Section 10.6. Rewriting the Mail Address
Rewrite rules are the heart of the sendmail.cf file. Rulesets are groups of individual rewrite rules used to parse email addresses from user mail programs and rewrite them into the form required by the mail delivery programs. Each rewrite rule is defined by an R command. The syntax of the R command is:
Rpattern transformation comment
The fields in an R command are separated by tab characters. The comment field is ignored by the system, but good comments are vital if you want to have any hope of understanding what's going on. The pattern and transformation fields are the heart of this command.
10.6.1 Pattern Matching
Rewrite rules match the input address against the pattern, and if a match is found, they rewrite the address in a new format using the rules defined in the transformation. A rewrite rule may process the same address several times because, after being rewritten, the address is again compared against the pattern. If it still matches, it is rewritten again. The cycle of pattern matching and rewriting continues until the address no longer matches the pattern.
The pattern is defined using macros, classes, literals, and special metasymbols. The macros, classes, and literals provide the values against which the input is compared, and the metasymbols define the rules used in matching the pattern. Table 10-3 shows the metasymbols used for pattern matching.
|
Symbol |
Meaning |
|---|---|
|
$@ |
Match exactly zero tokens. |
|
$* |
Match zero or more tokens. |
|
$+ |
Match one or more tokens. |
|
$- |
Match exactly one token. |
|
$=x |
Match any token in class x. |
|
$~x |
Match any token not in class x. |
|
$x |
Match all tokens in macro x. |
|
$%x |
Match any token in the NIS map named in macro x.[14] |
|
$!x |
Match any token not in the NIS map named in macro x. |
|
$%y |
Match any token in the NIS hosts.byname map. |
[14] This symbol is specific to Sun operating systems.
All of the metasymbols request a match for some number of tokens. A token is a string of characters in an email address delimited by an operator. The operators are the characters defined in the OperatorChars option. Operators are also counted as tokens when an address is parsed. For example:
becky@rodent.wrotethebook.com
This email address contains seven tokens: becky, @, rodent, ., wrotethebook, ., and com. This address would match the pattern:
$-@$+
The address matches the pattern because:
It has exactly one token before the @ that matches the requirement of the $- symbol.
It has an @ that matches the pattern's literal @.
It has one or more tokens after the @ that match the requirement of the $+ symbol.
Many addresses, such as hostmaster@apnic.net and craigh@ora.com, match this pattern, but other addresses do not. For example, rebecca.hunt@wrotethebook.com does not match because it has three tokens: rebecca, ., and hunt, before the @. Therefore, it fails to meet the requirement of exactly one token specified by the $- symbol. Using the metasymbols, macros, and literals, patterns can be constructed to match any type of email address.
When an address matches a pattern, the strings from the address that match the metasymbols are assigned to indefinite tokens. The matching strings are called indefinite tokens because they may contain more than one token value. The indefinite tokens are identified numerically according to the relative position in the pattern of the metasymbol that the string matched. In other words, the indefinite token produced by the match of the first metasymbol is called $1; the match of the second symbol is called $2; the third is $3; and so on. When the address becky@rodent.wrotethebook.com matched the pattern $-@$+, two indefinite tokens were created. The first is identified as $1 and contains the single token, becky, that matched the $- symbol. The second indefinite token is $2 and contains the five tokensrodent, ., wrotethebook, ., and comthat matched the $+ symbol. The indefinite tokens created by the pattern matching can then be referenced by name ($1, $2, etc.) when rewriting the address.
A few of the symbols in Table 10-3 are used only in special cases. The $@ symbol is normally used by itself to test for an empty, or null, address. The symbols that test against NIS maps can only be used on Sun systems that run the sendmail program that Sun provides with the operating system. We'll see in the next section that systems running basic sendmail can use NIS maps, but only for transformationnot for pattern matching.
10.6.2 Transforming the Address
The transformation field, from the right-hand side of the rewrite rule, defines the format used for rewriting the address. It is defined with the same things used to define the pattern: literals, macros, and special metasymbols. Literals in the transformation are written into the new address exactly as shown. Macros are expanded and then written. The metasymbols perform special functions. The transformation metasymbols and their functions are shown in Table 10-4.
|
Symbol |
Meaning |
|---|---|
|
$n |
Substitute indefinite token n. |
|
$[name$] |
Substitute the canonical form of name. |
|
$map key$@argument $:default$) |
Substitute a value from database map indexed by key. |
|
$>n |
Call ruleset n. |
|
$@ |
Terminate ruleset. |
|
$: |
Terminate rewrite rule. |
The $n symbol, where n is a number, is used for the indefinite token substitution discussed above. The indefinite token is expanded and written to the "new" address. Indefinite token substitution is essential for flexible address rewriting. Without it, values could not be easily moved from the input address to the rewritten address. The following example demonstrates this.
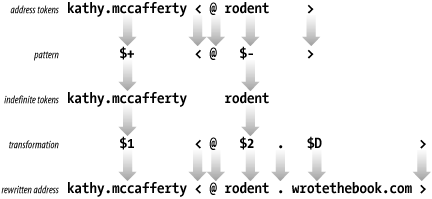
Addresses are always processed by several rewrite rules. No one rule tries to do everything. Assume the input address mccafferty@rodent has been through some preliminary processing and now is:
kathy.mccafferty<@rodent>
Assume the current rewrite rule is:
R$+<@$-> $1<@$2.$D> user@host -> user@host.domain
The address matches the pattern because it contains one or more tokens before the literal <@, exactly one token after the <@, and then the literal >. The pattern match produces two indefinite tokens that are used in the transformation to rewrite the address.
The transformation contains the indefinite token $1, a literal <@, indefinite token $2, a literal dot (.), the macro D, and the literal >. After the pattern matching, $1 contains kathy.mccafferty and $2 contains rodent. Assume that the macro D was defined elsewhere in the sendmail.cf file as wrotethebook.com. In this case the input address is rewritten as:
kathy.mccafferty<@rodent.wrotethebook.com>
Figure 10-3 illustrates this specific address rewrite. It shows the tokens derived from the input address and how those tokens are matched against the pattern. It also shows the indefinite tokens produced by the pattern matching and how the indefinite tokens and other values from the transformation are used to produce the rewritten address. After rewriting, the address is again compared to the pattern. This time it fails to match the pattern because it no longer contains exactly one token between the literal <@ and the literal >. So, no further processing is done by this rewrite rule and the address is passed to the next rule in line. Rules in a ruleset are processed sequentially, though a few metasymbols can be used to modify this flow.
Figure 10-3. Rewriting an address
The $>n symbol calls ruleset n and passes the address defined by the remainder of the transformation to ruleset n for processing. For example:
$>9 $1 % $2
This transformation calls ruleset 9 ($>9), and passes the contents of $1, a literal %, and the contents of $2 to ruleset 9 for processing. When ruleset 9 finishes processing, it returns a rewritten address to the calling rule. The returned email address is then compared again to the pattern in the calling rule. If it still matches, ruleset 9 is called again.
The recursion built into rewrite rules creates the possibility for infinite loops. sendmail does its best to detect possible loops, but you should take responsibility for writing rules that don't loop. The $@ and the $: symbols are used to control processing and to prevent loops. If the transformation begins with the $@ symbol, the entire ruleset is terminated and the remainder of the transformation is the value returned by the ruleset. If the transformation begins with the $: symbol, the individual rule is executed only once. Use $: to prevent recursion and to prevent loops when calling other rulesets. Use $@ to exit a ruleset at a specific rule.
The $[name$] symbol converts a host's nickname or its IP address to its canonical name by passing the value name to the name server for resolution. For example, using the wrotethebook.com name servers, $[mouse$] returns rodent.wrotethebook.com and $[[172.16.12.1]$] returns crab.wrotethebook.com.
In the same way that a hostname or address is used to look up a canonical name in the name server database, the $(map key$) syntax uses the key to retrieve information from the database identified by map. This is a more generalized database retrieval syntax than the one that returns canonical hostnames, and it is more complex to use. Before we get into the details of setting up and using databases from within sendmail, let's finish describing the rest of the syntax of rewrite rules.
There is a special rewrite rule syntax that is used in ruleset 0. Ruleset 0 defines the triple (mailer, host, user) that specifies the mail delivery program, the recipient host, and the recipient user.
The special transformation syntax used to do this is:
$#mailer$@host$:user
An example of this syntax taken from the generic-linux.cf sample file is:
R$*<@$*>$* $#esmtp $@ $2 $: $1 < @ $2 > $3 user@host.domain
Assume the email address david<@ora.wrotethebook.com> is processed by this rule. The address matches the pattern $*<@$+>$* because:
The address has zero or more tokens (david) that match the first $* symbol.
The address has a literal <@.
The address has zero or more tokens (the five tokens in ora.wrotethebook.com) that match the requirement of the second $* symbol.
The address has a literal >.
The address has zero or more (in this case, zero) tokens that match the requirement of the last $* symbol.
This pattern match produces two indefinite tokens. Indefinite token $1 contains david and $2 contains ora.wrotethebook.com. No other matches occurred, so $3 is null. These indefinite tokens are used to rewrite the address into the following triple:
$#smtp$@ora.wrotethebook.com$:david<@ora.wrotethebook.com>
The components of this triple are:
- $#smtp
-
smtp is the internal name of the mailer that delivers the message.
- $@ora.wrotethebook.com
-
ora.wrotethebook.com is the recipient host.
- $:david<@ora.wrotethebook.com>
-
david<@ora.wrotethebook.com> is the recipient user.
There are a few variations on the mailer triple syntax that are also used in the templates of some rules. Two of these variations use only the "mailer" component.
- $#OK
-
Indicates that the input address passed a security test. For example, the address is permitted to relay mail.
- $#discard
-
Indicates that the input address failed some security test and that the email message should be discarded.
|

The $#OK and $#discard mailers are used in relay control and security. The $#discard mailer silently discards the mail and does not return an error message to the sender. The $#error mailer also handles undeliverable mail, but unlike $#discard, it returns an error message to the sender. The template syntax used with the $#error mailer is more complex than the syntax of either $#OK or $#discard. That syntax is shown here:
$#error $@dsn-code $:message
The mailer value must be $#error. The $:message field contains the text of the error message that you wish to send. The $@dsn-code field is optional. If it is provided, it appears before the message and must contain a valid Delivery Status Notification (DSN) error code as defined by RFC 1893, Mail System Status Codes.
DSN codes are composed of three dot-separated components:
- class
-
Provides a broad classification of the status. Three values are defined for class in the RFC: 2 means success, 4 means temporary failure, and 5 means permanent failure.
- subject
-
Classifies the error messages as relating to one of eight categories:
- 0 (Undefined)
-
The specific category cannot be determined.
- 1 (Addressing)
-
A problem was encountered with the address.
- 2 (Mailbox)
-
A problem was encountered with the delivery mailbox.
- 3 (Mail system)
-
The destination mail delivery system is having a problem.
- 4 (Network)
-
The network infrastructure is having a problem.
- 5 (Protocol)
-
A protocol problem was encountered.
- 6 (Content)
-
The message content caused a translation error.
- 7 (Security)
-
A security problem was reported.
- detail
-
Provides the details of the specific error. The detail value is meaningful only in context of the subject code. For example, x.1.1 means a bad destination user address and x.1.2 means a bad destination host address, while x.2.1 means the mailbox is disabled and x.2.2 means the mailbox is full. There are far too many detail codes to list here. See RFC 1893 for a full list.
An error message written to use the DSN format might be:
R<@$+> $#error$@5.1.1$:"user address required"
This rule returns the DSN code 5.1.1 and the message "user address required" when the address matches the pattern. The DSN code has a 5 in the class field, meaning it is a permanent failure; a 1 in the subject field, meaning it is an addressing failure; and a 1 in the detail field, meaning that, given the subject value of 1, it is a bad user address.
Error codes and the error syntax are part of the advanced configuration options used for relay control and security. These values are generated by the m4 macro used to select these advanced features. These values are very rarely placed in the sendmail.cf file by a system administrator directly.
10.6.2.1 Transforming with a database
External databases can be used to transform addresses in rewrite rules. The database is included in the transformation part of a rule by using the following syntax:
$(map key [$@argument...] [$:default] $)
map is the name assigned to the database within the sendmail.cf file. The name assigned to map is not limited by the rules that govern macro names. Like mailer names, map names are used only inside of the sendmail.cf file and can be any name you choose. Select a simple descriptive name, such as "users" or "mailboxes". The map name is assigned with a K command. (More on the K command in a moment.)
key is the value used to index into the database. The value returned from the database for this key is used to rewrite the input address. If no value is returned, the input address is not changed unless a default value is provided.
An argument is an additional value passed to the database procedure along with the key. Multiple arguments can be used, but each argument must start with $@. The argument can be used by the database procedure to modify the value it returns to sendmail. It is referenced inside the database as %n, where n is a digit that indicates the order in which the argument appears in the rewrite rule%1, %2, and so onwhen multiple arguments are used. (Argument %0 is the key.)
An example will make the use of arguments clear. Assume the following input address:
tom.martin<@sugar>
Further, assume the following database with the internal sendmail name of "relays":
oil %1<@relay.fats.com> sugar %1<@relay.calories.com> salt %1<@server.sodium.org>
Finally, assume the following rewrite rule:
R$+<@$-> $(relays $2 $@ $1 $:$1<@$2> $)
The input address tom.martin<@sugar> matches the pattern because it has one or more tokens (tom.martin) before the literal <@ and exactly one token (sugar) after it. The pattern matching creates two indefinite tokens and passes them to the transformation. The transformation calls the database (relays) and passes it token $2 (sugar) as the key and token $1 (tom.martin) as the argument. If the key is not found in the database, the default ($1<@$2>) is used. In this case, the key is found in the database. The database program uses the key to retrieve "%1@relay.calories.com", expands the %1 argument, and returns "tom.martin@relay.calories.com" to sendmail, which uses the returned value to replace the input address.
Before a database can be used within sendmail, it must be defined. This is done with the K command. The syntax of the K command is:
Kname type [arguments]
name is the name used to reference this database within sendmail. In the example above, the name is "relays".
type is the class of database. The type specified in the K command must match the database support compiled into your sendmail. Most sendmail programs do not support all database types, but a few basic types are widely supported. Common types are hash, btree, and nis. There are many more, all of which are described in Appendix E.
arguments are optional. Generally, the only argument is the path of the database file. Occasionally the arguments include flags that are interpreted by the database program. The full list of K command flags that can be passed in the argument field is found in Appendix E.
To define the "relays" database file used in the example above, we might enter the following command in the sendmail.cf file:
Krelays hash /etc/mail/relays
The name relays is simply a name you chose because it is descriptive. The database type hash is a type supported by your version of sendmail and was used by you when you built the database file. Finally, the argument /etc/mail/relays is the location of the database file you created.
Don't worry if you're confused about how to build and use database files within sendmail. We will revisit this topic later in the chapter and the examples will make the practical use of database files clear.
10.6.3 The Set Ruleset Command
Rulesets are groups of associated rewrite rules that can be referenced by a name or a number. The S command marks the beginning of a ruleset and names it. In the Sname command syntax, name identifies the ruleset. Optionally a number can also be assigned to the ruleset using the full Sname=number syntax. In that case, the ruleset can be referenced either by its name or its number. It is even possible to identify a ruleset with a number instead of a name by using the old Snumber syntax. This form of the syntax is primarily found in old configurations because old versions of sendmail used numbers to identify rulesets.
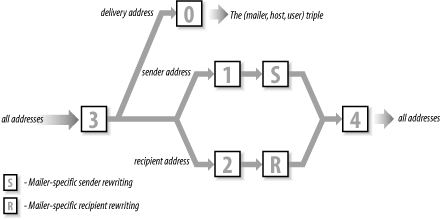
Rulesets can be thought of as subroutines, or functions, designed to process email addresses. They are called from mailer definitions, from individual rewrite rules, or directly by sendmail. Six rulesets have special functions and are called directly by sendmail. These are:
Ruleset canonify (3) is the first ruleset applied to addresses. It converts an address to the canonical form: local-part@host.domain.
Ruleset parse (0) is applied to the addresses used to deliver the mail. Ruleset parse is applied after ruleset canonify, and only to the recipient addresses actually used for mail delivery. It resolves the address to the triple (mailer, host, user) composed of the name of the mailer that will deliver the mail, the recipient hostname, and the recipient username.
Ruleset sender (1) is applied to all sender addresses in the message.
Ruleset recipient (2) is applied to all recipient addresses in the message.
Ruleset final (4) is applied to all addresses in the message and is used to translate internal address formats into external address formats.
Ruleset localaddr (5) is applied to local addresses after sendmail processes the address against the aliases file. Ruleset 5 is applied only to local addresses that do not have an alias.
Figure 10-4 shows the flow of the message and addresses through these rulesets. The S and R symbols stand for additional rulesets. They have names just like all normal rulesets, but the names are not fixed as is the case with the rulesets described above. The S and R ruleset names are identified in the S and R fields of the mailer definition. Each mailer may specify its own S and R rulesets for mailer-specific cleanup of the sender and recipient addresses just before the message is delivered.
Figure 10-4. Sequence of rulesets
There are, of course, many more rulesets in most sendmail.cf files. The other rulesets provide additional address processing, and are called by existing rulesets using the $>n construct. (See Table 10-5 later in this chapter.) The rulesets provided in any vendor's sendmail.cf file will be adequate for delivering SMTP mail. It's unlikely you'll have to add to these rulesets, unless you want to add new features to your mailer.







