Chapter 10: Parallel Virtual Machine
Chapter 10: Parallel Virtual Machine
Overview
Al Geist
PVM (Parallel Virtual Machine) was first released in the early 1990s as an outgrowth of an ongoing computing research project involving Oak Ridge National Laboratory, the University of Tennessee, and Emory University. The general goals of this project are to investigate issues in, and develop solutions for, heterogeneous distributed computing. PVM was one of the solutions. PVM was designed to be able to combine computers having different operating systems, different data representations (both number of bits and byte order), different architectures (multiprocessor, single processor, and even supercomputers), different languages, and different networks and have them all work together on a single computational problem.
PVM existed before Beowulf clusters were invented and in fact was the software used to run applications on the first Beowulf clusters. Today, both PVM and MPICH are often included in software distributions for Beowulf clusters.
The basic idea behind PVM was to create a simple software package that could be loaded onto any collection of computers that would make the collection appear to be a single, large, distributed-memory parallel computer. PVM provides a way for aggregating the power and memory of distributed compute resources. Today this is called Grid computing. In the early 1990s PVM was used to do a number of early Grid experiments, including creating the first international Grid by combining supercomputers in the United Kingdom with supercomputers in the United States, creating a Grid that combined 53 Cray supercomputers across the United States into a single super-supercomputer, and connecting the two largest parallel computers in the world into a 4,000-processor system to solve a nanotechnology problem that eventually led to the high-capacity hard drives used in today's PCs. In 1990 PVM was used for an application in high-temperature superconductivity; the application won a Gordon Bell Prize in supercomputing—the first of many Gordon Bell prizes won by researchers using PVM.
But PVM's real contribution to science and computing is not in supercomputing. PVM's reliability and ease of use made this software package very popular for hooking together a network of workstations or a pile of PCs into a virtual parallel computer that gave PVM users several times more power than they would have otherwise. With tens of thousands of users, PVM was so popular that it became a de facto standard for heterogeneous distributed computing worldwide.
PVM still remains popular, particularly for applications that require fault tolerance. For example, PVM is used to provide fault tolerance to the Globus Toolkit Grid Information Services for the DOE Science Grid. PVM is also used on clusters running the Genomics Integrated Supercomputer Toolkit to provide 24/7 availability despite faults in the clusters.
The tiny 1.5 Mbyte PVM software package is an integrated set of software tools and libraries that emulates a general-purpose, dynamic, heterogeneous parallel computing environment on a set of computers that are connected by a network. The network can be the Internet (Grid computing) or a dedicated local network (cluster). One use of PVM today is to combine multiple Beowulf clusters at a site into a Grid of clusters as shown in Figure 10.1.
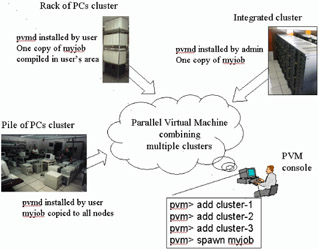
Figure 10.1: PVM used to create a Grid of clusters.
The PVM library includes functions to add computers to the parallel virtual machine, spawn tasks on these computers, and exchange data between tasks through message passing. This chapter provides detailed descriptions and examples of the basic concepts and methodologies involved in using PVM on clusters as well as its use as a means to combine multiple clusters into a Grid of clusters. The next chapter details the special functions in PVM for use in fault tolerant and dynamic environments.







