many changes in a typical HTML document, such as avoiding attributes with no values, adding all the closing markers (as in </p> and </li>), adding the slash to stand-alone markers (as <hr/> and <br/>), proper nesting, and more. An HTML-to-XHTML converter called HTML Tidy is hosted by the W3C website at www.w3.org/People/Raggett/tidy/. |
Working with XML
To get acquainted with the format of XML, you can use one of the existing XML editors available on the market (including Delphi itself and Context, a programmer's editor written in Delphi). When you load an XML document into Internet Explorer, you'll see whether it is correct and, in this case, you'll see it within the browser in a tree-like structure. (At the time I'm writing this, other browsers have more limited XML support.)
To speed up this type of operation, I've built the simplest XML editor I could come up with—basically a memo with XML syntax-checking and a browser attached to it. The XmlEditOne example has a PageControl with three pages. The first page, Settings, hosts a couple of components in which you can insert the path and the name of the file you want to work with. (The reason for not using a standard dialog will become clear when I show you an extension of the program.) The edit box hosting the complete filename is automatically updated with the path and filename, provided the AutoUpdate check box is selected.
The second page hosts a Memo control; the text of the XML file is loaded and saved by clicking the two toolbar buttons. As soon as you load the file, or each time you modify its text, its content is loaded into a DOM to let a parser check for its correctness (something that would be complex to do with your own code). To parse the code, I've used the XMLDocument component available in Delphi, which is basically a wrapper around a DOM available on the computer and indicated by its DOMVendor property. I'll discuss the use of this component in more detail in the next section. For the moment, suffice to say you can assign a string list to its XML property and activate it to let it parse the XML text and eventually report an error with an exception.
For this example, this behavior is far from good, because while typing the XML code you'll have temporarily incorrect XML. Still, I prefer not to ask the user to click a button to do the validation, but rather to let it run continuously. Because it is not possible to disable the parse exception raised by the XMLDocument component, I had to work at a lower level, extracting the DOMPersist property (referring to the persistency interface of the DOM) after extracting the IXMLDocumentAccess interface from the XMLDocument component (called XmlDoc in this code). You can also extract the IDOMParseError interface from the document component, to display any error message in the status bar:
procedure TFormXmlEdit.MemoXmlChange(Sender: TObject);
var
eParse: IDOMParseError;
begin
XmlDoc.Active := True;
xmlBar.Panels[1].Text := 'OK';
xmlBar.Panels[2].Text := '';
(XmlDoc as IXMLDocumentAccess).DOMPersist.loadxml(MemoXml.Text);
eParse := (XmlDoc.DOMDocument as IDOMParseError);
if eParse.errorCode <> 0 then
with eParse do
begin
xmlBar.Panels[1].Text := 'Error in: ' + IntToStr (Line) + '.' +
IntToStr (LinePos);
xmlBar.Panels[2].Text := SrcText + ': ' + Reason;
end;
end;
You can see an example of the output of the program in Figure 22.1, alongside the XML tree view provided by the third page (for a correct document). The third page of the program is built using the WebBrowser component, which embeds Internet Explorer's ActiveX control. Unfortunately, there is no direct way to assign a string with the XML text to this control, so you'll have to save the file first and then move to its page to trigger the loading of the XML in the browser (after manually clicking the Refresh button at least once).
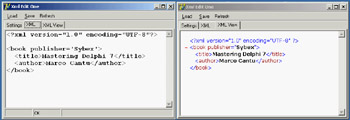 Figure 22.1: The XmlEditOne example allows you to enter XML text in a memo, indicating errors as you type, and shows the result in the embedded browser.
Figure 22.1: The XmlEditOne example allows you to enter XML text in a memo, indicating errors as you type, and shows the result in the embedded browser.
| Note |
I've used this code as a starting point to build a full-fledged XML editor called XmlTypist for a company I work with. It includes syntax highlighting, XSLT support, and a number of extra features. Refer to Appendix A, "Extra Delphi Tools by the Author" for the availability of this free XML editor. |
Managing XML Documents in Delphi
Now that you know the core elements of XML, we can begin discussing how to manage XML documents in Delphi programs (or in programs in general; some of the techniques discussed here go beyond the language used). There are two typical techniques for manipulating XML documents: using a Document Object Model (DOM) interface or using the Simple API for XML (SAX). The two approaches are quite different:
-
The DOM loads the entire document into a hierarchical tree of nodes, allowing you to read them and manipulate them to change the document. For this reason, the DOM is suitable when you want to navigate the XML structure in memory and edit it, or for creating new documents from scratch.
-
The SAX parses the document, firing an event for each element of the document without building a structure in memory. Once parsed by the SAX, the document is lost, but this operation is generally much faster than the construction of the DOM tree. Using the SAX is good for reading a document once—for example, if you're looking for a portion of its data.
There is a third classic way to manipulate (and specifically create) XML documents: string management. Creating a document by adding strings is the fastest operation, particularly if you can do a single pass (and don't need to modify nodes already generated). Even reading documents by means of string functions is very fast, but this process can become difficult for complex structures.
Besides these classic XML processing approaches, which are also available for other programming languages, Delphi provides two more techniques you should consider. The first is the definition of interfaces that map the document structure and are used to access the document instead of the generic DOM interface. As you'll see, this approach makes for faster coding and more robust applications. The second technique is the development of transformations that allow you to read a generic XML document into a ClientDataSet component or save the dataset into an XML file of a given structure (not the specific XML structure natively supported by the ClientDataSet or MyBase).
I won't try to fully assess which option is better suited for each type of document and manipulation, but I will highlight some of the advantages and disadvantages while discussing examples of each approach in the following sections. At the end of the chapter, I'll discuss the relative speed of techniques for processing large files.







