15.2 Using Condor
15.2 Using Condor
The road to using Condor effectively is a short one. The basics are quickly and easily learned.
15.2.1 Roadmap to Using Condor
The following steps are involved in running jobs using Condor:
-
Prepare the Job to Run Unattended. An application run under Condor must be able to execute as a batch job. Condor runs the program unattended and in the background. A program that runs in the background will not be able to perform interactive input and output. Condor can redirect console output (stdout and stderr) and keyboard input (stdin) to and from files. You should create any needed files that contain the proper keystrokes needed for program input. You should also make certain the program will run correctly with the files.
-
Select the Condor Universe. Condor has five runtime environments from which to choose. Each runtime environment is called a Universe. Usually the Universe you choose is determined by the type of application you are asking Condor to run. There are six job Universes in total: two for serial jobs (Standard and Vanilla), one for parallel PVM jobs (PVM), one for parallel MPI jobs (Parallel), one for Grid applications (Globus), and one for meta-schedulers (Scheduler). Section 15.2.4 provides more information on each of these Universes.
-
Create a Submit Description File. The details of a job submission are defined in a submit description file. This file contains information about the job such as what executable to run, which Universe to use, the files to use for stdin, stdout, and stderr, requirements and preferences about the machine which should run the program, and where to send e-mail when the job completes. You can also tell Condor how many times to run a program; it is simple to run the same program multiple times with different data sets.
-
Submit the Job. Submit the program to Condor with the condor_submit command.
Once a job has been submitted, Condor handles all aspects of running the job. You can subsequently monitor the job's progress with the condor_q and condor_status commands. You may use condor_prio to modify the order in which Condor will run your jobs. If desired, Condor can also record what is being done with your job at every stage in its lifecycle, through the use of a log file specified during submission.
When the program completes, Condor notifies the owner (by e-mail, the user-specified log file, or both) the exit status, along with various statistics including time used and I/O performed. You can remove a job from the queue at any time with condor_rm.
15.2.2 Submitting a Job
To submit a job for execution to Condor, you use the condor_submit command. This command takes as an argument the name of the submit description file, which contains commands and keywords to direct the queuing of jobs. In the submit description file, you define everything Condor needs to execute the job. Items such as the name of the executable to run, the initial working directory, and command-line arguments to the program all go into the submit description file. The condor_submit command creates a job ClassAd based on the information, and Condor schedules the job.
The contents of a submit description file can save you considerable time when you are using Condor. It is easy to submit multiple runs of a program to Condor. To run the same program 500 times on 500 different input data sets, the data files are arranged such that each run reads its own input, and each run writes its own output. Every individual run may have its own initial working directory, stdin, stdout, stderr, command-line arguments, and shell environment.
The following examples illustrate the flexibility of using Condor. We assume that the jobs submitted are serial jobs intended for a cluster that has a shared file system across all nodes. Therefore, all jobs use the Vanilla Universe, the simplest one for running serial jobs. The other Condor Universes are explored later.
Example 1
Example 1 is the simplest submit description file possible. It queues up one copy of the program 'foo' for execution by Condor. A log file called 'foo.log' is generated by Condor. The log file contains events pertaining to the job while it runs inside of Condor. When the job finishes, its exit conditions are noted in the log file. We recommend that you always have a log file so you know what happened to your jobs. The queue statement in the submit description file tells Condor to use all the information specified so far to create a job ClassAd and place the job into the queue. Lines that begin with a pound character (#) are comments and are ignored by condor_submit.
# Example 1 : Simple submit file universe = vanilla executable = foo log = foo.log queue
Example 2
Example 2 queues two copies of the program 'mathematica'. The first copy runs in directory 'run_1', and the second runs in directory 'run_2'. For both queued copies, 'stdin' will be 'test.data', 'stdout' will be 'loop.out', and 'stderr' will be 'loop.error'. Two sets of files will be written, since the files are each written to their own directories. This is a convenient way to organize data for a large group of Condor jobs.
# Example 2: demonstrate use of multiple # directories for data organization. universe = vanilla executable = mathematica # Give some command line args, remap stdio arguments = -solver matrix input = test.data output = loop.out error = loop.error log = loop.log initialdir = run_1 queue initialdir = run_2 queue
Example 3
The submit description file for Example 3 queues 150 runs of program 'foo'. This job requires Condor to run the program on machines that have greater than 128 megabytes of physical memory, and it further requires that the job not be scheduled to run on a specific node. Of the machines that meet the requirements, the job prefers to run on the fastest floating-point nodes currently available to accept the job. It also advises Condor that the job will use up to 180 megabytes of memory when running. Each of the 150 runs of the program is given its own process number, starting with process number 0. Several built-in macros can be used in a submit description file; one of them is the $ (Process) macro which Condor expands to be the process number in the job cluster. This causes files 'stdin', 'stdout', and 'stderr' to be 'in.0', 'out.0', and 'err.0' for the first run of the program, 'in.1', 'out.1', and 'err.1' for the second run of the program, and so forth. A single log file will list events for all 150 jobs in this job cluster.
# Example 3: Submit lots of runs and use the # pre-defined $(Process) macro. universe = vanilla executable = foo requirements = Memory > 128 && Machine != "server-node.cluster.edu" rank = KFlops image_size = 180 Error = err.$(Process) Input = in.$(Process) Output = out.$(Process) Log = foo.log queue 150
Note that the requirements and rank entries in the submit description file will become the requirements and rank attributes of the subsequently created ClassAd for this job. These are arbitrary expressions that can reference any attributes of either the machine or the job; see Section 15.1.2 for more on requirements and rank expressions in ClassAds.
15.2.3 Overview of User Commands
Once you have jobs submitted to Condor, you can manage them and monitor their progress. Table 15.1 shows several commands available to the Condor user to view the job queue, check the status of nodes in the pool, and perform several other activities. Most of these commands have many command-line options; see the Command Reference chapter of the Condor manual for complete documentation. To provide an introduction from a user perspective, we give here a quick tour showing several of these commands in action.
|
Command |
Description |
|---|---|
|
condor_analyze |
Troubleshoot jobs that are not being matched |
|
condor_checkpoint |
Checkpoint jobs running on the specified hosts |
|
condor_compile |
Create a relinked executable for submission to the Standard Universe |
|
condor_glidein |
Add a Globus resource to a Condor pool |
|
condor_history |
View log of Condor jobs completed to date |
|
condor_hold |
Put jobs in the queue in hold state |
|
condor_prio |
Change priority of jobs in the queue |
|
condor_qedit |
Modify attributes of a previously submitted job |
|
condor_q |
Display information about jobs in the queue |
|
condor_release |
Release held jobs in the queue |
|
condor_reschedule |
Update scheduling information to the central manager |
|
condor_rm |
Remove jobs from the queue |
|
condor_run |
Submit a shell command-line as a Condor job |
|
condor_status |
Display status of the Condor pool |
|
condor_submit_dag |
Manage and queue jobs within a specified DAG for interjob dependencies. |
|
condor_submit |
Queue jobs for execution |
|
condor_userlog |
Display and summarize job statistics from job log files |
|
condor_version |
Display version number of installed software |
When jobs are submitted, Condor will attempt to find resources to service the jobs. A list of all users with jobs submitted may be obtained through condor_status with the -submitters option. An example of this would yield output similar to the following:
% condor_status -submitters
Name Machine Running IdleJobs HeldJobs
ballard@cs.wisc.edu bluebird.c 0 11 0
nice-user.condor@cs. cardinal.c 6 504 0
wright@cs.wisc.edu finch.cs.w 1 1 0
jbasney@cs.wisc.edu perdita.cs 0 0 5
RunningJobs IdleJobs HeldJobs
ballard@cs.wisc.edu 0 11 0
jbasney@cs.wisc.edu 0 0 5
nice-user.condor@cs. 6 504 0
wright@cs.wisc.edu 1 1 0
Total 7 516 5
Checking on the Progress of Jobs
The condor_q command displays the status of all jobs in the queue. An example of the output from condor_q is
% condor_q -- Schedd: uug.cs.wisc.edu : <128.115.121.12:33102> ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 55574.0 jane 6/23 11:33 4+03:35:28 R 0 25.7 seycplex seymour.d 55575.0 jane 6/23 11:44 0+23:24:40 R 0 26.8 seycplexpseudo sey 83193.0 jane 3/28 15:11 48+15:50:55 R 0 17.5 cplexmip test1.mp 83196.0 jane 3/29 08:32 48+03:16:44 R 0 83.1 cplexmip test3.mps 83212.0 jane 4/13 16:31 41+18:44:40 R 0 39.7 cplexmip test2.mps 5 jobs; 0 idle, 5 running, 0 held
This output contains many columns of information about the queued jobs. The ST column (for status) shows the status of current jobs in the queue. An R in the status column means the the job is currently running. An I stands for idle. The status H is the hold state. In the hold state, the job will not be scheduled to run until it is released (via the condor_release command). The RUN_TIME time reported for a job is the time that job has been allocated to a machine as DAYS+HOURS+MINS+SECS.
Another useful method of tracking the progress of jobs is through the user log. If you have specified a log command in your submit file, the progress of the job may be followed by viewing the log file. Various events such as execution commencement, checkpoint, eviction, and termination are logged in the file along with the time at which the event occurred. Here is a sample snippet from a user log file
000 (8135.000.000) 05/25 19:10:03 Job submitted from host: <128.105.146.14:1816>
...
001 (8135.000.000) 05/25 19:12:17 Job executing on host: <128.105.165.131:1026>
...
005 (8135.000.000) 05/25 19:13:06 Job terminated.
(1) Normal termination (return value 0)
Usr 0 00:00:37, Sys 0 00:00:00 - Run Remote Usage
Usr 0 00:00:00, Sys 0 00:00:05 - Run Local Usage
Usr 0 00:00:37, Sys 0 00:00:00 - Total Remote Usage
Usr 0 00:00:00, Sys 0 00:00:05 - Total Local Usage
9624 - Run Bytes Sent By Job
7146159 - Run Bytes Received By Job
9624 - Total Bytes Sent By Job
7146159 - Total Bytes Received By Job
...
The condor_jobmonitor tool parses the events in a user log file and can use the information to graphically display the progress of your jobs. Figure 15.2 contains a screenshot of condor_jobmonitor in action.
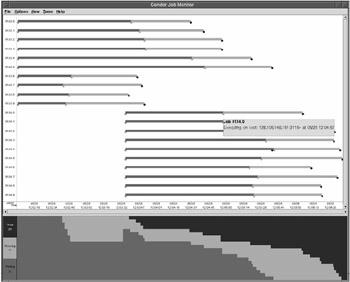
Figure 15.2: Condor jobmonitor tool.
You can locate all the machines that are running your job with the condor_status command. For example, to find all the machines that are running jobs submitted by breach@cs.wisc.edu, type
% condor_status -constraint 'RemoteUser == "breach@cs.wisc.edu"' Name Arch OpSys State Activity LoadAv Mem ActvtyTime alfred.cs. INTEL LINUX Claimed Busy 0.980 64 0+07:10:02 biron.cs.w INTEL LINUX Claimed Busy 1.000 128 0+01:10:00 cambridge. INTEL LINUX Claimed Busy 0.988 64 0+00:15:00 falcons.cs INTEL LINUX Claimed Busy 0.996 32 0+02:05:03 happy.cs.w INTEL LINUX Claimed Busy 0.988 128 0+03:05:00 istat03.st INTEL LINUX Claimed Busy 0.883 64 0+06:45:01 istat04.st INTEL LINUX Claimed Busy 0.988 64 0+00:10:00 istat09.st INTEL LINUX Claimed Busy 0.301 64 0+03:45:00 ...
To find all the machines that are running any job at all, type
% condor_status -run Name Arch OpSys LoadAv RemoteUser ClientMachine adriana.cs INTEL LINUX 0.980 hepcon@cs.wisc.edu chevre.cs.wisc. alfred.cs. INTEL LINUX 0.980 breach@cs.wisc.edu neufchatel.cs.w amul.cs.wi INTEL LINUX 1.000 nice-user.condor@cs. chevre.cs.wisc. anfrom.cs. INTEL LINUX 1.023 ashoks@jules.ncsa.ui jules.ncsa.uiuc astro.cs.w INTEL LINUX 1.000 nice-user.condor@cs. chevre.cs.wisc. aura.cs.wi INTEL LINUX 0.996 nice-user.condor@cs. chevre.cs.wisc. balder.cs. INTEL LINUX 1.000 nice-user.condor@cs. chevre.cs.wisc. bamba.cs.w INTEL LINUX 1.574 dmarino@cs.wisc.edu riola.cs.wisc.e bardolph.c INTEL LINUX 1.000 nice-user.condor@cs. chevre.cs.wisc.
Removing a Job from the Queue
You can remove a job from the queue at any time using the condor_rm command. If the job that is being removed is currently running, the job is killed without a checkpoint, and its queue entry is removed. The following example shows the queue of jobs before and after a job is removed.
% condor_q -- Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 125.0 jbasney 4/10 15:35 0+00:00:00 I -10 1.2 hello.remote 132.0 raman 4/11 16:57 0+00:00:00 R 0 1.4 hello 2 jobs; 1 idle, 1 running, 0 held % condor_rm 132.0 Job 132.0 removed. % condor_q -- Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 125.0 jbasney 4/10 15:35 0+00:00:00 I -10 1.2 hello.remote 1 jobs; 1 idle, 0 running, 0 held
Changing the Priority of Jobs
In addition to the priorities assigned to each user, Condor provides users with the capability of assigning priorities to any submitted job. These job priorities are local to each queue and range from -20 to +20, with higher values meaning better priority.
The default priority of a job is 0. Job priorities can be modified using the condor_prio command. For example, to change the priority of a job to -15, type
% condor_q raman -- Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 126.0 raman 4/11 15:06 0+00:00:00 I 0 0.3 hello 1 jobs; 1 idle, 0 running, 0 held % condor_prio -p -15 126.0 % condor_q raman -- Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 126.0 raman 4/11 15:06 0+00:00:00 I -15 0.3 hello 1 jobs; 1 idle, 0 running, 0 held
We emphasize that these job priorities are completely different from the user priorities assigned by Condor. Job priorities control only which one of your jobs should run next; there is no effect whatsoever on whether your jobs will run before another user's jobs.
Determining Why a Job Does Not Run
A specific job may not run for several reasons. These reasons include failed job or machine constraints, bias due to preferences, insufficient priority, and the preemption throttle that is implemented by the condor_negotiator to prevent thrashing. Many of these reasons can be diagnosed by using the -analyze option of condor_q. For example, the following job submitted by user jbasney had not run for several days.
% condor_q -- Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 125.0 jbasney 4/10 15:35 0+00:00:00 I -10 1.2 hello.remote 1 jobs; 1 idle, 0 running, 0 held
Running condor_q's analyzer provided the following information:
% condor_q 125.0 -analyze
-- Submitter: froth.cs.wisc.edu : <128.105.73.44:33847> : froth.cs.wisc.edu
---
125.000: Run analysis summary. Of 323 resource offers,
323 do not satisfy the request's constraints
0 resource offer constraints are not satisfied by this request
0 are serving equal or higher priority customers
0 are serving more preferred customers
0 cannot preempt because preemption has been held
0 are available to service your request
WARNING: Be advised:
No resources matched request's constraints
Check the Requirements expression below:
Requirements = Arch == "INTEL" && OpSys == "IRIX6" &&
Disk >= ExecutableSize && VirtualMemory >= ImageSize
The Requirements expression for this job specifies a platform that does not exist. Therefore, the expression always evaluates to FALSE.
While the analyzer can diagnose most common problems, there are some situations that it cannot reliably detect because of the instantaneous and local nature of the information it uses to detect the problem. The analyzer may report that resources are available to service the request, but the job still does not run. In most of these situations, the delay is transient, and the job will run during the next negotiation cycle.
If the problem persists and the analyzer is unable to detect the situation, the job may begin to run but immediately terminates and return to the idle state. Viewing the job's error and log files (specified in the submit command file) and Condor's SHADOW_LOG file may assist in tracking down the problem. If the cause is still unclear, you should contact your system administrator.
Job Completion
When a Condor job completes (either through normal means or abnormal means), Condor will remove it from the job queue (therefore, it will no longer appear in the output of condor_q) and insert it into the job history file. You can examine the job history file with the condor_history command. If you specified a log file in your submit description file, then the job exit status will be recorded there as well.
By default, Condor will send you an e-mail message when your job completes. You can modify this behavior with the condor_submit "notification" command. The message will include the exit status of your job or notification that your job terminated abnormally.
Job Policy
Condor provides several expressions to control your job while it is in the queue. Condor periodically evaluates these expressions and may perform actions on your behalf, reducing the tedium of managing running jobs.
Condor provides five of these expressions: periodic_hold, periodic_release, periodic_remove, on_exit_hold, and on_exit_remove. The periodic expressions are evaluated every 20 seconds, and the on_exit expressions are evaluated when your job completes, but before the job is removed from the queue. The periodic expressions take precedence over the on_exit requirements, and the hold expressions take precedence over the remove expressions. The periodic expressions are ClassAd expressions, just like the requirements expression introduced in Section 15.1.2. They are added to the job ClassAd via the submit file.
You can use these expressions to automate many common actions. For example, suppose you know that your job will never run for more than an hour, and if it is running for more than an hour, something is probably wrong and will need investigating. Instead leaving your job running on the cluster needlessly, Condor can place your job on hold with the following added to the submit file:
periodic_hold = (ServerStartTime - JobStartDate) > 3600
Or suppose you have a job that occasionally segfaults but you know if you run it again on the same data, chances are it will finish successfully. You can get this behavior by adding this line to the submit file:
on_exit_remove = (ExitBySignal == True) && (ExitSignal != 11)
The above expression will not let the job leave the queue if it exited by a signal and that signal number was 11 (representing segmentation fault). In any other case of the job exting, it will leave the queue.
15.2.4 Submitting Different Types of Jobs: Choosing a Universe
A Universe in Condor defines an execution environment. Condor supports the following Universes on Linux:
-
Vanilla
-
Parallel
-
PVM
-
Globus
-
Scheduler
-
Java
-
Standard
The Universe attribute is specified in the submit description file. If the Universe is not specified, it will default to Standard.
Vanilla Universe
The Vanilla Universe is used to run serial (nonparallel) jobs. The examples provided in the preceding section use the Vanilla Universe. Most Condor users prefer to use the Standard Universe to submit serial jobs because of several helpful features of the Standard Universe. However, the Standard Universe has several restrictions on the types of serial jobs supported. The Vanilla Universe, on the other hand, has no such restrictions. Any program that runs outside of Condor will run in the Vanilla Universe. Binary executables as well as scripts are welcome in the Vanilla Universe.
A typical Vanilla Universe job relies on a shared file system between the submit machine and all the nodes in order to allow jobs to access their data. However, if a shared file system is not available, Condor can transfer the files needed by the job to and from the execute machine. See Section 15.2.5 for more details on this.
Parallel Universe
The Parallel Universe allows parallel programs written with MPI to be managed by Condor. To submit an MPI program to Condor, specify the number of nodes to be used in the parallel job. Use the machine_count attribute in the submit description file to specify the number of resources to claim, as in the following example:
# Submit file for an MPI job which needs 8 large memory nodes universe = parallel executable = my-parallel-job requirements = Memory >= 512 machine_count = 8 queue
Further options in the submit description file allow a variety of parameters, such as the job requirements or the executable to use across the different nodes.
The start up of parallel jobs can be a complicated procedure, and each parallel library is different. The Condor parallel universe tries to provide enough flexibility to allow jobs linked with any parallel library to be scheduled and launched. Jobs under the parallel universe are allowed to run a script before a process is started on any node, and Condor provides tools to start processes on other nodes. Condor includes all the necessary scripts to support the most common MPI implementations, such as MPICH, MPICH2 and LAM. By default, Condor expects a parallel job to be linked with the MPICH implementation of MPI configured with the ch_p4 device. For other parallel libraries, the Condor manual contains directions on how to write the necessary scripts.
If your Condor pool consists of both dedicated compute machines (that is, Beowulf cluster nodes) and opportunistic machines (that is, desktop workstations), by default Condor will schedule MPI jobs to run on the dedicated resources only.
PVM Universe
Several different parallel programming paradigms exist. One of the more common is the "master/worker" or "pool of tasks" arrangement. In a master/worker program model, one node acts as the controlling master for the parallel application and sends out pieces of work to worker nodes. The worker node does some computation and sends the result back to the master node. The master has a pool of work that needs to be done, and it assigns the next piece of work out to the next worker that becomes available.
The PVM Universe allows master/worker style parallel programs written for the Parallel Virtual Machine interface (see Chapter 10) to be used with Condor. Condor runs the master application on the machine where the job was submitted and will not preempt the master application. Workers are pulled in from the Condor pool as they become available.
Specifically, in the PVM Universe, Condor acts as the resource manager for the PVM daemon. Whenever a PVM program asks for nodes via a pvm_addhosts() call, the request is forwarded to Condor. Using ClassAd matching mechanisms, Condor finds a machine in the Condor pool and adds it to the virtual machine. If a machine needs to leave the pool, the PVM program is notified by normal PVM mechanisms, for example, the pvm_notify() call.
A unique aspect of the PVM Universe is that PVM jobs submitted to Condor can harness both dedicated and nondedicated (opportunistic) workstations throughout the pool by dynamically adding machines to and removing machines from the parallel virtual machine as machines become available.
Writing a PVM program that deals with Condor's opportunistic environment can be a tricky task. For that reason, the MW framework has been created. MW is a tool for making master-worker style applications in Condor's PVM Universe. For more information, see the MW Home page online at www.cs.wisc.edu/condor/mw.
Submitting to the PVM Universe is similar to submitting to the MPI Universe, except that the syntax for machine_count is different to reflect the dynamic nature of the PVM Universe. Here is a simple sample submit description file:
# Require Condor to give us one node before starting # the job, but we'll use up to 75 nodes if they are # available. universe = pvm executable = master.exe machine_count = 1..75 queue
By using machine_count = <min>..<max>, the submit description file tells Condor that before the PVM master is started, there should be at least <min> number of machines given to the job. It also asks Condor to give it as many as <max> machines.
More detailed information on the PVM Universe is available in the Condor manual as well as on the Condor-PVM home page at URL www.cs.wisc.edu/condor/pvm.
Globus Universe
The Globus Toolkit? is available from www.globus.org and is the most popular (although not the only) collection of middleware to build computational grids. The Globus universe in Condor is intended to provide the standard Condor interface to users who wish to submit jobs to machines being managed by Globus. Instead of the jobs executing in the Condor pool, jobs in the Globus universe specify which resource the user wants and has authorization to use. The benefits for running Globus jobs in Condor are that all the Condor job management, such as persistent logging, file management, and the DAGMan ( 15.2.6) meta-scheduler are available.
The Globus universe is not the only way to share resources in Condor. The Condor manual has a section entitled "Grid Computing" that describes Condor Flocking, Condor Glide-in, and the Globus universe in much more detail.
Scheduler Universe
The Scheduler Universe is used to submit a job that will immediately run on the submit machine, as opposed to a remote execution machine. The purpose is to provide a facility for job meta-schedulers that desire to manage the submission and removal of jobs into a Condor queue. Condor includes one such meta-scheduler that utilizes the Scheduler Universe: the DAGMan scheduler, which can be used to specify complex interdependencies between jobs. See Section 15.2.6 for more on DAGMan.
Java Universe
There is growing interest in writing scientific programs in Java, and Condor provides special support for running Java programs in a pool. Java programs are not loaded directly by the operating system and run on the processor. Instead, they are loaded by the Java Virtual Machine(JVM) and interpreted. This allows the same Java program to run on any operating system and hardware combination at the cost of reduced performance.
One inelegant way to run Java programs in a Condor pool is to submit the JVM to the Standard or Vanilla universe, and give the Java program to be run as an argument. This is deficient in two ways. For one, it puts considerable burdens on users who want to take advantage the platform independence that Java provides. Additionally, it is difficult to determine the cause of errors when a job fails, as the error may be from the JVM or from the Java program running on the JVM.
The Java Universe changes the abstraction of a remote resource from a Linux machine to a Java environment. If a resource has a JVM installed, Condor advertises facts about the JVM such as versions and performance benchmarks. When a Java universe job is matched with a resource, Condor assumes responsibility of running the Java program. This allows specialized JVMs to be deployed by the resource administrator and removes the burden of providing a suitable execution environment from the submitter. If an error occurs, Condor can detect if the error occurred in the job or in the JVM. If the error is from the JVM, Condor automatically retries the job. If the error is from the job, Condor can report directly into the job logfile what the exception was and where it occurred. A sample Java submit file appears in Figure 15.3.
# Submit file for an Java job which prefers the fastest JVM in the pool universe = java executable = my-java-sim.class jar_files = simulation_library.jar arguments = -x 100 -y 100 output = simulation.out log = simulation.log rank = JavaMFlops * 100 queue
Figure 15.3: A sample Java submit file.
Standard Universe
The Standard Universe requires minimal extra effort on the part of the user but provides a serial job with the following highly desirable services:
-
Transparent process checkpoint and restart
-
Transparent process migration
-
Remote system calls
-
Configurable file I/O buffering
-
On-the-fly file compression/inflation
Process Checkpointing in the Standard Universe
A checkpoint of an executing program is a snapshot of the program's current state. It provides a way for the program to be continued from that state at a later time. Using checkpoints gives Condor the freedom to reconsider scheduling decisions through preemptive-resume scheduling. If the scheduler decides to rescind a machine that is running a Condor job (for example, when the owner of that machine returns and reclaims it or when a higher-priority user desires the same machine), the scheduler can take a checkpoint of the job and preempt the job without losing the work the job has already accomplished. The job can then be resumed later when the Condor scheduler allocates it a new machine. Additionally, periodic checkpoints provide fault tolerance. Normally, when performing long-running computations, if a machine crashes or must be rebooted for an administrative task, all the work that has been done is lost. The job must be restarted from the beginning, which can mean days, weeks, or even months of wasted computation time. With checkpoints, Condor ensures that progress is always made on jobs and that only the computation done since the last checkpoint is lost. Condor can be take checkpoints periodically, and after an interruption in service, the program can continue from the most recent snapshot.
To enable taking checkpoints, you do not need to change the program's source code. Instead, the program must be relinked with the Condor system call library (see below). Taking the checkpoint of a process is implemented in the Condor system call library as a signal handler. When Condor sends a checkpoint signal to a process linked with this library, the provided signal handler writes the state of the process out to a file or a network socket. This state includes the contents of the process's stack and data segments, all CPU state (including register values), the state of all open files, and any signal handlers and pending signals. When a job is to be continued using a checkpoint, Condor reads this state from the file or network socket, restoring the stack, shared library and data segments, file state, signal handlers, and pending signals. The checkpoint signal handler then restores the CPU state and returns to the user code, which continues from where it left off when the checkpoint signal arrived. Condor jobs submitted to the Standard Universe will automatically perform a checkpoint when preempted from a machine. When a suitable replacement execution machine is found (of the same architecture and operating system), the process is restored on this new machine from the checkpoint, and computation is resumed from where it left off.
By default, a checkpoint is written to a file on the local disk of the submit machine. A Condor checkpoint server is also available to serve as a repository for checkpoints.
Remote System Calls in the Standard Universe
One hurdle to overcome when placing an job on a remote execution workstation is data access. In order to utilize the remote resources, the job must be able to read from and write to files on its submit machine. A requirement that the remote execution machine be able to access these files via NFS, AFS, or any other network file system may significantly limit the number of eligible workstations and therefore hinder the ability of an environment to achieve high throughput. Therefore, in order to maximize throughput, Condor strives to be able to run any application on any remote workstation of a given platform without relying upon a common administrative setup. The enabling technology that permits this is Condor's Remote System Calls mechanism. This mechanism provides the benefit that Condor does not require a user to possess a login account on the execute workstation.
When a Unix process needs to access a file, it calls a file I/O system function such as open(), read(), or write(). These functions are typically handled by the standard C library, which consists primarily of stubs that generate a corresponding system call to the local kernel. Condor users link their applications with an enhanced standard C library via the condor_compile command. This library does not duplicate any code in the standard C library; instead, it augments certain system call stubs (such as the ones that handle file I/O) into remote system call stubs. The remote system call stubs package the system call number and arguments into a message that is sent over the network to a condor_shadow process that runs on the submit machine. Whenever Condor starts a Standard Universe job, it also starts a corresponding shadow process on the initiating host where the user originally submitted the job (see Figure 15.4). This shadow process acts as an agent for the remotely executing program in performing system calls. The shadow then executes the system call on behalf of the remotely running job in the normal way. The shadow packages up the results of the system call in a message and sends it back to the remote system call stub in the Condor library on the remote machine. The remote system call stub returns its result to the calling procedure, which is unaware that the call was done remotely rather than locally. In this fashion, calls in the user's program to open(), read(), write(), close(), and all other file I/O calls transparently take place on the machine that submitted the job instead of on the remote execution machine.
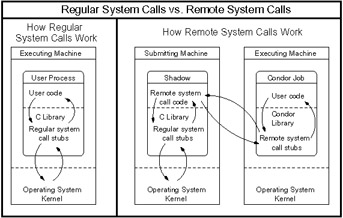
Figure 15.4: Remote System calls in the Standard Universe.
Relinking and Submitting for the Standard Universe
To convert a program into a Standard Universe job, use the condor_compile command to relink with the Condor libraries. Place condor_compile in front of your usual link command. You do not need to modify the program's source code, but you do need access to its unlinked object files. A commercial program that is packaged as a single executable file cannot be converted into a Standard Universe job.
For example, if you normally link your job by executing
% cc main.o tools.o -o program
You can relink your job for Condor with
% condor_compile cc main.o tools.o -o program
After you have relinked your job, you can submit it. A submit description file for the Standard Universe is similar to one for the Vanilla Universe. However, several additional submit directives are available to perform activities such as on-the-fly compression of data files. Here is an example:
# Submit 100 runs of my-program to the Standard Universe universe = standard executable = my-program.exe # Each run should take place in a separate subdirectory: run0, run1, ... initialdir = run$(Process) # Ask the Condor remote syscall layer to automatically compress # on-the-fly any writes done by my-program.exe to file data.output compress_files = data.output queue 100
Standard Universe Limitations
Condor performs its process checkpoint and migration routines strictly in user mode; there are no kernel drivers with Condor. Because Condor is not operating at the kernel level, there are limitations on what process state it is able to checkpoint. As a result, the following restrictions are imposed upon Standard Universe jobs:
-
Multiprocess jobs are not allowed. This includes system calls such as fork(), exec(), and system().
-
Interprocess communication is not allowed. This includes pipes, semaphores, and shared memory.
-
Network communication must be brief. A job may make network connections using system calls such as socket(), but a network connection left open for long periods will delay checkpoints and migration.
-
Multiple kernel-level threads are not allowed. However, multiple user-level threads (green threads) are allowed.
-
All files should be accessed read-only or write-only. A file that is both read and written to can cause trouble if a job must be rolled back to an old checkpoint image.
-
On Linux, your job must be statically linked. Dynamic linking is allowed in the Standard Universe on some other platforms supported by Condor, and perhaps this restriction on Linux will be removed in a future Condor release.
15.2.5 Giving Your Job Access to Its Data Files
Once your job starts on a machine in your pool, how does it access its data files? Condor provides several choices.
If the job is a Standard Universe job, then Condor solves the problem of data access automatically using the Remote System call mechanism described above. Whenever the job tries to open, read, or write to a file, the I/O will actually take place on the submit machine, whether or not a shared file system is in place.
Condor can use a shared file system, if one is available and permanently mounted across the machines in the pool. This is usually the case in a Beowulf cluster. But what if your Condor pool includes nondedicated (desktop) machines as well? You could specify a Requirements expression in your submit description file to require that jobs run only on machines that actually do have access to a common, shared file system. Or, you could request in the submit description file that Condor transfer your job's data files using the Condor File Transfer mechanism.
When Condor finds a machine willing to execute your job, it can create a temporary subdirectory for your job on the execute machine. The Condor File Transfer mechanism will then send via TCP the job executable(s) and input files from the submitting machine into this temporary directory on the execute machine. After the input files have been transferred, the execute machine will start running the job with the temporary directory as the job's current working directory. When the job completes or is kicked off, Condor File Transfer will automatically send back to the submit machine any output files created or modified by the job. After the files have been sent back successfully, the temporary working directory on the execute machine is deleted.
Condor's File Transfer mechanism has several features to ensure data integrity in a nondedicated environment. For instance, transfers of multiple files are performed atomically.
Condor File Transfer behavior is specified at job submission time using the submit description file and condor_submit. Along with all the other job submit description parameters, you can use the following File Transfer commands in the submit description file:
-
transfer_input_files = < file1, file2, file... >: Use this parameter to list all the files that should be transferred into the working directory for the job before the job is started.
-
transfer_output_files = < file1, file2, file... >: Use this parameter to explicitly list which output files to transfer back from the temporary working directory on the execute machine to the submit machine. Most of the time, however, there is no need to use this parameter. If transfer_output_files is not specified, Condor will automatically transfer in the job's temporary working directory all files that have been modified or created by the job.
-
transfer_files = <ONEXIT | ALWAYS | NEVER>: If transfer_files is set to ONEXIT, Condor will transfer the job's output files back to the submitting machine only when the job completes (exits). Specifying ALWAYS tells Condor to transfer back the output files when the job completes or when Condor kicks off the job (preempts) from a machine prior to job completion. The ALWAYS option is specifically intended for fault-tolerant jobs that periodically write out their state to disk and can restart where they left off. Any output files transferred back to the submit machine when Condor preempts a job will automatically be sent back out again as input files when the job restarts.
15.2.6 The DAGMan Scheduler
The DAGMan scheduler within Condor allows the specification of dependencies between a set of programs. A directed acyclic graph (DAG) can be used to represent a set of programs where the input, output, or execution of one or more programs is dependent on one or more other programs. The programs are nodes (vertices) in the graph, and the edges (arcs) identify the dependencies. Each program within the DAG becomes a job submitted to Condor. The DAGMan scheduler enforces the dependencies of the DAG.
An input file to DAGMan identifies the nodes of the graph, as well as how to submit each job (node) to Condor. It also specifies the graph's dependencies and describes any extra processing that is involved with the nodes of the graph and must take place just before or just after the job is run.
A simple diamond-shaped DAG with four nodes is given in Figure 15.5.

Figure 15.5: A directed acyclic graph with four nodes.
A simple input file to DAGMan for this diamond-shaped DAG may be
# file name: diamond.dag Job A A.condor Job B B.condor Job C C.condor Job D D.condor PARENT A CHILD B C PARENT B C CHILD D
The four nodes are named A, B, C, and D. Lines beginning with the keyword Job identify each node by giving it a name, and they also specify a file to be used as a submit description file for submission as a Condor job. Lines with the keyword PARENT identify the dependencies of the graph. Just like regular Condor submit description files, lines with a leading pound character (#) are comments.
The DAGMan scheduler uses the graph to order the submission of jobs to Condor. The submission of a child node will not take place until the parent node has successfully completed. No ordering of siblings is imposed by the graph, and therefore DAGMan does not impose an ordering when submitting the jobs to Condor. For the diamond-shaped example, nodes B and C will be submitted to Condor in parallel.
Each job in the example graph uses a different submit description file. An example submit description file for job A may be
# file name: A.condor
executable = nodeA.exe
output = A.out
error = A.err
log = diamond.log
universe = vanilla
queue
An important restriction for submit description files of a DAG is that each node of the graph use the same log file. DAGMan uses the log file in enforcing the graph's dependencies.
The graph for execution under Condor is submitted by using the Condor tool condor_submit_dag. For the diamond-shaped example, submission would use the command
condor_submit_dag diamond.dag







