20.2 Jazz - A New Production Cluster
20.2 Jazz—A New Production Cluster
In 2002, Argonne determined that the Laboratory had a need for a production computing facility that would support the computing needs of scientists and engineers around the Lab. The Lab's Computational Science Advisory Committee discussed and studied the situation in detail and determined that a Linux cluster would be the appropriate way to satisfy the majority of the Lab's scientific computing requirements. Unlike Chiba City, which was limited to computer scientists and collaborators, this new cluster would be available to anyone at the Lab.
Thus, in October, we installed "Jazz," a 350-node Linux cluster purchased from Linux NetworX. Jazz achieved just over a teraflop on sustained Linpack benchmarks, putting it in the top 50 of the world's fastest supercomputers (or at least those that had been registered on the list). Although our goal had only been to install a cost-effective and efficient mid-range computer, it was interesting to see what it took to land towards the top of the top 500 list. A far more interesting fact was that we had a lot of company. The entire list, including the upper echelon, was loaded with clusters running Linux. Since we had installed Chiba City a mere three years earlier, the world of high-end computing had bought into (or been consumed by) Linux clusters in a serious way.
20.2.1 Different Worlds
While our plans for Jazz were built on our experience with Chiba City, we found that designing, installing, and running Jazz was quite different for a number of reasons.
First, the entire field of cluster computing on Linux had matured substantially. It was now possible to go to many different vendors and request some flavor of Linux cluster without first explaining what Linux was, why we wanted it, and how clusters worked. Vendors had experience with installing clusters. They had custom software suites, often built on open-source tools, for managing clusters.
That said, we found that buying a Linux cluster was still more complicated than buying an IBM SP or an SGI Origin 2000 simply because of the range of choices in hardware, interconnect, storage and software. One might say that buying an established supercomputer is a lot like buying a condo—you don't have any choice about where the walls go, but you choose your own furniture. In contrast, buying a Linux cluster today is like buying a house that hasn't been built yet. You sit down with the blueprints and the architect and discuss where to put toilets and whether or not to have a fourth bedroom.
A second reason that the experience was different was simply because the hardware had changed substantially in three years. Rather than looking at 500 MHz Pentium IIIs in a 2U case, we were looking at 2.4 GH Pentium IVs in a sub-1U case. This, of course, is something we've all grown to expect, but it's still entertaining. While the impact of Moore's Law is one of the main economic forces behind the technology industry, one could still make an argument that it's always better to delay your purchase by six months, when everything will be faster and cheaper.
Finally, and perhaps most importantly, Jazz was different then Chiba City because it was built for a different purpose.
20.2.2 Mission and Design
Jazz was designed from the outset to support serious production computing for a wide-range of users, namely the Argonne scientific computing community. Argonne is somewhat like a university campus in that it is divided into departments (or divisions, in Argonne's case) that operate relatively independently. For example, there's a chemistry division, a physics division, and a lot of engineering divisions. Overall there are over thirty different divisions at Argonne, and Jazz was meant to be a technical computing resource for all of them.
Therefore, unlike Chiba City, Jazz was meant to be a "production" resource. It needed to perform well on a mix of code. It needed to be stable. We needed to make sure we had a happy user community, so we had to be helpful, answer questions, solve problems, and not crash the machine by trying out the latest Linux kernel to check out cool new features.
The need to be a production facility impacted the design in a number of ways:
-
As part of the initial planning, we carried out a lot of benchmarks and testing on available systems using code that we expected to use on the system. We verified what we already knew—in most cases, application performance was directly related to the performance of the memory system. Anything that could be done to avoid memory bottlenecks and speed up memory was likely to be worth it. As a result, we decided to use nodes with just one CPU—the last thing we needed were multiple CPUs fighting over the memory bus, even if the price/performance ratio looked better on multiple CPU systems. We also decided to go with the best memory technology that we could afford. Benchmarks with Rambus were much better than the same tests with slower memory.
-
We also knew from a survey of the application community that many of the applications were bound by the size of physical memory on a node. Thus we needed to try to maximize the amount of memory within budget constraints.
-
Although we didn't expect every user to be running code that relied heavily on communications performance, we knew that many would, so we planned again on having a high-performance interconnect for the cluster.
-
As described earlier, we knew from our experience with Chiba City that a global file system was essential. We knew that we had to have some way of having exactly the same file namespace on all nodes, even if the I/O performance on those files were bad.
-
We also knew that the highest-performing code required fast I/O but could live with variable reliability for the sake of speed. Thus we expected that we would likely to have to have at least two different file systems installed (like our older SPs had had): a slow, global, reliable home file system, and a fast parallel file system.
-
We'd had no end of troubles with OpenPBS on Chiba City, so we decided to use a more current resource manager. After surveying the options, we ended up buying PBS Pro.
-
We knew that the system would require more human effort to support applications and operate in production mode for a large community than a cluster for a small number of users or purposes. Thus we planned on hiring four or five system administrators and application engineers.
-
With a lot of users, and when allocating time on the machine to projects, the account and project system becomes a critical part of the infrastructure. We therefore anticipated that the time for "early user mode" would take longer than on previous systems, as we would be getting the allocation system working during that time.
-
Being production means being fairly consistent. Because we expected to keep the software installation on the computing nodes relatively constant (as compared to Chiba City, where we load new images continually), we didn't feel that we needed as substantial a management infrastructure. Also, we had carried out a lot of testing of the management functionality of Chiba City, as reported in our team's paper at Cluster 2002 [36]. So, while Jazz still has mayors, it has many fewer than Chiba City did. The irony here is that in order to have a production facility, we felt that we could have fewer management systems, but this has turned out to be true.
-
Finally, we needed the hardware on Jazz to be supported by a vendor. As part of the purchase, we specified that everything needed to have support for at least three years.
As a result, by knowing that we had to run a production facility and understanding the characteristics of the applications fairly well, we had a pretty solid definition of our requirements. In short, we had to have:
-
single-CPU nodes with a lot of fast RAM
-
a fast interconnect
-
a rock-solid, but not necessarily fast, global file system
-
a fast parallel file system
-
reliable systems software
-
good vendor support
This was the list that we took to the cluster vendors. From there, the question was how best to maximize the cluster parameters within our budget.
20.2.3 Architecture
The system that we ended up purchasing is illustrated in Figure 20.9. We purchased this cluster. Jazz, in its entirety from Linux NetworX.
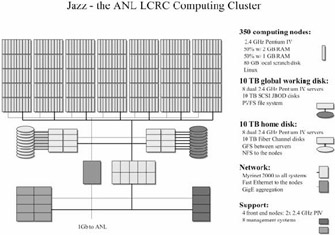
Figure 20.9: Argonne's Jazz Cluster
The cluster consists of:
-
350 computing nodes. Each node has one 2.4 GHz Pentium IV. Half of the nodes have 2 GB of RAM, half have 1 GB. We ended up using DDR RAM for budget reasons after confirming that the performance was sufficient.
-
4 login nodes. These nodes are identical to the computing nodes, except that each has two CPUs and 2 GB of RAM.
-
8 home directory servers and 10 TB of FibreChannel disk. For home directory service, we went with a recommendation made by Linux NetworX and used a combination of GFS and NFS. GFS is a file system product from Sistina. Each of these eight servers has joint access to a large GFS file system shared between them. Each then provides access to that file system to one eigth of the cluster using NFS. In this way, we avoid the scaling problems of NFS while maintaining consistency across all of the NFS servers.
-
8 PVFS servers and 10 TB of JBOD disk. For parallel I/O, we use eight servers running the Parallel Virtual File System exported to the entire cluster. Most users of this file system access it via MPI-IO interfaces.
-
8 management nodes. These nodes share a variety of duties including scheduler and job management, configuration management, monitoring, web services, and so on. As noted above, the management requirements for Jazz are substially lower than those of Chiba City because we rarely change the configuration of the entire system.
-
Myrinet 2000. We selected Myrinet for the fast interconnect for the system because it was proven to scale to clusters this size (and larger), performs well, and wasn't overwhelmingly expensive. We seriously considered Gigabit Ethernet as an alternative, but the cost of well-performing GigE switches is still prohibitive, and the reliability of some GigE NICs under Linux is a problem.
-
Fast Ethernet. Even with Myrinet, we felt that we need a rock-solid network for management and applications to fall back onto.
For management purposes such as remote power control and console management, Linux NetworX provided a proprietary solution—the ICEbox, which fulfilled the functionality of a collection of similar hardware that we'd found incredibly handy on Chiba City.
20.2.4 Installation
It's interesting to understand precisely what you're getting when you buy a cluster. The vendors are striving to be able to provide a turn-key system, but the definition of "turn-key" changes rather dramatically between a cluster that runs one application and a cluster than runs hundreds. We didn't expect to have a system that worked with no modification, nor did we expect to be handed 350 computers with no operating system, but we weren't sure where in the middle things would land.
On the hardware side, having installed a 256-node cluster ourselves, we had no particular desire to build a 350-node cluster. Fortunately, this was one of the many things that the vendors had taken on, and learned to do quite well, since we'd had the Chiba City barnraising. Linux NetworX installed Jazz without substantial help from us, although we needed to be involved from time-to-time to handle power attachments, floor space issues, cable routing decisions, and so on.
On the software side, it turns out that it would have been possible for us to stay similarly uninvolved. We would have ended up with Linux installed on every node, an environment for parallel computing that had MPI and PVM installed, the global file systems built, and Linux NetworX's "ClusterWorX" management software that could be used to build and configure nodes. This was substantially more than we could have imagined when installing Chiba City three years earlier, and was quite excellent in and of itself.
However, to run a production computing environment, we had to do quite a lot more work, such as installing extra software, building the user environment, building the allocation mechanisms, installing bug and request tracking systems, and adding our favorite set of management tools. Fortunately, the Linux NetworX folks understood that we were in a rush, so while they were working on software installs, we had joint access to the machine. We ended up working together on a lot of the detailed configuration.
As it turns out, it was very important for us to be involved during the software installation, because we needed to become very familiar with the configuration of the machine as a part of taking ownership of it. Also, there were several situations where we were able to ask the vendor to do things differently then they normally would have in order to accomodate our specific needs.
20.2.5 Software Environment
While it's not feasible to list the entire set of software packages that are installed on the cluster in this space, it is useful to describe the more essential tools available to users of the system.
This list of software refers to the software installed on the login nodes, which is where the users do the bulk of their work. The compute nodes have fully-populated Linux installations and all of the tools that might be necessary to have on compute nodes (such as libraries) but don't necessarily have every tool installed on them.
The Base Installation
-
RedHat 7.2
-
All the tools and languages you'd expect in a reasonable UNIX-based environment including X11, Perl, Python, the GNU tools, CVS, Bitkeeper, and so on.
The Development Environment
|
ABSoft Compilers |
MPICH - multiple versions |
|
NAG Compilers and Libraries |
ROMIO |
|
Intel Compilers and Libraries |
MPICH-2 |
|
Portland Group Compilers |
Globus |
|
Totalview |
Columbus |
|
IDL |
NetCDF |
|
Matlab |
NCAR |
|
Gaussian |
PETSc |
|
StarCD |
ScaLAPACK |
|
Gnu compilers | ? |
20.2.6 Going Production
When you buy a large machine from a vendor, one of the first major transition points in the lifecycle of that system is when the machine is turned over to you from the vendor. In our case, this happened after Linux NetworX had finished building the machine, installing the base software with a number extensions, configuring the file systems, teaching us about the tools that they delivered, and passing a number of tests confirming that the machine was operating correctly. While it was great to finally get to this point, our work was really just starting.
If this machine were going to run only a few applications or support only a few users, we could have started doing so immediately. Enough of the software was installed and enough of the system configured that we could have started using it for parallel jobs at this point. However, in order to turn it into a multi-user, multi-project resource, we had quite a few more things to complete.
For the next two months, we kept the system in "Configuration and Testing mode". During this time, we installed the majority of the programs listed in the previous section. We installed the Maui scheduler to work in conjunction with PBS Pro, and spent a lot of time configuring those. We began to create web pages with information for the user community. We put in an initial user account creation system, and began to slowly add users to the system. These were users who we knew would be comfortable on large and potentially unstable machines, users who could put the machine through its paces and give us lots of feedback on how it was working, what was missing, and so on. By the time we were done with this phase of testing, we probably had about ten user accounts on the system.
Once the system was relatively stable, we entered "Early User mode". At this point, we added accounts for anyone who asked, with the caveat that we were still specifically asking for feedback and that the machine might be taken down at any point to fix problems or reconfigure things. The bulk of our own effort at this point, beyond responding to user issues, was to focus on the account creation system and the allocation tracking system. (That said—responding to user issues took a huge amount of time.) In our division, we already have a comprehensive user account management system. We extended it to include the Jazz system, and then created web pages so that anyone at the Laboratory could easily request an account specific to Jazz and use those web pages to manage their account.
Like most multi-user production facilities, we planned for Jazz to be formally allocated. We had an allocations committee that would be making decisions about which projects at the Laboratory would be able to use the system and what percentage of the machine would be available to each project. The committee met several times to discuss allocation and scheduling policies, and our job was to make sure that those allocation policies could be implemented on the system. We used the "QBank" software [92], created by Pacific Northwest National Laboratory, to manage allocations.
After three months of Early User Mode, the cluster was stable, the majority of requested software was configured and installed, we had a fairly good start at the web-based documentation, and the account and allocation system was working. We were ready to shift formally into production mode.
We held a ribbon-cutting ceremony to mark the occasion, at which the Laboratory Director, Dr. Hermann Grunder, spoke and helped cut a ceremonial ribbon cable.
From this point onwards, we opened up the cluster to access by the entire Laboratory community and began to track allocations. Based on the policies set the allocations committee, any user at Argonne who got an account would be given 1000 CPU hours of initial startup time. To compute for longer than that, a user would need to submit a project request that explained the project in fairly substantial detail. The committee would then determine how much time on the machine to allocate—times of 20,000 hours and more are currently typical. Although we have the option of stopping any project that has run beyond its allocation, we're currently taking the more friendly approach of warning those projects that they're exceeding their allocated time and discussing the usage of the system with the allocations board. As the user community and usage on Jazz expands, this will no doubt become a more complex issue.
20.2.7 Jazz Status and Futures
Jazz is now really at the beginning of its life cycle. At the time of this writing, it has been in production mode for only a few months. Use of the cluster is expanding regularly, and we will begin outreach efforts across the Laboratory shortly.
Response from the user community has been exceptionally positive. The individual nodes are fast and responsive—the Pentium IVs and the memory system compare well to all other systems currently out there, although this will of course change as new technology is rolled out. The entire cluster is solid and reliable.
Although we are still early in the project, we can identify a number of essential bits of information that we have learned or confirmed:
-
Both GFS and PVFS are working well. Having a global file system is proving to be just as critical as we had thought it would be.
-
We're generally happy with the way that the vendors have embraced Linux clusters. Designing and purchasing this system was far simpler then what we went through with Chiba City, and the vendor handled installation and followup support quite well. Obviously, the experience of others in this case will depend on who their specific vendor is, but the point here is that there are now a number of professionals in the business who are doing a good job of this.
-
That said, these clusters are still not simple. We've had some very serious headaches with the networks, the file systems, the schedulers, and in configuring the environment. We've overcome all of these (for the moment), but the situation is not yet optimal, and is nowhere near turn-key.
-
Adequate and experienced staffing is essential. We have had the equivalent of three system administrators working full-time (and then some) on this project since its inception. Among the staff are people with experience on large-scale parallel computers, strong Linux backgrounds, and networking skills. As the user community grows, we are adding people who can focus on supporting applications with porting, parallelizing, and tuning code, as well as running seminars and tutorials. This is essential to the success of a production facility for a large user community.
We hope that Jazz, in its current configuration, will meet the needs of the Argonne computing community for the next three years. Our development and expansion focus during that time will be on application support and capabilities. If Jazz is operating correctly as a production facility, it will simply continue to work smoothly through the efforts of the systems administration team. Based on our experiences thus far with Jazz and with Linux clusters in general, we're confident that this goal is within reach.







