19.2 Parallel File System Architectures
19.2 Parallel File System Architectures
Numerous parallel I/O systems have been built, although few have seen wide use. If we look at these file systems we do see trends in how the systems are designed. The architecture of these systems, both hardware and software, can have a significant effect on application performance, particularly with the demanding access characteristics of scientific applications.
We discuss the two most common architectures, including the components of the systems and some of the key characteristics. These architectures serve as a starting point for discussion of specific parallel file systems. For each architecture we give three example file systems, all of which have run on Linux at one time or another, and all of which have had an impact on parallel I/O systems of today.
19.2.1 Shared Storage Architectures
File systems relying on a shared storage architecture are the most popular approach for large production systems. The reason rests at least in part on the popularity of storage area networks (SANs) and fibre channel (FC) storage. File systems using shared storage have the common feature of accessing block devices remotely, either through direct attach hardware (such as FC disks) or through intermediate I/O servers that provide a block-oriented interface to disks attached locally to the server. In either case, a key component of these systems is a locking subsystem. The locking subsystem is necessary to coordinate access to these shared resources. While we will not discuss the issue of fault tolerance with respect to the locking subsystems of the example file systems, we note that a significant amount of effort has been put forth to ensure that locks can be recovered from failed nodes. This is a complicated problem, and the cited works discuss the issues in detail.
Some file systems that use shared storage implement a "virtual block device" in order to separate the access of logical blocks of data from their physical representation on storage. This virtual block device provides a mapping from logical blocks to physical storage. A file system component builds on this to provide the directory hierarchy for the file system, just as a local file system builds on a disk or RAID volume. This approach is advantageous from a system management point of view. The virtual block device, because it abstracts away physical data location, can provide facilities for data migration and replication transparent to the upper layers of the system. This approach simplifies the implementation of the upper level components. Further, this virtual block device provides a mechanism for adding and removing hardware while the system runs. Data blocks can be migrated off a device before removal and can later be moved onto a newly installed device. This capability is very valuable in systems that must provide high availability.
The abstraction is, however, limiting in some ways as well. First, all file system accesses must be translated to block accesses before hitting this component. Because scientific applications often have noncontiguous access patterns, this approach can result in read/modify/write patterns that could have been avoided if more fine-grained accesses were allowed. Second, control over physical data locations is lost to the upper layers. While few scientific applications currently try to perform careful block placement for performance reasons, this could be an issue as groups attempt to further push the boundaries of I/O performance. Finally, this additional level of indirection adds overhead in the system, increasing the latency of operations.
A number of systems are available with this architecture. The first two example systems that we cover, Frangipani and GFS, rely on virtual block devices. The last, GPFS, uses a slightly different organization. SGI's CXFS file system, not discussed here, has a similar architecture to GFS.
Frangipani and Petal
The Frangipani and Petal systems, originally developed at Digital Equipment Corporation (DEC), together form a good example of the virtual block device approach. The Petal [65] component implements a virtual block device with replication, snapshotting, and hot swapping of devices. It presents a simple RPC-like API for atomically reading and writing blocks that higher-level components can use to build a file system. The Petal component runs on nodes that have attached storage. Instances of the Petal component communicate to manage these devices, as not all Petal instances can directly access all the devices that make up the virtual block device.
The Frangipani [118] component implements a distributed file system on top of Petal. A distributed locking component is used by Frangipani to manage consistency. Locks are multiple-reader, single-writer and are granted on a per file basis. Locks are "sticky"; clients hold onto locks until asked to release them by the locking subsystem, allowing for read and write caching at the client side. The Frangipani component runs on nodes that access the shared storage region. Instances of the Frangipani component do not communicate with each other, only the locking component and Petal.
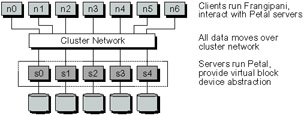
Figure 19.3: Frangipani and Petal File System Architecture
This architecture provides us with a good opportunity to introduce a common term in distributed file systems. A system can be considered a serverless distributed file system if nodes work together as peers to provide a shared storage region, as opposed to some specific server or servers providing this functionality [5]. When the term was coined back in the mid-1990s, systems weren't particularly large (the referenced paper tested on 32 nodes), and the point was really to distribute both metadata and data across multiple nodes more than to actually use every node as a storage resource.
In any case, it's easy to imagine that the Frangipani and Petal approach could be used in this "serverless" mode with Petal running on all clients, or it could be used in a system with a collection of heavy-duty servers with RAID arrays running Petal, with most nodes running only Frangipani. Without knowing more about a particular architecture, it's not clear which of these would be the right choice.
Frangipani and Petal are an early and well-documented example of this architecture. The Frangipani and Petal code is still around, although obtaining it seems difficult. At the time of writing rumor was that the code has been ported to Linux 2.4 and is floating around at one of the major hardware vendors. Perhaps it will pop up again to compete with some of the currently available systems.
GFS
The Global File System (GFS) was originally developed at Minnesota and is now developed and supported by Sistina [89, 88]. GFS is actively maintained and improved by Sistina. An older version of the source code, originally released under the GPL, is also available under the name OpenGFS. GFS also uses a virtual block device architecture, in this case using LVM (Logical Volume Manager) underneath the GFS file system layer.
GFS currently uses a "Pool" driver to organize storage devices into a logical space. They are investigating the use of LVM [52], a newer system for organizing multiple physical storage devices into "volume groups" and then partitioning these into "logical volumes," which are the virtual equivalent of partitions on a disk. Just as with Petal, the Pool driver (and eventually LVM) provides capabilities for snapshotting and hot swapping of devices. The typical installation of GFS uses some number of nodes connected to shared fibre channel storage, with all nodes running both the LVM and GFS software (making it serverless). Alternatively a GNBD component can be used to provide remote access to a storage device over IP. This is similar to the VSD component in GPFS, which will be discussed in the next section.
GFS stores data as blocks on this virtual block device. A locking subsystem, OmniLock, provides the locking infrastructure necessary to ensure consistency. A number of locking modules are available with OmniLock allowing the locking granularity to be tuned to match expected workloads. Locks are sticky here as well, again allowing for read and write caching of data at the client.
GPFS
The General Parallel File System (GPFS) from IBM grew out of the Tiger Shark multimedia file system [100] and has been widely used on the AIX platform. Unlike the other file systems described, GPFS has no explicit virtual block device component. Instead GPFS simply uses one of two techniques for accessing block devices remotely and manages these devices itself. IBM's Virtual Shared Disk (VSD) component allows storage devices attached to multiple I/O nodes to be accessed remotely. VSD is different from the previous two approaches in that no logical volume management is performed at this level; it just exports an API to allow access to the devices. Alternatively, the VSD component can be avoided by attaching all nodes that wish to access the system to a SAN that gives them direct access to storage devices (Figure 19.4). This can be an expensive solution for large clusters, thus the existence of the VSD component. The newer Linux version of GPFS uses a similar component, called the Network Shared Disk (NSD), to provide remote access to storage devices.
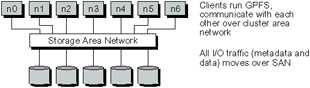
Figure 19.4: GPFS Architecture Using Storage Area Network
In either case, GPFS operates on a shared storage region using block accesses. Because there is no volume management, however, GPFS sees multiple devices. This approach was a conscious decision on the part of the developers to provide the file system with direct control over striping of data across devices. A side effect of this decision is that volume management and fault tolerance capabilities must be handled outside of the VSD, either below the VSD or in GPFS. RAID devices can be used below the VSD layer (or directly attached via the SAN). In addition to or in place of RAID, GPFS also supports data and metadata replication at the file system layer. If this capability is enabled, GPFS will allocate space for a copy of data on a different disk and keep copies synchronized. In the event of a temporary failure, GPFS will continue to operate and will update the device when it is returned to service. Likewise, functionality for migrating data onto new devices or off bad ones is also implemented within GPFS.
GPFS relies on a distributed locking component to guarantee consistency. Similarly to the other two systems, locks are acquired and kept by clients who then cache data. The granularity of locking in GPFS is at the byte-range level (actually rounded to data blocks), so writes to nonoverlapping data blocks of the same file can proceed concurrently.
GPFS provides as an alternative a consistency management system called data shipping. This mode disables the byte-range locks described above. Instead nodes become responsible for particular data blocks, and clients forward data belonging in these blocks to the appropriate node for writing. This approach is similar to the two-phase I/O approach often applied to collective I/O operations [113]. It is more effective than the default locking approach when fine-grained sharing is present, and it forms a building-block optimization for MPI-IO implementations.
The GPFS system also recognizes metadata blocks as distinct from data blocks. A single node that is accessing a file is given responsibility for metadata updates for that file. A multiple-reader, multiple-writer system then is applied to metadata that allows concurrent updates in many circumstances.
GPFS is arguably the most successful parallel file system to date. It is in use on a variety of large parallel machines, such as ASCI White, a 512-node Power3-based system. We note that only 16 I/O server nodes (running VSD) are used in that particular instantiation. At this time GPFS has been made available in a limited fashion on IA32 and IA64 Linux systems but has not seen widespread use on these platforms.
19.2.2 Intelligent Server Architectures
The second common approach to parallel file systems is the use of "intelligent" I/O servers. By this we mean that the servers do more than simply export a block-oriented interface to local storage devices. These systems usually communicate with clients in terms of higher-level constructs, such as files (or parts of files) and directories. Specific operations to act on metadata atomically might be included as well, rather than treating them as data operations as in the previous systems. Further these servers have knowledge that the data they are storing corresponds to particular file system entities (e.g., files or directories), not just arbitrary blocks on a storage device. Hence they have the potential to accept more complex, structured requests than are possible with other approaches. This is a particularly useful capability for scientific applications given their structured file accesses.
Designers of systems using this architecture often logically separate the storage of metadata from the storage of file data. This approach allows for flexibility in configuration because they can choose to handle metadata operations with different servers from the I/O traffic. Because providing distributed metadata services is more complicated than placing metadata in a single location, some systems support only a single metadata server while maintaining many I/O servers. On the other hand, using a single metadata server adds a potential bottleneck, so some systems distribute metadata across multiple servers, possibly even all the I/O servers. We will see examples of both of these approaches in upcoming sections.
Groups have been implementing parallel file systems using this approach for quite some time as well. Two of these systems are the Galley parallel file system and the Parallel Virtual File System (PVFS). An emerging parallel file system, Lustre, also has this type of architecture.
Galley
The Galley parallel file system [78] was developed at Dartmouth College in the mid-1990s (Figure 19.5). It was a research file system designed to investigate file structures, application interfaces, and data transfer ordering for parallel I/O systems. As such many things that we expect from a production file system were never implemented, including kernel modules to allow mounting of Galley file systems and administrative tools.
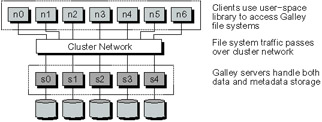
Figure 19.5: Galley Architecture
Galley breaks user's files into subfiles, which are stored on Galley servers. These subfiles have forks that allow for multiple byte streams to be associated with a particular subfile as well and can be used for more complex storage organizations. The client-side code handles placement of file data into appropriate subfiles and forks. Metadata is also stored on all the Galley servers. File names are hashed to find a server on which to store data (a technique also used by the Vesta parallel file system [29], which we will not cover in detail here).
Galley servers understand strided and batch accesses, making the interface quite rich. Many of the application access patterns seen in the CHARISMA study, as well as the patterns seen in the Flash I/O study, could be described with Galley's I/O language as single accesses.
Galley also implements disk-directed I/O [62], a method for organizing how data is moved between client and server. In disk-directed I/O, the server calculates a preferable ordering of data transfer based on predicted disk access costs. This ordering is then used when moving data. The method worked well for many access patterns, although the designers of Galley did see low performance due to network flow control problems in some cases. Later work showed that a more general approach of optimizing for the bottleneck resource can be more effective [97].
While Galley never made it into production, it is an excellent example of the intelligent server approach. Further, many of the ideas embodied in this design, in particular rich I/O request capabilities and more complex file representations, are becoming key components of new parallel file system designs. The Galley source code is available online [41].
PVFS
The Parallel Virtual File System (PVFS) [22] was originally developed at Clemson University by the authors of this chapter, starting in the mid-1990s, and is now a joint project between Clemson University and the Mathematics and Computer Science Division at Argonne National Laboratory. PVFS is designed to be used as a high-performance scratch space for parallel applications.
PVFS file systems are maintained by two types of servers (Figure 19.6). A single metadata server, typically called the "mgr" because of the name of the daemon that runs on this server, maintains metadata for all files. For many workloads and configurations this is not seen as a bottleneck, although it is increasingly becoming one as systems grow in numbers of nodes. Separate I/O servers handle storage of file data. File data is distributed in a round-robin fashion across some set of I/O servers using a user-defined stripe size. Thus a simple algorithm can be used to determine the I/O server holding a particular file region. This simplifies the metadata stored on the metadata server and eliminates the need for metadata updates as files are written. I/O servers write to local file systems, so local disk management is managed by the local file system. Likewise, single disk failures can be tolerated by using a RAID to store local file system data at the I/O server.
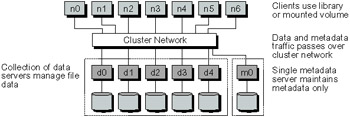
Figure 19.6: PVFS File System Architecture
PVFS uses what the authors term stream-based I/O for data movement. PVFS transfers data using TCP, and the stream-based I/O technique leverages this by predefining a data ordering and eliminating all control messages in the data stream. This approach is able to attain very high utilization of TCP bandwidth; however, in many cases PVFS is disk bound, not network bound. The more adaptive approach given in [97] would likely provide better overall performance, but it was not merged into the PVFS source.
PVFS implements simple strided operations. These can be useful for some patterns; however, a more general approach is necessary for implementing MPI-IO operations. More recently a more flexible (but less concise) system was added for accepting arbitrary lists of I/O regions as single operations [27]. Called List I/O, this was first proposed in [115] and has been shown to be of great benefit to some access patterns. Support is provided in ROMIO for leveraging this; the hint to enable this is described in Section 19.4.4.
PVFS has no locking component. Instead, the metadata server supplies atomic metadata operations, eliminating the need for locking when performing metadata operations. Data operations are guaranteed by I/O servers to be consistent for concurrent writes that do not overlap at the byte granularity, but byte-overlapping concurrent writes result in undefined file state. This approach allows for a relatively simple system with no file system state held at clients, but it precludes client-side caching, which makes for very poor performance in a number of cases, particularly uniprocess workloads where systems from the preceding section would perform well.
Further, PVFS does not implement any form of fault tolerance. RAID can be used to tolerate disk failures, but node failures cause the system to be at least temporarily unusable. High-availability (HA) software is being investigated as a solution to this problem.
PVFS is also missing many of the administrative features that file systems such as GPFS offer. This limitation, combined with the lack of fault tolerance, has dissuaded many sites from using PVFS.
Nevertheless, PVFS has made it into production use at a number of sites around the world, mainly as a large, shared scratch space. PVFS is actively developed and supported, and the source for the file system, now commonly referred to as PVFS1 by the developers, is freely available online [90]. Because of its easy installation and source availability, many I/O researchers have chosen to compare their work to PVFS or to use PVFS as the starting point for their own research. We couldn't be happier that so many people have found this work to be so useful!
PVFS1 is showing its age, and a new version is under development to replace it before typical systems scale beyond its capabilities. We discuss this version, PVFS2, later in the chapter.
Lustre
The Lustre file system [17] is being developed by Cluster File Systems. At the time of writing the Lustre file system is under development, but much documentation and early code is available. The Lustre design benefits heavily from previous work in parallel file systems.
One of the key features of Lustre is the use of modules connected by well-defined APIs. This is seen in at least three areas: networking, allowing for multiple underlying transports; metadata storage, allowing for multiple underlying metadata targets; and object (data) storage, allowing for caching and multiple underlying data storage technologies. In the latter two cases modules can be stacked to implement additional functionality. This provides great potential for the reuse of significant portions of the code when porting to new platforms or adding support for new hardware. Lustre uses the Portals API [19] for request processing and data transfer. Portals is a full-featured, reliable transfer layer designed for use in large-scale systems over multiple underlying network technologies.
Lustre breaks the nodes of the system into three types: clients, Object Storage Targets (OSTs), and Metadata Servers (MDSs). Object Storage Targets store objects, similar to inodes, which hold file data. OSTs perform their own block allocation, simplifying the metadata for a file in a manner similar to previous systems [22]. Objects can be stored on a number of back-end resources attached to OSTs, including using raw file system inodes. Alternatively data can be stored on more traditional SAN resources. In this case OSTs would still be in place, but would handle only authentication and block allocation, allowing data to be transferred directly between clients and SAN storage devices. This is similar to the GPFS approach when the VSD component is not used. This configuration could be convenient for sites with a SAN already in place.
Metadata servers store attributes and directory hierarchy information that is used to build the name space for the file system. Lustre's design calls for multiple MDS nodes in order to help balance the load on these systems. The protocol for metadata operations is explicit and transaction based, allowing for the avoidance of locks. An option is provided for using a node as both a MDS and as an OST.
A snapshot capability is also provided in Lustre, similar to the approach seen in [65], except that snapshotting is performed on object volumes (collections of objects) rather than a collection of blocks.
The designers of Lustre also propose a collaborative caching capability, where caching servers aggregate accesses to particular objects so that a single cache can be shared by multiple applications. This is similar in some ways to the data shipping scheme used in GPFS and distributed caches seen in research parallel file systems [55, 123]. However it is of particular note that Lustre is able to provide this functionality in a modular way.
Lustre relies on a distributed locking system for data coherence. Locks are available at different granularity levels to allow for concurrent access to disjoint file regions. Locks are managed by the OST that stores the object. Metadata operations are also performed by using locks to allow for client-side caching. Lustre adds intent locks for use in metadata operations. These are special locks that are used to perform some type of atomic operation at lock time. While in many instances an explicit operation to perform the intent could be used instead, this approach may lead to fewer opportunities for races between atomic operations by immediately returning a lock that could be used for a subsequent operation.
Lustre implements full POSIX semantics, but this can be turned off on a per file or per file system basis. An interface similar to the List I/O interface described in [115] is proposed as an optimization as well.
Beta versions of Lustre are available, and development is very active. Also released under the GPL license, Lustre could become the next widely used parallel file system for Linux clusters; license compatibility with the PVFS2 project means that the two projects could share components if appropriate APIs were developed.







