Section 2.3. Internet Routing Architecture
Chapter 1 described the evolution of the Internet architecture over the years. Along with these architectural changes have come changes in the way that routing information is disseminated within the network.
In the original Internet structure, there was a hierarchy of gateways. This hierarchy reflected the fact that the Internet was built upon the existing ARPAnet. When the Internet was created, the ARPAnet was the backbone of the network: a central delivery medium to carry long-distance traffic. This central system was called the core, and the centrally managed gateways that interconnected it were called the core gateways.
In that hierarchical structure, routing information about all of the networks on the Internet was passed into the core gateways. The core gateways processed the information and then exchanged it among themselves using the Gateway to Gateway Protocol (GGP). The processed routing information was then passed back out to the external gateways. The core gateways maintained accurate routing information for the entire Internet.
Using the hierarchical core router model to distribute routing information has a major weakness: every route must be processed by the core. This places a tremendous processing burden on the core, and as the Internet grew larger the burden increased. In network-speak, we say that this routing model does not "scale well." For this reason, a new model emerged.
Even in the days of a single Internet core, groups of independent networks called autonomous systems existed outside of the core. The term autonomous system (AS) has a formal meaning in TCP/IP routing. An autonomous system is not merely an independent network. It is a collection of networks and gateways with its own internal mechanism for collecting routing information and passing it to other independent network systems. The routing information passed to the other network systems is called reachability information. Reachability information simply says which networks can be reached through that autonomous system. In the days of a single Internet core, autonomous systems passed reachability information into the core for processing. The Exterior Gateway Protocol (EGP) was the protocol used to pass reachability information between autonomous systems and into the core.
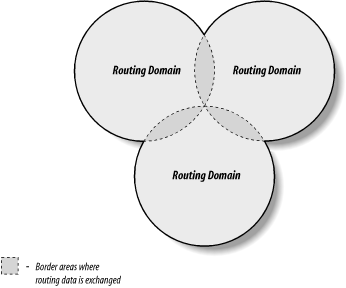
The new routing model is based on co-equal collections of autonomous systems called routing domains. Routing domains exchange routing information with other domains using Border Gateway Protocol (BGP). Each routing domain processes the information it receives from other domains. Unlike the hierarchical model, this model does not depend on a single core system to choose the "best" routes. Each routing domain does this processing for itself; therefore, this model is more expandable. Figure 2-3 represents this model with three intersecting circles. Each circle is a routing domain. The overlapping areas are border areas, where routing information is shared. The domains share information but do not rely on any one system to provide all routing information.
Figure 2-3. Routing domains
The problem with this model is: how are "best" routes determined in a global network if there is no central routing authority, like the core, that is trusted to determine the "best" routes? In the days of the NSFNET, the policy routing database (PRDB) was used to determine whether the reachability information advertised by an autonomous system was valid. But now, even the NSFNET does not play a central role.
To fill this void, NSF created the Routing Arbiter (RA) servers when it created the Network Access Points (NAPs) that provide interconnection points for the various service provider networks. A route arbiter is located at each NAP. The server provides access to the Routing Arbiter Database (RADB), which replaced the PRDB. ISPs can query servers to validate the reachability information advertised by an autonomous system.
The RADB is only part of the Internet Routing Registry (IRR). As befits a distributed routing architecture, there are multiple organizations that validate and register routing information. Europeans were the pioneers in this. The Reseaux IP Europeens (RIPE) Network Control Center (NCC) provides the routing registry for European IP networks. Big network carriers provide registries for their customers. All of the registries share a common format based on the RIPE-181 standard.
Many ISPs do not use the route servers. Instead they depend on formal and informal bilateral agreements, where two ISPs get together and decide what reachability information each will accept from the other. They create, in effect, private routing policies. Small ISPs have criticized the routing policies of the tier-one providers, claiming that they limit competition. In response, most tier-one providers have promised to make the policies public, which should clarify the basis for the current architecture and may even spark more changes.
Creating an effective routing architecture continues to be a major challenge for the Internet, and the routing architecture will certainly evolve over time. No matter how it is derived, the routing information eventually winds up in your local gateway, where it is used by IP to make routing decisions.







